DeepSeek-V3.2: A Technical Report on Architectural Efficiency and Agentic Reasoning

Is the gap between open-source and closed-source AI finally closed? 🚀
In this post, we dive deep into DeepSeek-V3.2, the open-source challenger that is officially taking on the giants. For years, proprietary models held a massive lead, but DeepSeek has engineered a way to achieve parity with models like GPT-5-high and Gemini 3.0 Pro.
We break down the technical hurdles the team overcame—from long-text inefficiency to agentic skill gaps—and look at the stunning benchmark results that include Gold Medal level performance in the International Mathematical Olympiad (IMO).
In this post, you’ll learn:
The 3 critical hurdles that were holding open-source AI back. 🚧
How DeepSeek Sparse Attention (DSA) revolutionizes long-context processing.
The "Rocky Montage" of AI: Scalable Reinforcement Learning. 🥊
Why DeepSeek-V3.2 is now a top-tier reasoning engine for math and coding.
If you're interested in the future of open-weight models and the democratization of frontier AI, this is a must-read!
An Explainer Video:
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
https://arxiv.org/pdf/2512.02556
DeepSeek-AI, research@deepseek.com
A Gentle Slide Deck:
Let's Dive In...
1.0 Introduction: Addressing the Open-Source Capability Gap
The field of Large Language Models (LLMs) is undergoing a period of rapid evolution, marked by significant advancements in reasoning and problem-solving capabilities. While this progress is broadly positive, a clear divergence has emerged between the performance trajectories of closed-source proprietary models and their open-source counterparts. The capability gap is widening, with proprietary systems demonstrating increasingly superior performance on complex tasks. This trend highlights the strategic importance of developing open-source models that can not only keep pace but also innovate in core areas of efficiency and advanced cognition.
Three critical deficiencies currently constrain the potential of open-source models. First, architecturally, the widespread reliance on vanilla attention mechanisms creates a severe computational bottleneck for long sequences, hindering both scalable deployment and effective post-training. Second, open-source projects have historically suffered from insufficient computational investment in post-training phases, a crucial step for honing performance on challenging reasoning tasks. Finally, in the domain of AI agents, open-source models exhibit a marked lag in generalization and robust instruction-following compared to leading proprietary systems, limiting their practical effectiveness in interactive environments.
To address these limitations directly, we have developed DeepSeek-V3.2, a model framework designed to harmonize high computational efficiency with superior reasoning and agentic performance. This report details the key breakthroughs that enable this advance: DeepSeek Sparse Attention (DSA), a novel and efficient attention mechanism; a scalable Reinforcement Learning (RL) framework that supports a post-training computational budget exceeding 10% of the pre-training cost; and a large-scale agentic task synthesis pipeline that generates vast amounts of complex, interactive training data.
These innovations collectively empower DeepSeek-V3.2 to narrow the performance gap with frontier models. This report will provide a deep dive into the core architectural advancements, advanced post-training methodologies, and comprehensive performance evaluations that define this new generation of open-source language models.
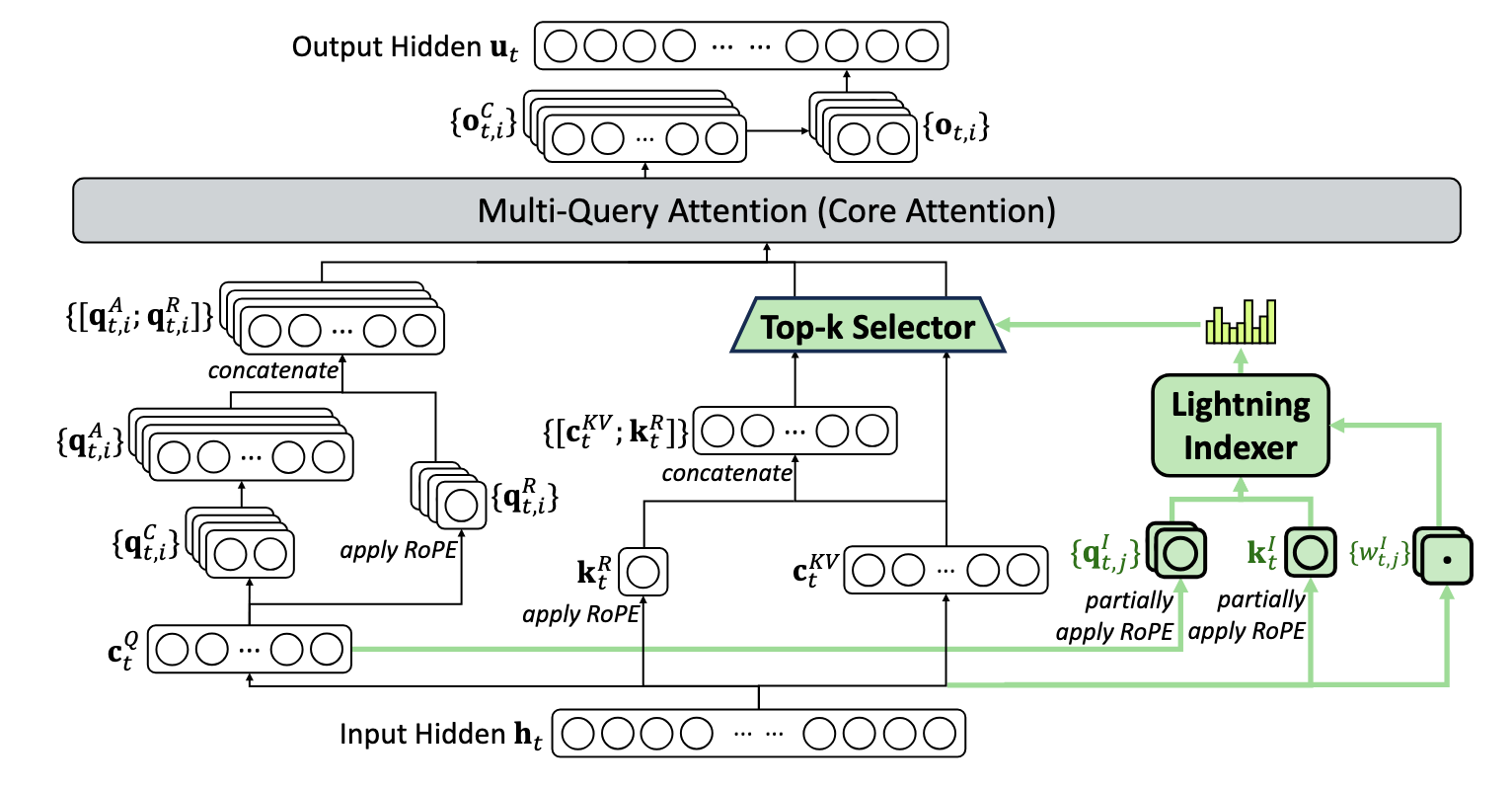
2.0 Architectural Innovation: DeepSeek Sparse Attention (DSA)
Attention mechanisms are the cornerstone of modern transformer architectures, but the quadratic computational complexity of vanilla attention, O(L²), presents a significant bottleneck for processing long contexts. This inefficiency limits both training scalability and inference speed. To overcome this fundamental constraint, DeepSeek-V3.2 introduces DeepSeek Sparse Attention (DSA), a novel architecture that substantially reduces computational complexity while preserving model performance.
The DSA prototype is built upon two primary components that work in tandem to efficiently select the most relevant key-value entries for each query token.
- Lightning Indexer: This highly efficient component computes an index score between a query token and all preceding tokens. It uses a small number of heads and can be implemented in FP8, ensuring its own computational footprint remains minimal despite its O(L²) complexity.
- Fine-grained Token Selection Mechanism: Based on the scores generated by the Lightning Indexer, this mechanism retrieves only the key-value entries corresponding to the top-k index scores. The standard attention mechanism is then applied between the query token and this sparsely selected set of entries.
To incorporate DSA into the existing DeepSeek-V3.1-Terminus base model, a two-stage continued pre-training process was employed using the same 128K long-context data distribution.
- Dense Warm-up Stage: The initial goal was to initialize the Lightning Indexer. In this stage, all main model parameters were frozen, and only the indexer was trained using a KL-divergence loss to align its output distribution with the main model's dense attention scores. This stage ran for 1,000 steps with a learning rate of 10⁻³, processing a total of 2.1 billion tokens.
- Sparse Training Stage: Following the warm-up, the fine-grained token selection mechanism was activated, and all model parameters were optimized to adapt the entire model to the new sparse attention pattern. The Lightning Indexer was optimized separately with its own KL-divergence loss, while the main model was optimized using the standard language modeling loss. This stage selected 2,048 key-value tokens per query and ran for 15,000 steps with a learning rate of 7.3 × 10⁻⁶, processing a total of 943.7 billion tokens.
A critical goal of introducing DSA was to achieve efficiency gains without sacrificing model quality. Comprehensive evaluations comparing the experimental DeepSeek-V3.2-Exp against its predecessor, DeepSeek-V3.1-Terminus, confirm this objective was met. On standard benchmarks and human preference evaluations via ChatbotArena, DeepSeek-V3.2-Exp demonstrated performance on par with its dense-attention counterpart. In independent long-context evaluations, the results were even more promising: on the AA-LCR3 benchmark, DeepSeek-V3.2-Exp scores four points higher, and in the Fiction.liveBench evaluation, it consistently outperforms DeepSeek-V3.1-Terminus across multiple metrics. These findings validate that the sparse attention mechanism was integrated without causing any substantial performance degradation.
DSA fundamentally alters the computational dynamics of the attention mechanism, reducing its core complexity from O(L²) to O(Lk), where k is the number of selected tokens and is significantly smaller than the sequence length L. This theoretical improvement translates into dramatic real-world cost savings and speedups, as benchmarked on H800 GPUs.
- Prefilling: The cost per million tokens for
DeepSeek-V3.2remains nearly flat as sequence length increases, whereas the cost for the dense-attentionDeepSeek-V3.1-Terminusmodel grows quadratically. - Decoding: The cost benefits are even more pronounced during the decoding phase.
DeepSeek-V3.2maintains a low and stable cost per million tokens regardless of the token's position, while the cost forDeepSeek-V3.1-Terminusincreases linearly, becoming prohibitively expensive at longer contexts.
This architectural efficiency is the critical enabler for the computationally intensive post-training pipeline, allowing for an RL budget exceeding 10% of the pre-training cost—a scale previously prohibitive for open-source models.
3.0 Advanced Post-Training and Agentic Capabilities
A powerful foundation model is only the first step; unlocking its advanced reasoning and agentic capabilities requires a sophisticated and computationally intensive post-training pipeline. DeepSeek-V3.2 employs a multi-faceted strategy that combines specialist knowledge distillation, a scalable reinforcement learning framework, and a novel methodology for integrating reasoning into tool-use scenarios.
Specialist Distillation
The post-training process begins by fine-tuning a cohort of specialized models from the same pre-trained base checkpoint. Each specialist is optimized via large-scale RL to excel in one of six distinct domains: mathematics, programming, general logical reasoning, general agentic tasks, agentic coding, and agentic search. Once optimized, these models are used to generate high-quality, domain-specific data, which is then distilled into the final, general-purpose model. This approach ensures the final checkpoint inherits expert-level proficiency across a wide range of disciplines.
Scalable Reinforcement Learning Framework
The core of the RL training is Group Relative Policy Optimization (GRPO), an algorithm designed to optimize the model based on group-wise comparisons of generated responses. To ensure this process remains stable and effective at an unprecedented scale, we implemented four key strategies:
- Unbiased KL Estimate: This technique corrects the gradient of the KL estimator to be unbiased, preventing the model from unstably maximizing the likelihood of low-probability tokens from the reference policy and thereby facilitating stable convergence.
- Off-Policy Sequence Masking: To improve tolerance for off-policy updates, this strategy prevents the model from being destabilized by learning from its own "mistakes" (negative-reward sequences) when those sequences exhibit high divergence from the current policy.
- Keep Routing: For Mixture-of-Experts (MoE) models, this strategy preserves the expert routing paths used during data sampling and enforces those same paths during training. This ensures a stable optimization landscape by preventing abrupt shifts in the active parameter subspace.
- Keep Sampling Mask: To reconcile the use of high-quality sampling strategies (like top-p) with the principles of importance sampling, this method preserves the truncation masks from the old policy and applies them to the new policy during training, ensuring both policies operate on an identical action space.
"Thinking in Tool-Use" Methodology
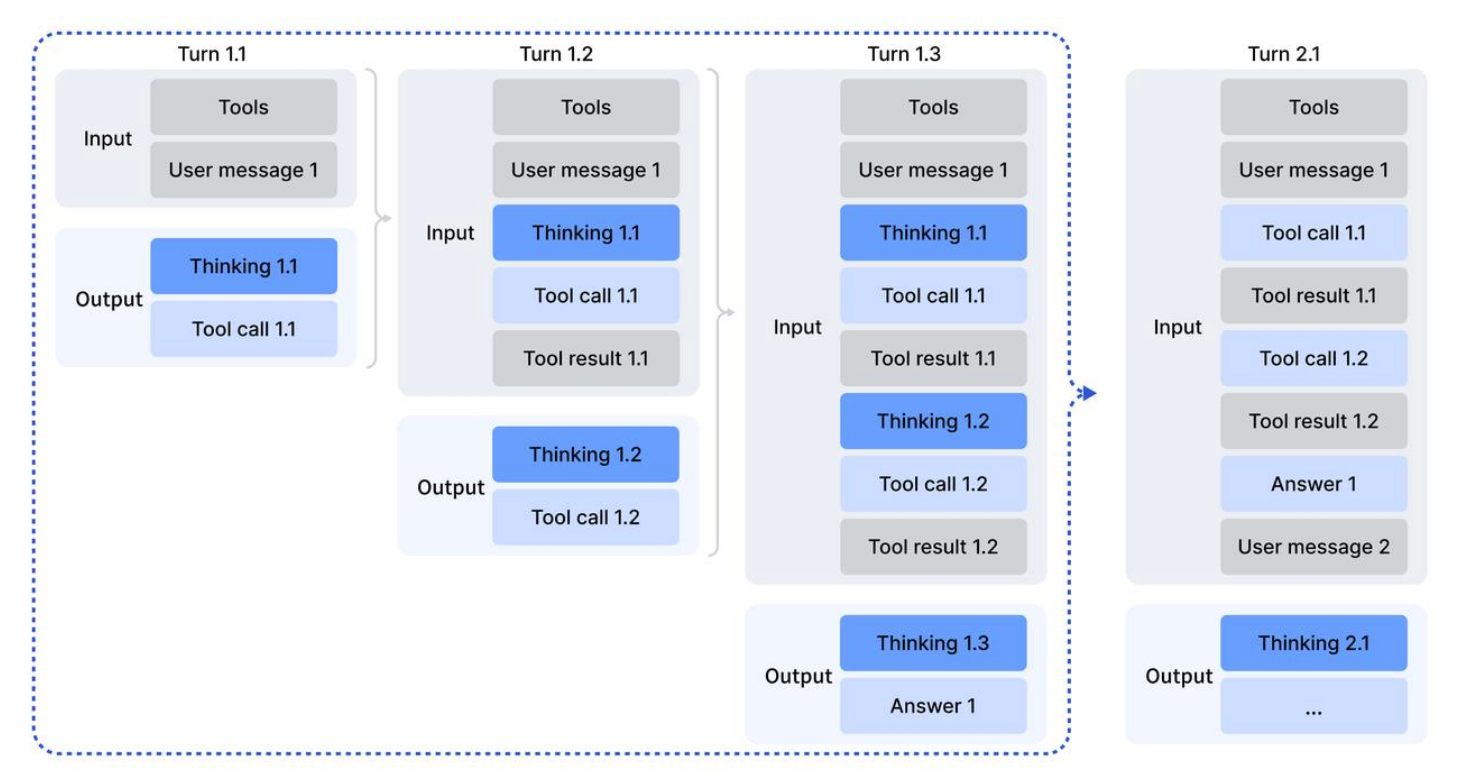
A key innovation in DeepSeek-V3.2 is the integration of chain-of-thought reasoning directly into tool-use workflows. This was achieved through a multi-pronged approach.
First, we developed a Context Management Strategy to mitigate the token inefficiency of traditional reasoning methods. As illustrated in multi-turn interactions, our strategy follows two rules to retain valuable reasoning context:
- Historical reasoning content is discarded only when a new user message is introduced.
- If only tool-related messages (e.g., tool results) are appended, the reasoning content is retained, allowing the model to build upon its previous thoughts without redundant computation.
Next, a "Cold-Start" Mechanism was used to generate initial training data. By designing specific system prompts, we instructed the model to unify its existing (but separate) reasoning and tool-use capabilities into single trajectories. This process generated the initial examples of desired "thinking in tool-use" behavior needed to bootstrap the RL process.
Finally, we deployed a Large-Scale Agentic Task Synthesis pipeline to create a diverse and challenging set of RL training environments. This pipeline automatically generated thousands of tasks across four distinct agent types.
Agent Task Type | Number of Tasks | Environment Type | Prompt Source |
| 50,275 | Real | Synthesized |
| 24,667 | Real | Extracted |
| 5,908 | Real | Extracted |
| 4,417 | Synthesized | Synthesized |
The Search Agent pipeline uses a multi-agent system to generate verifiable question-answer pairs from web corpora, with a hybrid optimization approach for both factual reliability and helpfulness. For the Code Agent, we mined millions of issue-Pull Request (PR) pairs from GitHub to construct large-scale, executable environments for software issue resolution. The General Agent pipeline automatically synthesized 1,827 task-oriented environments that are designed to be hard to solve but easy to verify, with a complex trip-planning scenario serving as a prime example of this design philosophy.
These advanced training methodologies are directly responsible for the model's impressive empirical performance, which we will now examine in detail.
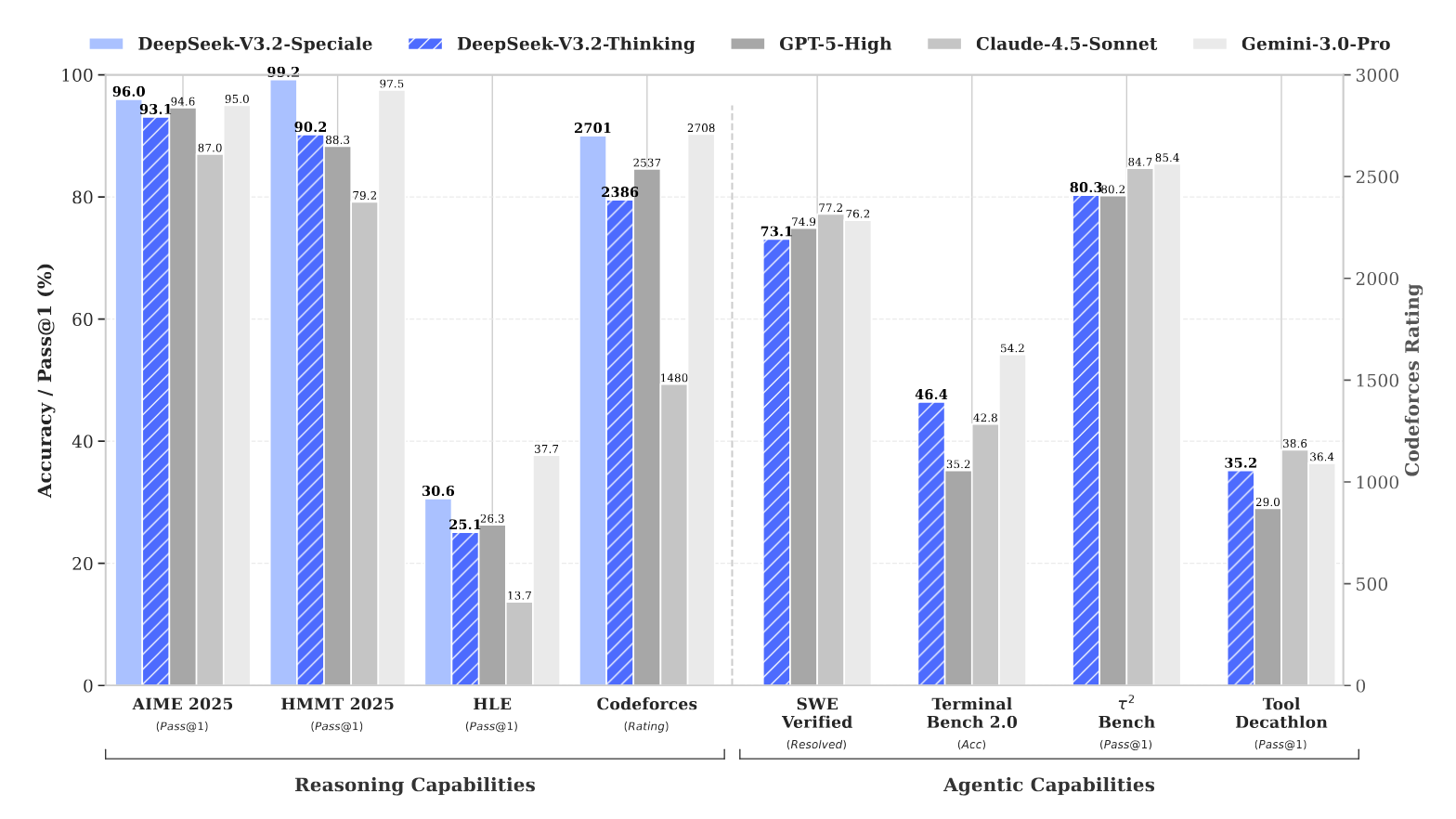
4.0 Performance Evaluation and Competitive Analysis
This section presents a comprehensive performance analysis of the DeepSeek-V3.2 models across a wide range of industry-standard benchmarks. The evaluation covers general reasoning, coding, and agentic tool use, comparing the model against both leading open-source alternatives and premier closed-source competitors. For tool-use benchmarks, all models were evaluated in their respective "thinking" modes.
Main Results of DeepSeek-V3.2
DeepSeek-V3.2 demonstrates highly competitive performance, establishing a new standard for open-source models, particularly in agentic capabilities.
Benchmark (Metric) | Claude-4.5-Sonnet | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 |
English | |||||
MMLU-Pro (EM) | 88.2 | 87.5 | 90.1 | 84.6 | 85.0 |
GPQA Diamond (Pass@1) | 83.4 | 85.7 | 91.9 | 84.5 | 82.4 |
Code | |||||
LiveCodeBench (Pass@1-COT) | 64.0 | 84.5 | 90.7 | 82.6 | 83.3 |
Codeforces (Rating) | 1480 | 2537 | 2708 | - | 2386 |
Math | |||||
AIME 2025 (Pass@1) | 87.0 | 94.6 | 95.0 | 94.5 | 93.1 |
Code Agent | |||||
Terminal Bench 2.0 (Acc) | 42.8 | 35.2 | 54.2 | 35.7 | 46.4 |
Search Agent | |||||
BrowseComp (Pass@1) | 24.1 | 54.9 | - | 60.2* | 51.4 / 67.6* |
ToolUse | |||||
τ2-Bench (Pass@1) | 84.7 | 80.2 | 85.4 | 74.3 | 80.3 |
MCP-Universe (Success Rate) | 46.5 | 47.9 | 50.7 | 35.6 | 45.9 |
MCP-Mark (Pass@1) | 33.3 | 50.9 | 43.1 | 20.4 | 38.0 |
Tool-Decathlon (Pass@1) | 38.6 | 29.0 | 36.4 | 17.6 | 35.2 |
Interpreting these results, DeepSeek-V3.2 achieves performance that is broadly similar to GPT-5-high on reasoning tasks, though it is slightly behind the state-of-the-art Gemini-3.0-Pro. On agentic tasks, however, it substantially outperforms other open-source models. According to the source, these performance gains are a direct result of the increased computational resources allocated to RL training, with consistent improvements correlating to the extended RL budget. For the BrowseComp benchmark, the model's native score is 51.4; however, because over 20% of test cases exceed the 128k context limit, we employed test-time context management strategies that boosted the effective score to 67.6.
Performance of the DeepSeek-V3.2-Speciale Variant
To explore the upper limits of reasoning performance, we developed an experimental variant, DeepSeek-V3.2-Speciale, which was trained with a reduced penalty for generation length. This variant pushes the boundaries of what is possible with open models, achieving state-of-the-art results on several key benchmarks.
Benchmark | DeepSeek-V3.2-Speciale | GPT-5 High | Gemini-3.0 Pro |
AIME 2025 (Pass@1) | 96.0 (23k) | 94.6 (13k) | 95.0 (15k) |
HMMT Feb 2025 (Pass@1) | 99.2 (27k) | 88.3 (16k) | 97.5 (16k) |
HMMT Nov 2025 (Pass@1) | 94.4 (25k) | 89.2 (20k) | 93.3 (15k) |
IMOAnswerBench (Pass@1) | 84.5 (45k) | 76.0 (31k) | 83.3 (18k) |
LiveCodeBench (Pass@1-COT) | 88.7 (27k) | 84.5 (13k) | 90.7 (13k) |
As the table indicates, DeepSeek-V3.2-Speciale surpasses Gemini-3.0-Pro on multiple challenging mathematics benchmarks. This superior accuracy, however, comes at the cost of significantly lower token efficiency, as it often generates much longer reasoning chains (e.g., 45k tokens on IMOAnswerBench vs. 18k for Gemini-3.0-Pro), highlighting a critical trade-off between performance and computational cost.
The exceptional capabilities of this variant are further validated by its performance in top-tier programming and mathematics competitions, where it achieved gold-medal-level results without task-specific training.
- IMO 2025: 35/42 (Gold)
- CMO 2025: 102/126 (Gold)
- IOI 2025: 492/600 (Gold)
- ICPC World Final 2025: 10/12 Problems Solved (Gold)
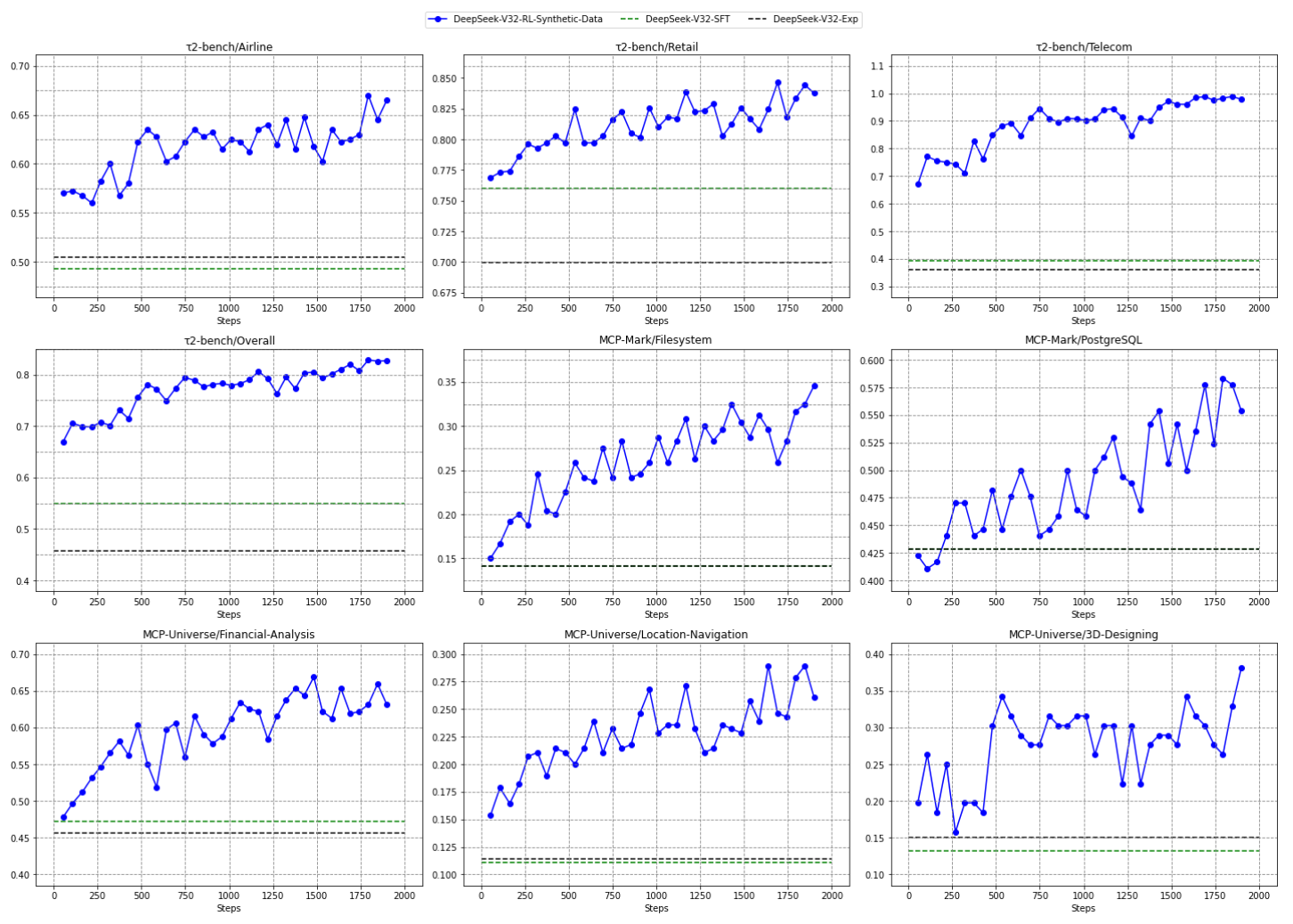
Effectiveness of Synthesized Agentic Tasks
Ablation studies confirm the high value of our large-scale agentic task synthesis pipeline. When evaluated on a random sample of these tasks, even frontier closed-source models like GPT-5-Thinking achieved only 62% accuracy, demonstrating that the synthesized data is sufficiently challenging to drive meaningful learning. Furthermore, when the base model was trained with RL exclusively on this synthetic data, it showed substantial performance improvements on out-of-domain, real-world benchmarks like τ2-Bench and MCP-Universe. This confirms that the skills learned on the synthetic tasks generalize effectively to novel agentic scenarios.
The practical application of these agentic skills, especially in long-running tasks, introduces new challenges related to context management, which we will now explore.
5.0 Practical Considerations for Long-Context Agentic Workflows
One of the primary challenges in complex, multi-turn agentic workflows is the limitation of the context window. Even with a generous 128k token capacity, tasks involving extensive web searches or iterative code execution can quickly exhaust the available context, as seen with the BrowseComp benchmark where over 20% of test cases exceed this limit. This section examines practical, test-time strategies for extending a model's effective token budget to overcome this bottleneck.
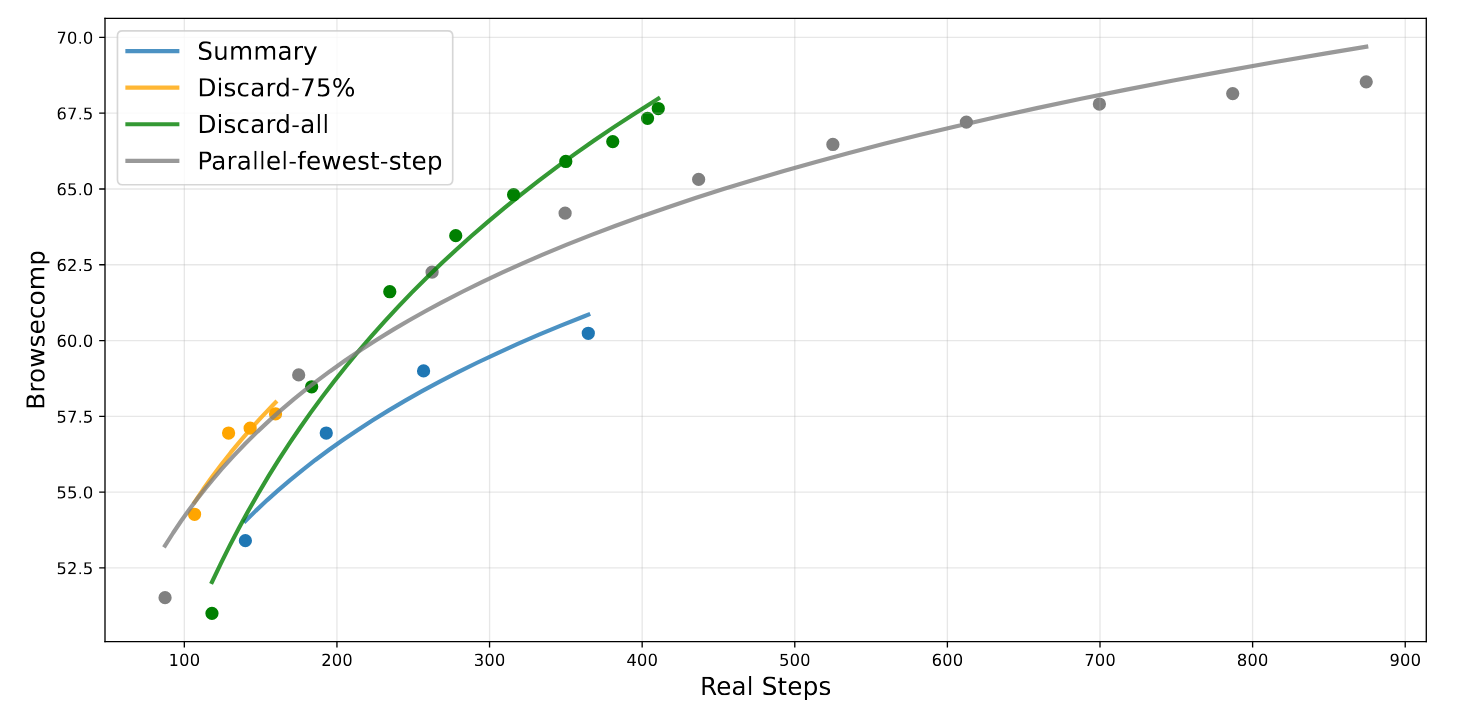
To address scenarios where an agentic workflow exceeds the context window, we evaluated three distinct context management strategies.
- Summary: This strategy summarizes the overflowing portion of the trajectory and re-initiates the workflow with the summary as context.
- Discard-75%: This method discards the first 75% of the tool call history in the context to free up space for subsequent steps.
- Discard-all: This is the simplest strategy, resetting the context by discarding all previous tool call history, similar to starting a new conversation.
On the BrowseComp benchmark, all three strategies led to significant performance gains by allowing the model to perform more execution steps. The Summary strategy boosted performance to 60.2. However, the most effective approach was Discard-all. Despite its simplicity, it achieved a final score of 67.6, a result comparable to parallel scaling (running multiple independent trajectories and selecting the best one) but with substantially greater computational efficiency.
These findings demonstrate that intelligent context management can serially scale a model's problem-solving capacity at test time, providing a powerful and efficient alternative to parallel scaling. This bridges the gap between a model's fixed context length and the unbounded demands of complex agentic tasks.
6.0 Conclusion, Limitations, and Future Work
In this work, we have presented DeepSeek-V3.2, a framework that bridges the gap between architectural efficiency and agentic reasoning by leveraging DeepSeek Sparse Attention (DSA)'s computational savings to fund an unprecedentedly large RL budget. This architectural efficiency enabled us to invest heavily in a robust post-training pipeline, culminating in reasoning performance comparable to leading proprietary models. Furthermore, our novel large-scale agentic task synthesis pipeline has significantly enhanced the model's tool-use proficiency, unlocking new potential for creating robust AI agents with open models. The gold-medal achievements of our high-compute variant, DeepSeek-V3.2-Speciale, in international Olympiads for both mathematics and informatics set a new milestone for open-source AI.
Despite these significant achievements, we acknowledge several limitations when comparing DeepSeek-V3.2 to frontier closed-source models.
- Breadth of World Knowledge: Due to a lower total investment in pre-training FLOPs, the model's breadth of world knowledge still lags behind that of leading proprietary systems.
- Token Efficiency: The model often requires longer generation trajectories and more tokens to achieve the same quality of output as its most efficient closed-source peers.
- Complex Task Performance: While highly capable, performance on the most complex, multifaceted tasks remains inferior to the absolute frontier of closed-source models.
fin...