Delta Belief-RL: Revolutionizing Long-Horizon Interaction through Intrinsic Credit Assignment
An Explainer Video:
Intrinsic Credit Assignment for Long Horizon Interaction
https://arxiv.org/pdf/2602.12342
Ilze Amanda Auzina, Joschka Struber, Sergio Hernandez-Gutierrez, Shashwat Goel, Ameya Prabhu, Matthias Bethge
A Gentle Slide Deck:
Let's Dive In...
1. The Challenge of Uncertainty in Multi-Turn Agents
In the current landscape of artificial intelligence, large-scale agents have demonstrated remarkable proficiency in solving fully specified, single-turn tasks. However, a significant gap remains in their ability to navigate under-specified or open-ended problems—scenarios that demand active information-seeking and long-horizon interactions to resolve latent uncertainties. Whether an agent is navigating the hypothesis space in a scientific problem or attempting to discern a user’s nuanced preferences, the capacity to ask the right questions and efficiently narrow a posterior distribution is a strategic imperative for the next generation of agentic AI.
Traditional Reinforcement Learning (RL) paradigms struggle in these settings. Current approaches often rely on sparse, outcome-based rewards, where a signal is only provided at the conclusion of a long trajectory. This lack of granular credit assignment makes it difficult for a model to distinguish which specific intermediate actions—such as a particularly insightful query—contributed to success. Furthermore, the standard solution of training separate critic models to estimate value functions is prohibitively expensive and computationally intensive when scaled to modern large-scale language models. To bridge this gap, we introduce Delta Belief-RL, a framework that utilizes the agent's own internal token probability distribution—its "internal world view"—as a dense, intrinsic training signal. By monitoring how an agent's beliefs shift in response to environment feedback, we provide precise credit assignment that transforms the conceptual problem of sparse rewards into a mechanism of continuous, turn-level internal updates.
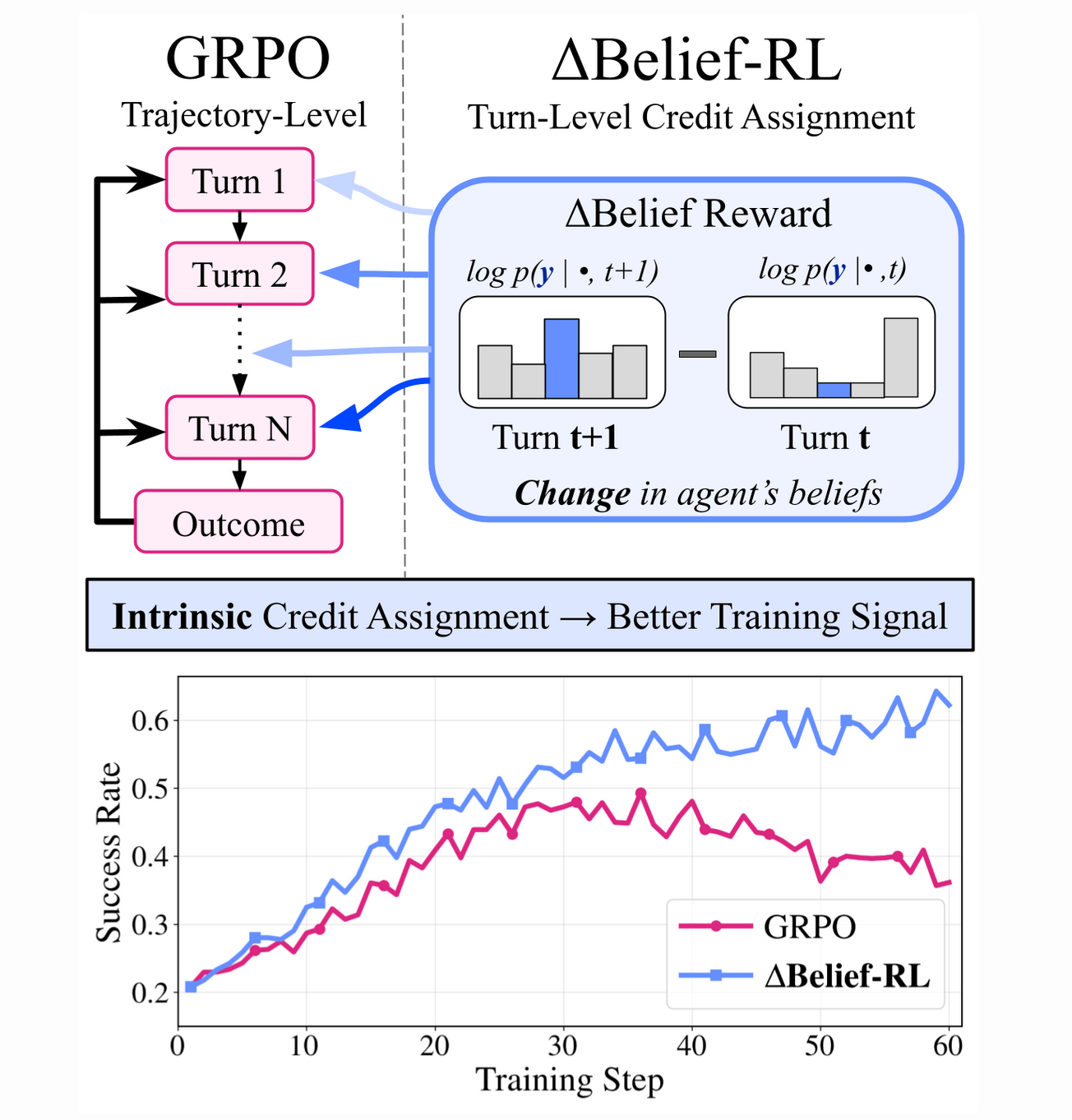
2. Formalizing Delta Belief: Internal Probabilities as Reward Signals
The Delta Belief-RL framework leverages the strategic insight that an agent's underlying token probability distribution is a powerful proxy for its "internal belief." Rather than relying on an external judge or a costly reward model, we can quantify progress by observing how much a specific interaction resolves the agent's uncertainty regarding a target concept.
The mathematical core of the Delta Belief reward is defined by the following components:
- Delta Belief Elicitation (b_t): At any turn t, we calculate the Delta belief as the probability the policy theta assigns to the target concept y, conditioned on the history h_t and a specific elicitation prompt e_i. In our implementation for the "20 Questions" domain, we utilize the prompt e_i =
"Is the secret ".
b_t = p_theta(y mid h_t, e_i) - The Delta Belief Reward Formula: The intrinsic reward is derived from the shift in belief across sequential steps, expressed as a log-ratio for numerical stability and to prevent floating-point underflow: {Delta Belief}_t = log b_t - log b_{t-1}
For robust training, we apply a Rectified Linear Unit (ReLU) to the intrinsic signal, clipping it at zero. This ensures that agents are reinforced only for confidence gains that resolve uncertainty. From a scientist's perspective, this prevents the policy from being penalized for the temporary, necessary fluctuations in confidence that naturally occur during legitimate exploration of a complex hypothesis space.
Key Differentiators of the Delta Belief Reward
- Independence from External Critics: Utilizes the agent's own internal state, eliminating the need for separate process reward models (PRMs) or expensive, separately trained value functions.
- Dense Signal for Long Horizons: Provides a turn-level reward that enables sample-efficient convergence in multi-turn environments.
- Computational Scalability: Leverages existing log-probability outputs of the LLM, making it architecturally compatible with diverse large-scale models.
By transforming the internal probability distribution into an active guiding force, Delta Belief-RL provides a validated measurement of interactive progress.
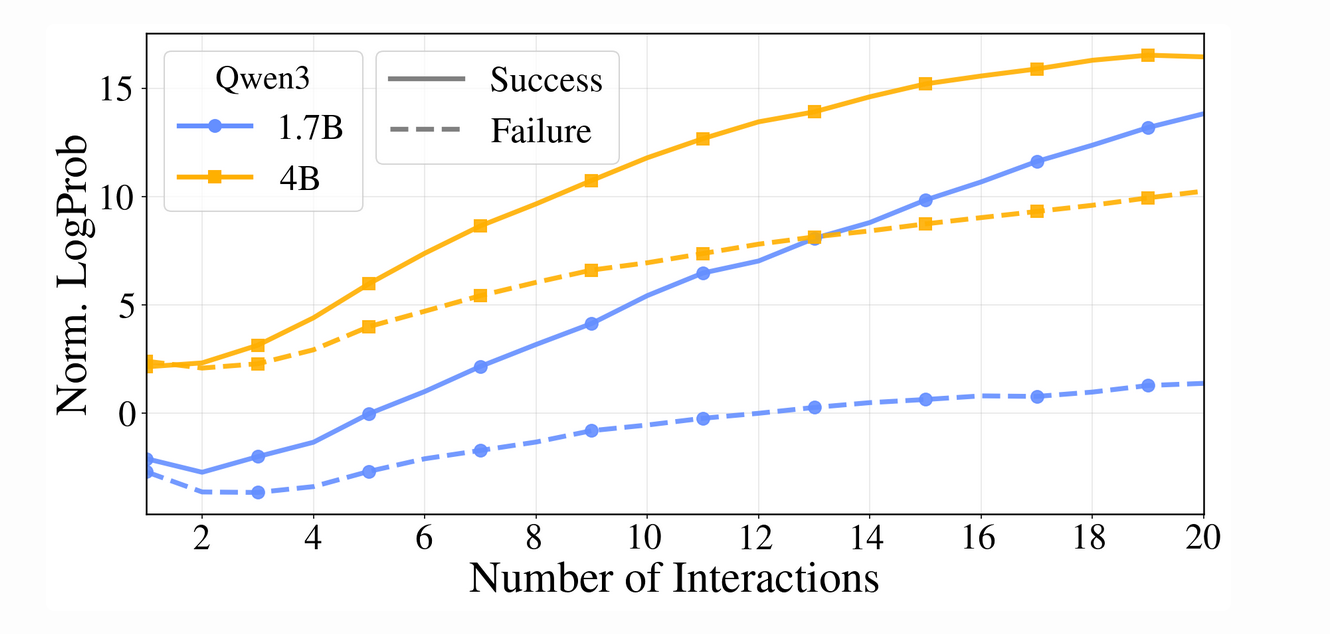
3. Empirical Validation of the Intrinsic Signal
Before implementing a full RL training loop, it is critical to validate whether internal beliefs accurately reflect interactive progress. Analysis of off-policy trajectories confirms that beliefs about the ground-truth concept steadily increase over time, and the rate of this growth is strongly predictive of the final trajectory outcome.
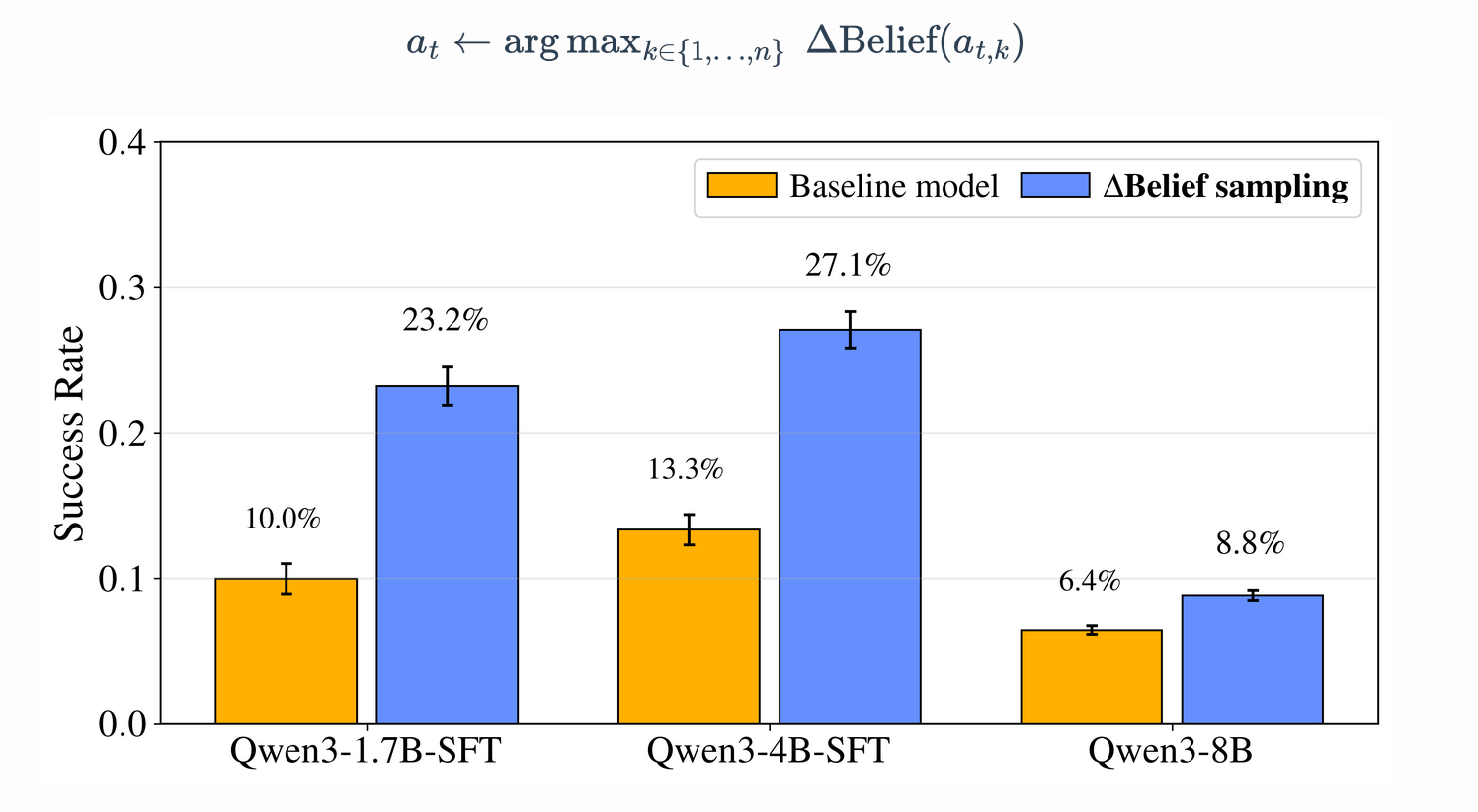
To confirm the utility of this signal, we conducted an oracle-access intervention using "Best-of-8" sampling. In this setup, the model samples eight candidate actions at each turn and selects the one that maximizes the immediate {Delta Belief}_t. This requires ground-truth knowledge for the selection process during inference, serving as a validation of the signal's potential. This "look-ahead" heuristic led to significant performance spikes across all scales:
Model Scale | SFT Baseline Success Rate | Delta Belief-Guided Sampling (Best-of-8) |
1.7B | 9.97% | ~25% |
4B | 13.34% | ~33% |
8B | ~16% | ~40% |
This validated signal demonstrates that optimizing for belief shifts is a viable proxy for task success, allowing for its integration into a formal Turn-wise GRPO training loop.
4. Training Methodology: Turn-wise GRPO and Reward Engineering
The core strategic shift in Delta Belief-RL is the transition from trajectory-level feedback to turn-level credit assignment via "Turn-wise GRPO." Standard Group Relative Policy Optimization (GRPO) typically applies a single, coarse reward across an entire sequence. In contrast, our method computes relative advantages at the turn level. For a group of G trajectories, the group-relative turn-wise advantage hat{A}^i_t is computed and then assigned to all tokens generated within that specific turn, providing the policy with granular feedback on the efficacy of individual inquiries.
The per-turn reward r_t is engineered as a composite signal:
- Trajectory Outcome (r_{eog}): The verifiable end-of-game reward.
- Intrinsic Exploration (lambda max({Delta Belief}_t, 0)): The scaled intrinsic signal that rewards information gain.
- Efficiency Penalty (r_p): A penalty term comprising r_{traj} (trajectory length), r_{rep} (repetitions), and r_{inv} (invalid formatting).
Evaluations of reward normalization revealed that ReLU positive-only shaping provides the most stable training dynamics. Other methods, such as Tanh or Exponential Moving Averages (EMA), often introduced negative updates that dominated the verifiable reward or compressed the signal so much that informative variations were lost. By focusing on positive delta belief gains, the training regimen consistently converges on more interaction-efficient policies.
5. Performance Results and Scaling Dynamics
The resulting CIA (Curious Information-seeking Agent) models demonstrate a new state-of-the-art in active inquiry. In the "20 Questions" test set, CIA models significantly outperformed standard baselines and much larger models.
Method | Model Size | Mean Success Rate | Pass@8 |
SFT Baseline | 1.7B | 9.97% | 32.03% |
StarPO | 1.7B | 16.54% | 45.73% |
CIA (Ours) | 1.7B | 24.80% | 53.10% |
DeepSeek-V3.2 | 670B | 14.35% | 47.34% |
CIA (Ours) | 4B | 33.72% | 63.97% |
These results highlight a "Specialization Over Scale" dynamic: our 1.7B CIA model outperforms the 670B DeepSeek-V3.2 by 10.45% absolute, while the 4B CIA model shows a 19.37% absolute advantage. This proves that strategic RL can overcome the limitations of raw parameter count.
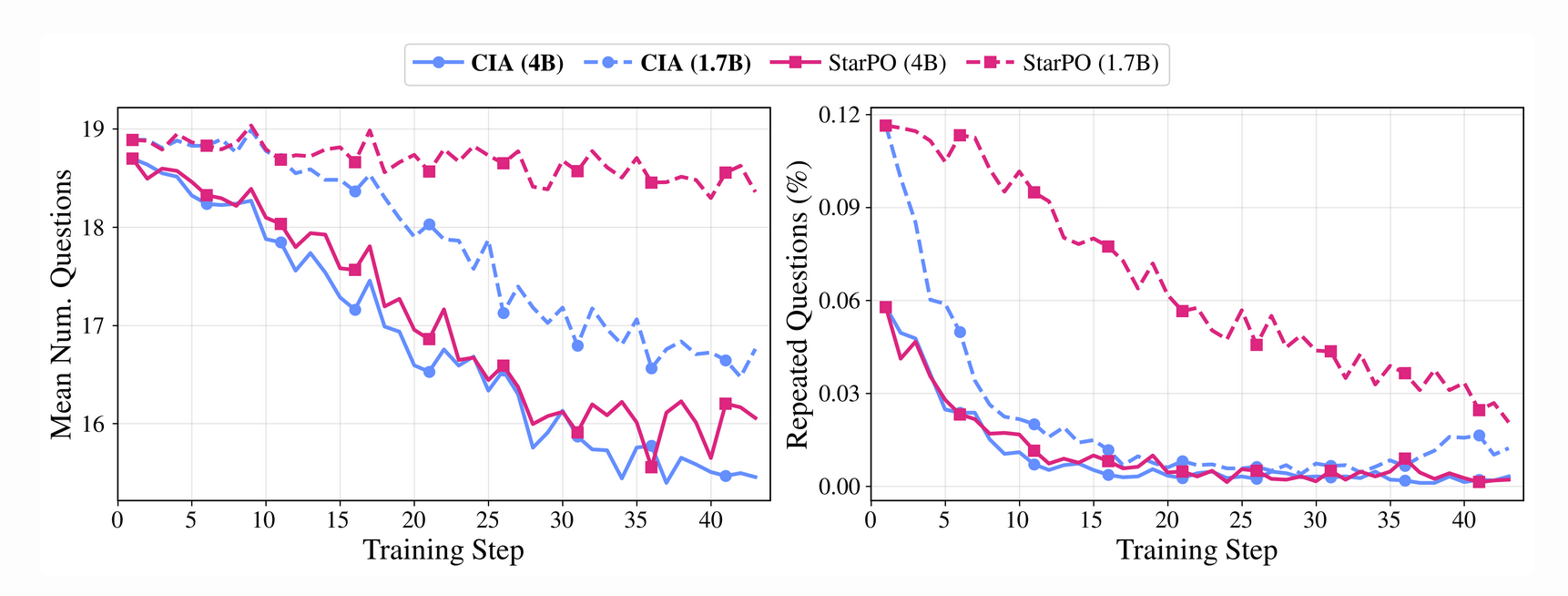
Furthermore, CIA models exhibit remarkable Test-Time Interaction Scaling. While trained on a 20-turn horizon, performance continues to improve as the interaction budget extends to 50 turns. At the 4B scale, the absolute success rate gain from 20 to 50 turns was +26% for CIA, double the gain of StarPO (+13%). This demonstrates a generalization of the information-seeking strategy that does not break when the budget is 2.5x the training horizon. CIA also reduces the total number of turns required and suppresses redundant queries more rapidly than standard GRPO.
6. Robustness and Cross-Domain Generalization
To ensure the agent’s capabilities are task-agnostic and robust against overfitting to training simulators, we evaluated the CIA models on out-of-distribution (OOD) benchmarks.
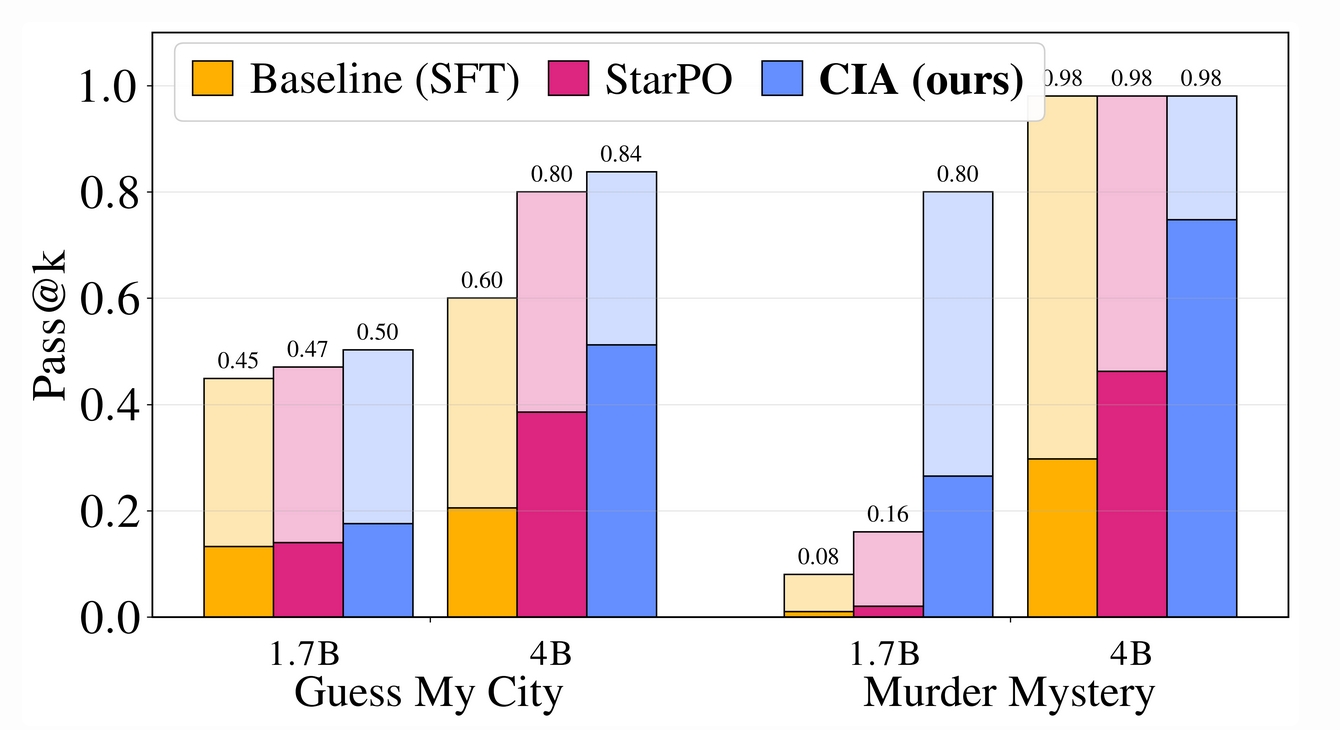
- Guess My City: CIA adopts a sophisticated "top-down" strategy, prioritizing abstract regional characteristics and cultural landmarks to narrow the search space, whereas baselines relied on a brute-force approach of naming specific cities.
- Murder Mystery: CIA achieved its most significant gains here, leading StarPO by up to 28.5% in Pass@1. Qualitative analysis of rollouts shows the agent performing granular deduction—identifying specific clues like a "missing ledger" or a "coiled fish" watermark—rather than making undirected guesses.
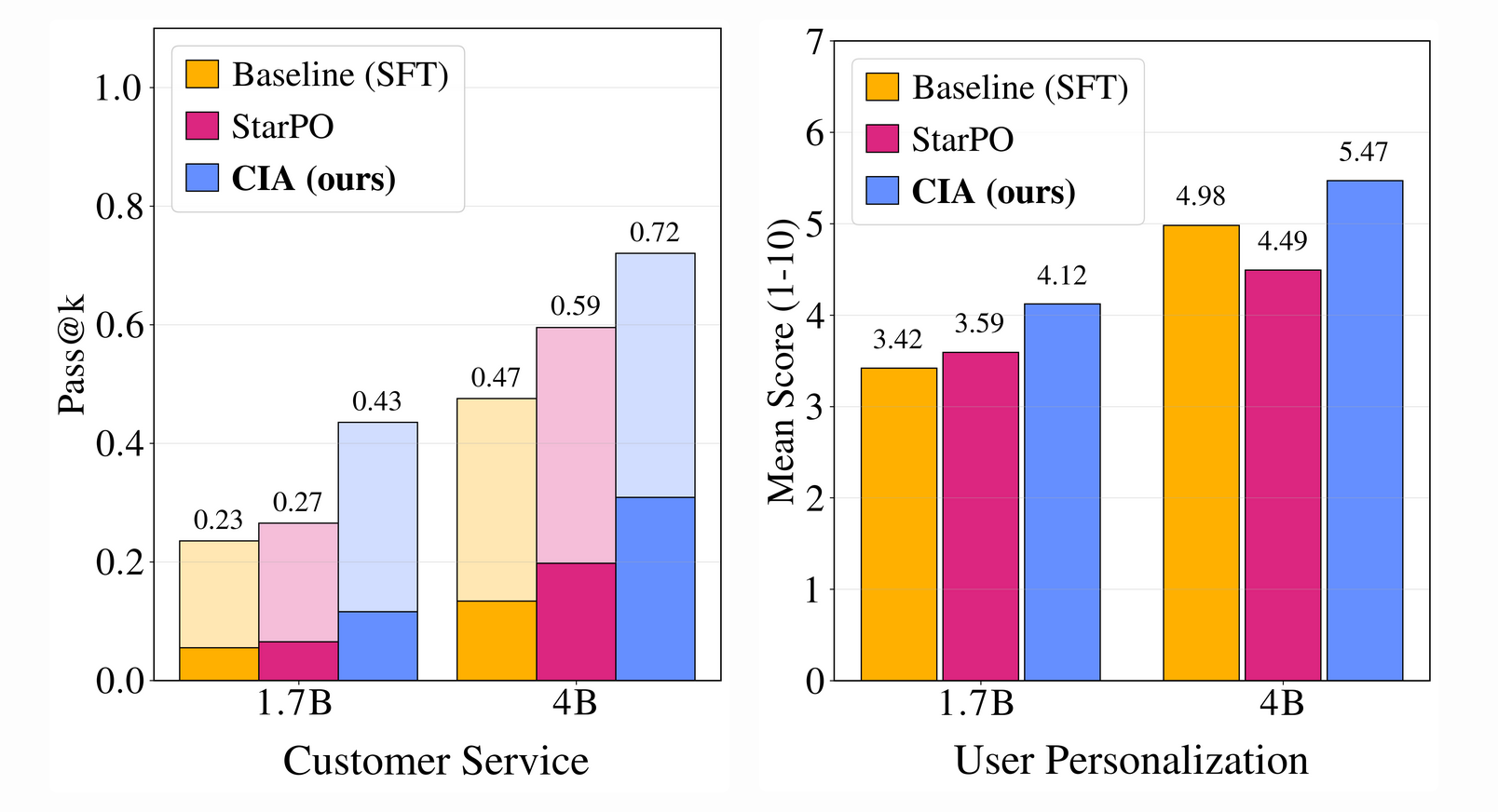
- Customer Service & User Personalization: CIA showed 11-15% improvements over the state-of-the-art. In diagnostic questioning, CIA demonstrated "dynamic adjustment," tailoring inquiries based on user feedback, contrasting sharply with the SFT agent's exhaustive but undirected lists of questions.
Ablation studies using stronger user simulators (e.g., Qwen-235B, DeepSeek, Gemini) confirmed that these capabilities are robust across different LLM backends and not dependent on specific artifacts of the training environment.
7. Strategic Conclusion and Future Directions
The development of Delta Belief-RL proves that an agent’s internal belief shifts can effectively guide learning in long-horizon tasks without the need for external critics. By deriving dense credit assignment from the model’s internal posterior distribution, we enable more sample-efficient convergence and superior information-seeking behavior.
Critical takeaways for the AI research community include:
- Scalability of Intrinsic Signals: Delta Belief provides a dense, low-cost training signal that facilitates complex credit assignment without the overhead of additional reward models.
- Specialization Over Scale: CIA models at the 1.7B-4B scale outperform 670B web-scale models in active inquiry, establishing that targeted RL is essential for agentic reasoning.
- The Path to Self-Training: The internalization of progress suggests a future where agents can train in isolation through refined belief calibration and internal world modeling.
Delta Belief-RL is agnostic to the underlying RL algorithm and architecture, providing a versatile framework for advancing agentic AI across diverse and uncertain domains.
fin...