Dr. Zero: Self-Evolving Search Agents without Training Data

Dr. Zero: Self-Evolving Search Agents Without Training Data
https://arxiv.org/pdf/2601.07055
Zhenrui Yue, Kartikeya Upasani, Xianjun Yang, Suyu Ge, Shaoliang Nie1, Yuning Mao, Zhe Liu, Dong Wang
Meta Superintelligence Labs, University of Illinois Urbana-Champaign
🚀 Dive into the Future of Self-Evolving AI Agents!
In this post, we explore the innovative research paper "Dr. Zero: Self-Evolving Search Agents Without Training Data" authored by experts from Meta Superintelligence Labs and the University of Illinois Urbana-Champaign.
Discover how self-evolving agents can learn complex reasoning tasks without the need for labeled training data, effectively tackling the current data bottleneck in AI.
Join us as we break down the unique architecture of Dr. Zero, highlighting the roles of the Proposer and Solver agents and the ingenious methods they use to evolve their capabilities. You'll learn about the challenges of traditional reinforcement learning in search and how innovative strategies like Hop-Grouped Relative Policy Optimization (HRPO) can lead to significant improvements in efficiency and performance.
📌 What You'll Learn:
• 🔍 The concept of self-evolution in AI agents without training data
• 🧠 The roles of Proposer and Solver in the Dr. Zero architecture
• 📈 How HRPO optimizes learning and reduces computational costs
• 🔄 The significance of "hops" in measuring question complexity
• 🏆 Results showing competitiveness against supervised learning baselines
• 🔮 Future implications for self-taught AI systems
An Explainer Video:
A Gentle Slide Deck:
Let's Dive In...
1.0 Introduction: The Challenge of Data Scarcity in Advanced AI
A central challenge in modern artificial intelligence development is the increasing difficulty and expense of acquiring high-quality, human-curated training data. As AI models grow in complexity and are tasked with more sophisticated reasoning, this data bottleneck becomes a significant barrier to progress. The reliance on vast, annotated datasets is not only costly but also limits the scalability and adaptability of advanced AI systems.
To address this fundamental constraint, "data-free self-evolution" has emerged as a promising paradigm. The core concept is to empower large language models (LLMs) to improve their own capabilities by autonomously generating and solving complex problems. This approach seeks to create a self-sustaining cycle of learning, thereby reducing or eliminating the dependency on external, human-provided data.
However, applying this paradigm to multi-turn search agents—which must perform complex reasoning and interact with external tools like search engines—presents unique and significant hurdles. Existing self-evolution methods have demonstrated two critical limitations in this context:
- Limited Question Diversity: In open-domain settings, current methods exhibit a strong bias toward generating simple, one-hop questions. This lack of diversity fails to produce a sufficiently challenging curriculum, hindering the agent's ability to develop advanced, multi-step reasoning skills.
- Prohibitive Computational Overhead: The reliance on nested sampling in algorithms like Group Relative Policy Optimization (GRPO) becomes computationally prohibitive when training search agents, as the high latency of multi-step tool interactions creates an exponential increase in training time.
To solve these specific problems, we introduce Dr. Zero, a novel framework designed to enable search agents to effectively self-evolve without any training data. At its core, Dr. Zero establishes a symbiotic feedback loop between two co-evolving agents—a proposer that generates questions and a solver that answers them. This research proves that complex reasoning and search capabilities can emerge solely through a carefully architected self-evolution process, allowing data-free agents to match or even surpass their fully supervised counterparts.
This document will deconstruct the architecture of the Dr. Zero framework, analyze its core technical innovations, and present the empirical evidence that validates its performance.
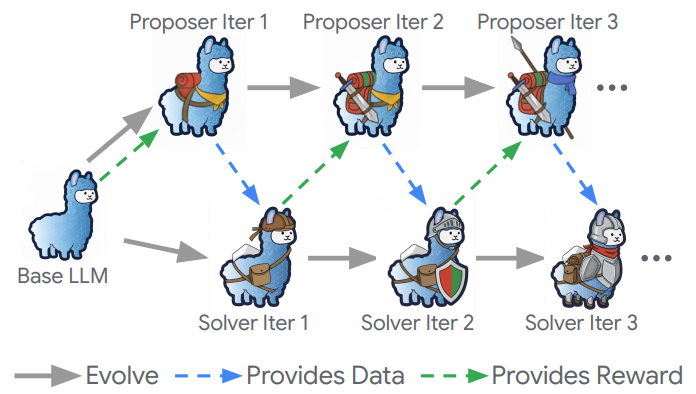
2.0 The Dr. Zero Framework: An Automated Co-Evolutionary Curriculum
The strategic importance of the Dr. Zero architecture lies in its ability to function as a self-contained ecosystem for learning. It automatically generates its own training curriculum, completely eliminating the need for external supervision or human-annotated data. This is achieved through a dynamic interplay between two core components that are initialized from the same base LLM.
The Proposer-Solver Architecture
The framework is built upon a decoupled design where two distinct agents, a Proposer and a Solver, co-evolve to enhance each other's capabilities. This decoupled design is a deliberate architectural choice that prevents the model from simply memorizing its own outputs—a common failure mode in unified self-play systems—thereby promoting better generalization at test-time.
- The Proposer (\pi_\theta): This agent's primary function is to generate diverse and challenging question-answer (QA) pairs. It leverages an external search engine to gather information and construct multi-hop questions that require complex reasoning to solve. Its goal is to create tasks that are difficult but still verifiable.
- The Solver (\pi_\phi): This agent's function is to learn how to answer the questions generated by the Proposer. It develops its capabilities by performing multi-turn reasoning and interacting with the search engine to find the correct answer.
The Self-Evolution Feedback Loop
The Proposer and Solver exist in a dynamic, symbiotic relationship. The improved performance of one agent directly incentivizes the other to become more sophisticated. As the Solver becomes more adept at answering questions, the Proposer is penalized for generating trivial tasks and is rewarded for creating more complex queries. This feedback loop creates a continuously evolving and automated curriculum, pushing both agents to refine their reasoning and search abilities without any external guidance. The Solver's progress forces the Proposer to explore more challenging problem spaces, which in turn provides the Solver with the high-quality data it needs to continue improving.
The framework's success hinges on several key technical innovations in its training and optimization methods, which make this co-evolutionary process both effective and computationally efficient.
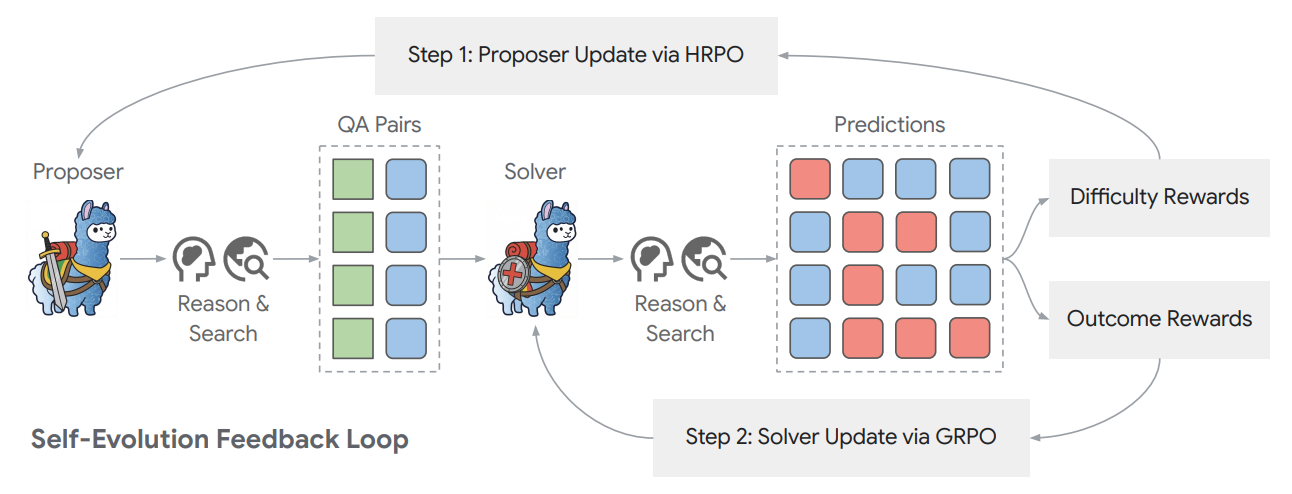
3.0 Core Technical Innovations
Dr. Zero's effectiveness is rooted in two primary innovations: a novel reward mechanism that guides the Proposer to generate high-quality training data, and a highly efficient optimization algorithm that makes the self-evolution process computationally feasible for complex search agents.
Difficulty-Guided Reward Mechanism
The Proposer's reward function is carefully designed to achieve a dual objective: to encourage the generation of questions that are both verifiable (solvable by the current Solver) and difficult (not trivial). This balance ensures the creation of an effective learning curriculum.
The reward is calculated based on the Solver's pass rate over n sampled attempts to answer a given question. As defined in the source research, the reward is maximized when only a fraction of solver attempts succeed (specifically, when k=1 in the formula I(0 < k < n) (n-k)/(n-1)), penalizing instances where the solver either fails completely (k=0) or succeeds trivially on every attempt (k=n). This reward structure is engineered to keep the solver within a "zone of proximal development," ensuring the training curriculum is neither trivially easy nor insurmountably difficult, which is the optimal condition for robust learning.
Furthermore, a format reward (rf) is included to ensure the Proposer generates structurally valid and well-formed QA pairs. This format reward is crucial for preventing "reward hacking," where the proposer might otherwise learn to generate structurally malformed but technically "difficult" outputs, thereby ensuring the synthesized data is high-quality and usable for solver training.
Hop-Grouped Relative Policy Optimization (HRPO)
To solve the prohibitive computational bottleneck created by nested sampling in standard GRPO, Dr. Zero introduces Hop-Grouped Relative Policy Optimization (HRPO). Standard methods are computationally prohibitive for agents that perform complex tool interactions, but HRPO achieves superior efficiency through a new group-based approach.
- Structural Clustering: HRPO begins by clustering the questions generated by the Proposer based on their "cross-hop complexity." This means questions are grouped by the number of search and reasoning steps required to arrive at the answer (e.g., 1-hop, 2-hop, 3-hop questions).
- Group-Level Advantage Estimation: Instead of calculating advantage for a single prompt by sampling multiple responses, HRPO computes a robust, low-variance advantage estimate by normalizing rewards within these structurally similar groups. By normalizing rewards within structurally similar groups, HRPO computes a robust, low-variance advantage estimate. This provides a more stable baseline for policy updates and mitigates the high variance in policy gradients that often leads to training instability in traditional reinforcement learning.
- Computational Savings: This approach completely avoids the need for nested sampling by generating only a single question per prompt. As a result, HRPO reduces the computational costs of training by approximately 75% compared to GRPO, making data-free self-evolution practical for complex search agents.
Solver Training Process
The Solver is trained using the QA data generated by the Proposer. Its training relies on the standard Group Relative Policy Optimization (GRPO) algorithm, guided by a simple, outcome-based reward. This reward function evaluates the correctness of the Solver's final predictions against the ground-truth answers synthesized by the Proposer. This straightforward, outcome-based reward focuses the solver's optimization process entirely on the task of finding correct solutions, relying on the proposer to manage the complexity and quality of the training curriculum.
These methodological advancements enable a robust and efficient self-evolution cycle, and their effectiveness is validated through comprehensive empirical analysis.
4.0 Empirical Validation and Performance Analysis
The goal of the experimental evaluation was to comprehensively assess Dr. Zero's performance against both supervised and data-free baselines across a range of challenging open-domain question-answering benchmarks. The experiments utilized Qwen2.5 3B and 7B Instruct models as the base LLMs.
Performance Against Supervised Baselines
Dr. Zero demonstrates a remarkable ability to compete with and often exceed the performance of fully supervised methods, despite using zero human-annotated training data. As detailed in Table 1, the results highlight several key achievements:
- The Dr. Zero 3B model significantly outperforms the supervised Search-R1 baseline across all single-hop benchmarks, achieving improvements of 22.9% on NQ (0.397 vs 0.323), 6.5% on TriviaQA (0.572 vs 0.537), and 18.4% on PopQA (0.431 vs 0.364).
- The 7B variant achieves competitive performance on complex multi-hop benchmarks, performing at roughly 90% of the Search-R1 baseline and even surpassing it on the challenging 2WikiMQA dataset (0.347 vs 0.326).
These results are a powerful validation that complex search and reasoning skills can be effectively cultivated through autonomous self-evolution, challenging the long-held assumption that such capabilities require extensive human supervision.
Superiority Over Data-Free Alternatives
When compared to existing data-free methods like SQLM* and R-Zero*, Dr. Zero establishes a new standard for performance. According to the results in Table 2, Dr. Zero achieves average performance gains of 39.9% over SQLM* and 27.3% over R-Zero*. This superiority is attributed to the framework's decoupled proposer-solver design and its advanced reward formulation, which guides the Proposer to generate a more diverse and challenging curriculum of questions.
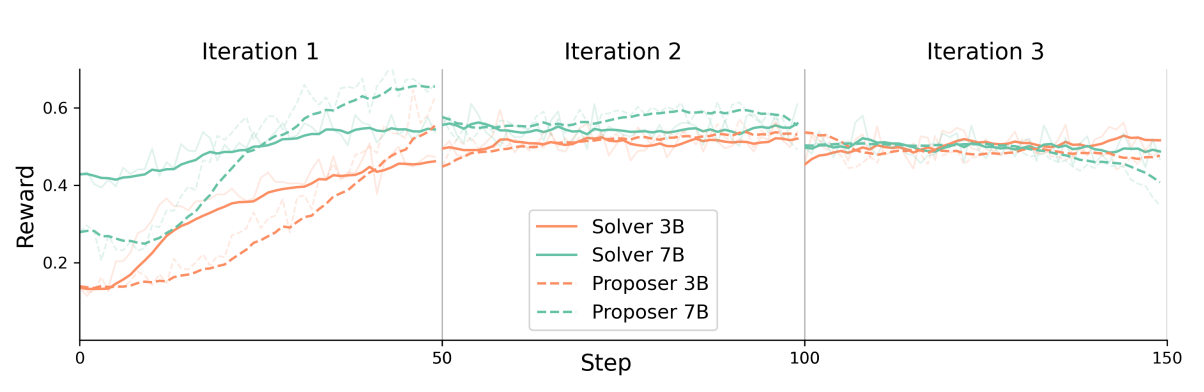
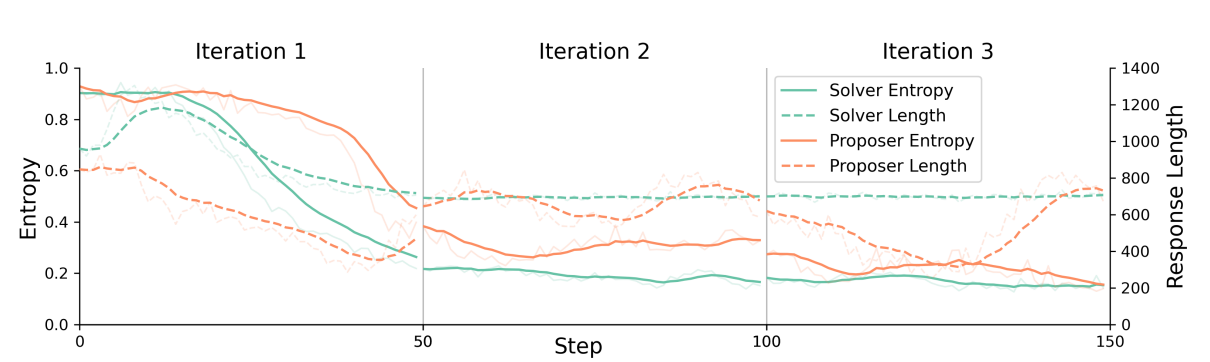
Training Dynamics and Scalability
An analysis of the learning process across multiple iterations reveals key insights into the framework's dynamics (Figure 3, Figure 4, and Table 3):
- Rapid Initial Learning: Solvers demonstrate a rapid initial learning phase, reaching a performance peak within the first 50 training steps. This suggests the most significant gains in core search and reasoning capabilities are realized early in the process.
- Iterative Improvement: The framework sustains improvement into a second iteration, with the 3B model showing an average performance gain of 4.93%. However, performance tends to plateau after 2-3 iterations, indicating technical constraints that limit indefinite self-evolution.
- Model Scaling Behavior: The framework's curriculum shows different effects based on model size (Table 4). This scaling behavior provides critical insight into curriculum design for self-evolution: smaller models require a curriculum that builds foundational skills from the ground up, while larger models, which possess greater inherent capacity for complex reasoning, benefit more from being immediately challenged with difficult, multi-hop problems.
Validation of HRPO Efficiency
The novel HRPO algorithm was validated as a highly efficient alternative to standard GRPO. As shown in Table 8, HRPO not only uses approximately one-fourth of the computational resources but also achieves a higher aggregate performance score (0.326 vs. 0.320). This result confirms HRPO's effectiveness as a computationally tractable method for the self-evolution of complex, tool-using agents.
The robust empirical evidence across these analyses provides strong validation for the Dr. Zero framework, transitioning the discussion to its broader implications for the field of AI.
5.0 Implications and Future Directions
The success of the Dr. Zero framework carries significant strategic implications for the future of AI development. This work directly challenges the foundational assumption that advanced reasoning capabilities are contingent on extensive human supervision. By demonstrating that sophisticated skills can emerge from a purely autonomous process, it opens new avenues for creating capable AI systems in data-scarce environments and reduces the dependency on costly data annotation pipelines.
Key Contributions and Potential Applications
The primary contributions of this research can be distilled into three key areas:
- Challenging the Need for Supervision: Dr. Zero provides compelling evidence that complex, multi-turn search and reasoning skills can be learned through pure self-evolution, without any human-curated data.
- Expanding Data-Free Methods: The framework successfully applies the self-evolution paradigm to open-domain search, a significant expansion beyond the more constrained domains of mathematics or coding where it was previously explored.
- Enabling Efficient Agent Training: The introduction of HRPO offers a computationally tractable method for training agents that must perform complex interactions with external tools, addressing a major bottleneck in the development of agentic AI.
Acknowledged Limitations and Future Work
A balanced assessment of the framework also requires acknowledging its current limitations. The research identifies performance plateaus that emerge after two to three training iterations, as well as training instability that can occur in larger models. These challenges point to clear directions for future research.
Proposed future work includes extending the stability of the self-evolution process to overcome performance plateaus and prevent entropy collapse, particularly in larger-scale models. Furthermore, a critical area of focus will be developing safeguards against potential failure modes like reward hacking and bias amplification, which can arise in learning loops that lack direct human supervision.
This research lays the groundwork for more robust and scalable self-improving AI systems.
6.0 Conclusion
In an era where high-quality training data is becoming a critical bottleneck, Dr. Zero presents a scalable and effective data-free self-evolution framework for developing advanced search agents. By creating a symbiotic feedback loop between a question-generating proposer and a problem-solving solver, Dr. Zero autonomously generates a dynamic curriculum of increasingly complex tasks. This process is made computationally efficient by the novel Hop-Grouped Relative Policy Optimization (HRPO) algorithm, which drastically reduces the resources required to train multi-turn, tool-using agents.
Dr. Zero provides compelling empirical evidence that self-evolution is a potent and computationally tractable paradigm for achieving state-of-the-art reasoning capabilities, fundamentally challenging the necessity of human supervision in advanced AI. This work proves that complex reasoning can emerge without direct reliance on human-curated data, paving the way for the next generation of autonomous and adaptable AI systems.
fin...