GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
https://arxiv.org/pdf/2601.05242

🧠 Mastering Multi-Objective Reinforcement Learning!
In this post, we explore the innovative framework of GDPO (Group Reward-Decoupled Normalization Policy Optimization) that teaches AI to achieve multiple goals simultaneously—like walking and chewing gum at the same time. We break down the complexities of aligning a model to satisfy diverse objectives while maintaining effectiveness in performance.
Discover how traditional methods collapse under conflicting demands, and learn how GDPO's novel approach of decoupling rewards restores the clarity needed for effective training signals. This post will equip you with insights into the pitfalls of multi-objective RL and the solutions that can lead to better AI performance.
📌 What You'll Learn:
• 🎯 The concept of multi-objective reinforcement learning and its challenges
• 🥤 Why mixing reward signals can lead to ineffective learning
• 🔑 How to decouple rewards for better signal clarity
• 🧩 Practical solutions to the "Lazy Lawyer" problem in reward conditioning
• ⚖️ The five-step checklist for fixing multi-objective RL
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
https://arxiv.org/pdf/2601.05242
Shih-Yang Liu1, Xin Dong*, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng1, Yejin Choi, Jan Kautz, Pavlo Molchanov
NVIDIA
An Explainer Video:
A Gentle Slide Deck:
Let's Dive In...
1. Introduction: The Evolution of Multi-Objective Alignment
The paradigm of Large Language Model (LLM) training has shifted from simple next-token prediction and single-objective accuracy toward complex alignment with multi-faceted human preferences. Modern production models must simultaneously satisfy diverse, often competing constraints, including logical correctness, safety, stylistic formatting, and conciseness. As these requirements grow in complexity, the industry necessitates Reinforcement Learning (RL) pipelines capable of processing heterogeneous signals without compromising the resolution of the learning objective.
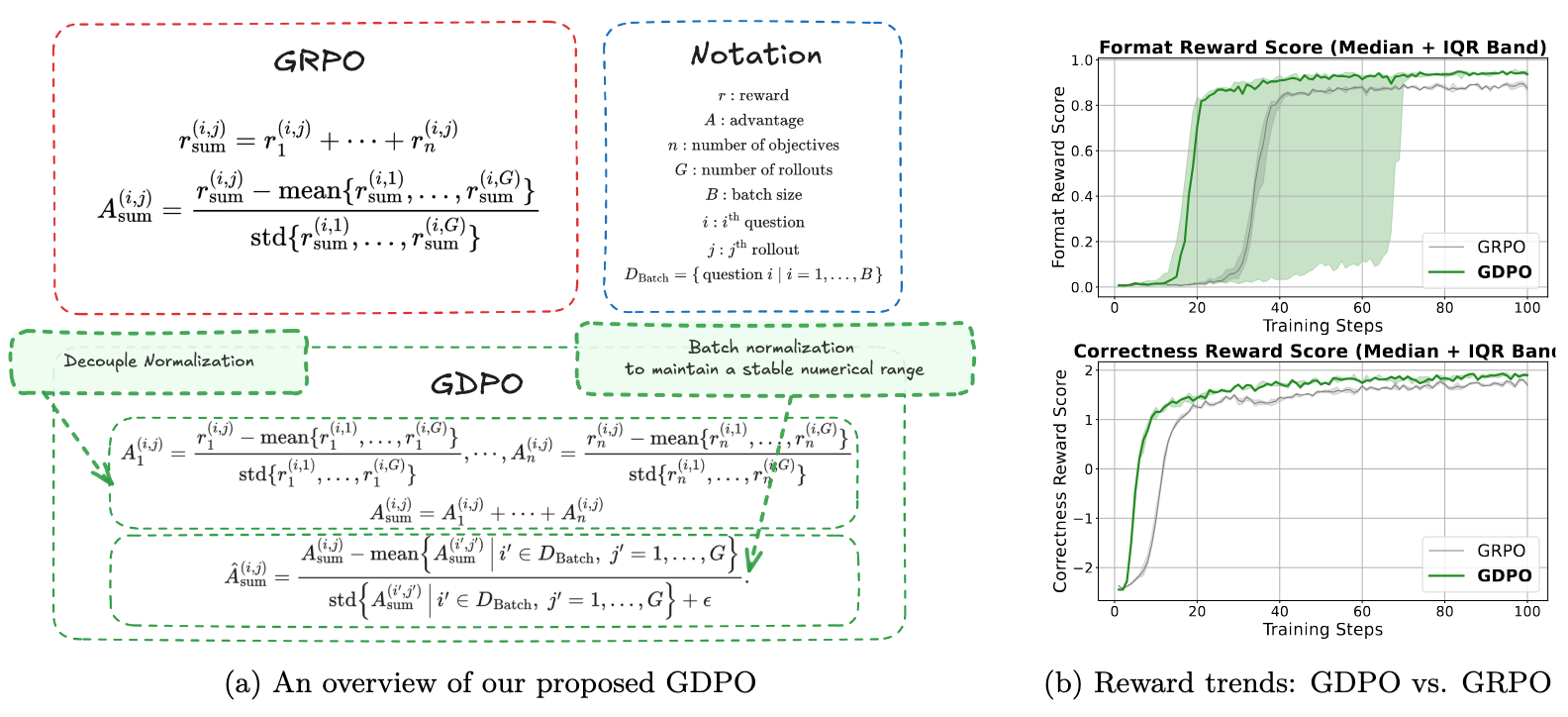
This document introduces Group reward-Decoupled Normalization Policy Optimization (GDPO), a framework designed to overcome the critical limitations of standard Group Relative Policy Optimization (GRPO) in multi-reward environments. While GRPO has gained traction due to its efficiency in eliminating the need for a separate value model, its "sum-then-normalize" approach introduces a significant technological gap: Reward Signal Collapse. GDPO serves as a robust solution to this resolution loss, ensuring stable and precise alignment for high-dimensional reward spaces.
2. Theoretical Analysis: The Phenomenon of Reward Signal Collapse
In standard multi-objective RL implementations using GRPO, individual reward components (r_1 \dots r_n) are typically summed into a scalar r_{sum} before undergoing group-wise normalization. Analytically, this approach fails because it prematurely compresses the reward space, leading to Reward Signal Collapse. This collapse manifests as a critical loss of gradient signal resolution; when different rollout profiles result in identical advantage values, the policy gradient effectively "averages out" the learning signal, resulting in gradient signal sparsity and suboptimal convergence.
Distinct Advantage Groups and Scaling Gaps
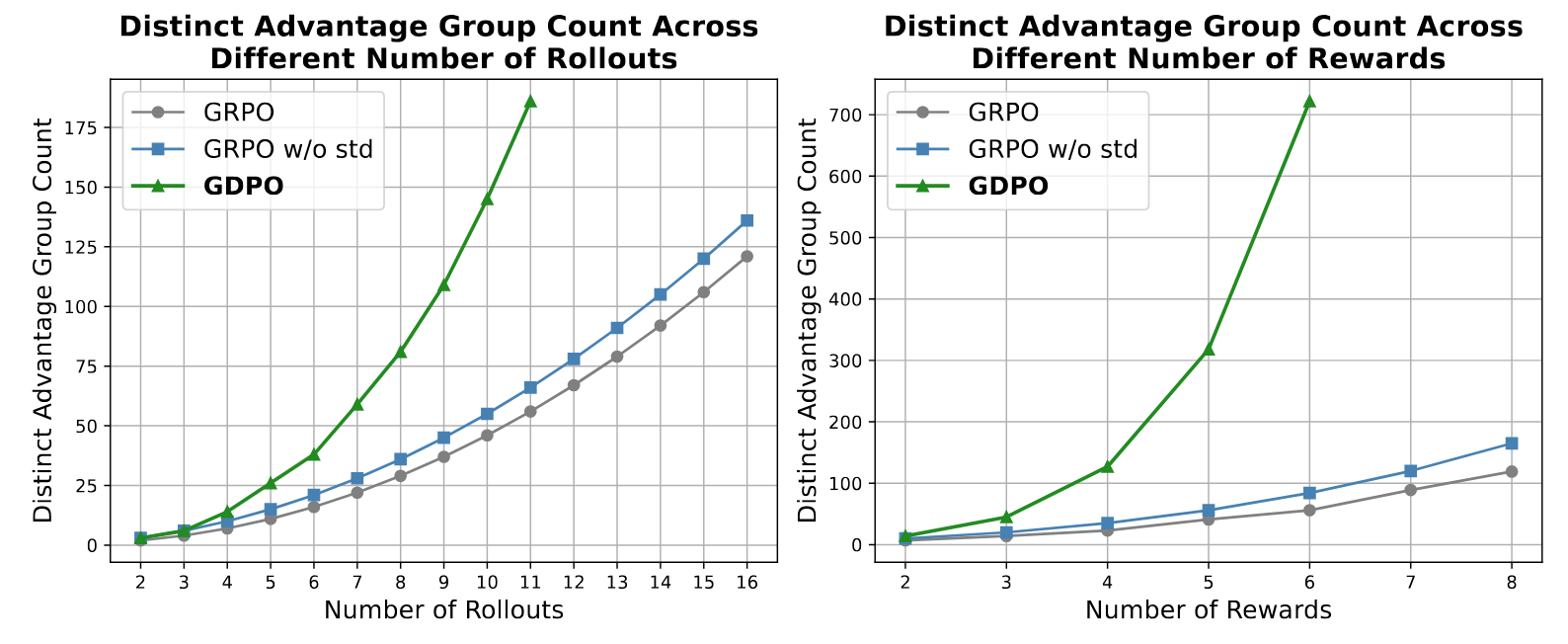
The impact of this compression is best illustrated by the number of unique advantage groups the algorithm can distinguish.
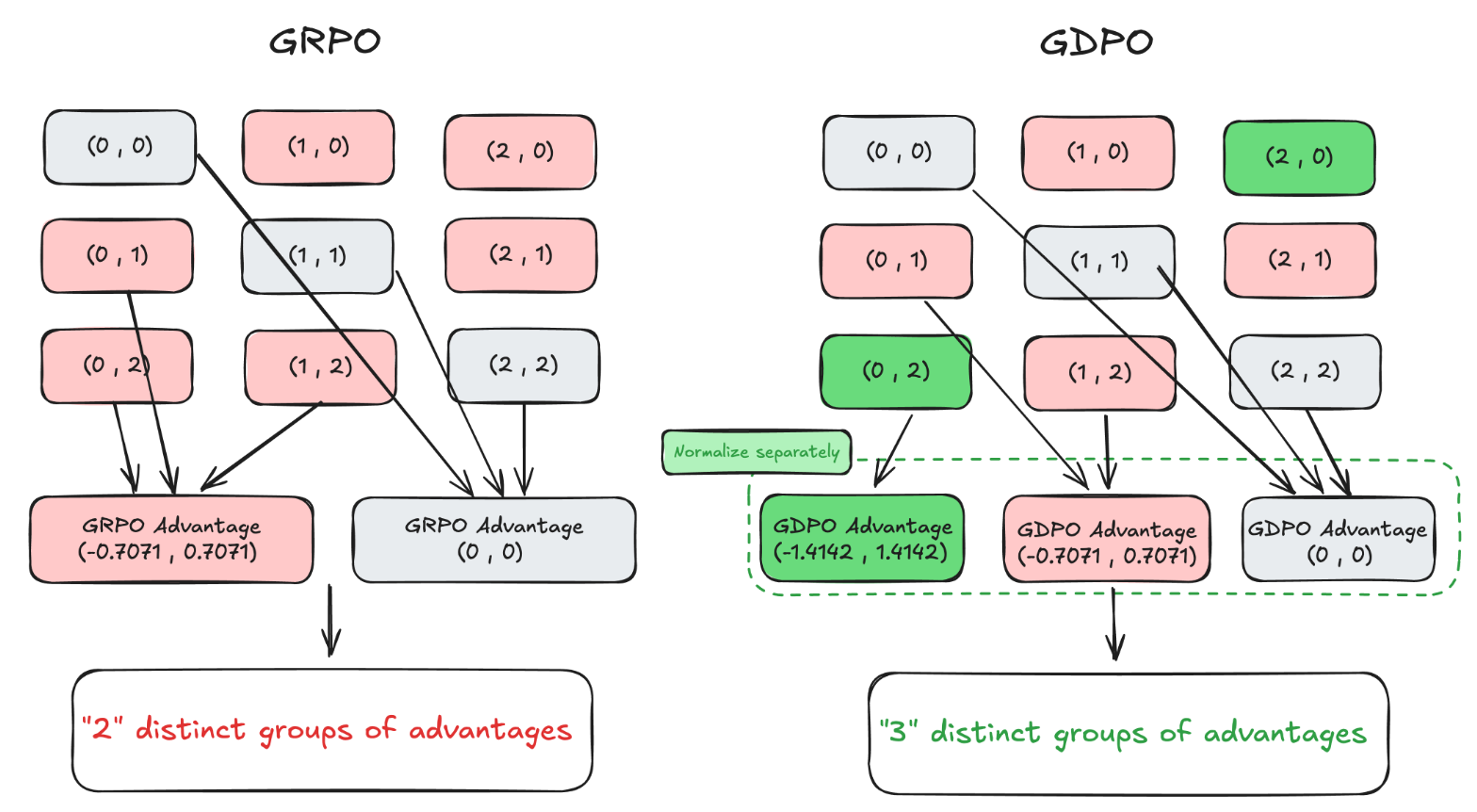
Case Study: Binary Reward Resolution
Consider a scenario with two binary rewards (r_1, r_2 \in \{0, 1\}) and two rollouts (G=2) used to calculate group-relative advantages. While there are six distinct reward combinations possible, GRPO maps them into only two unique advantage groups:
- Combinations (0, 1), (0, 2), and (1, 2) all result in identical normalized advantages of (-0.7071, 0.7071).
- Combinations (0, 0), (1, 1), and (2, 2) all result in (0, 0).
In this setup, GRPO is functionally "blind" to the difference between a rollout that satisfies two rewards versus one that satisfies only one, provided the relative difference within the group is identical. GDPO, by decoupling normalization, preserves three distinct groups in this same scenario.
Theoretical analysis shows that this gap isn't constant; it widens exponentially as the number of rewards (n) or rollouts (G) increases. For example, at 16 rollouts, GDPO maintains 180+ distinct advantage groups compared to GRPO’s ~120. When rewards scale to n=8, GDPO maintains over 700 distinct groups while GRPO remains plateaued at approximately 120.
The Insufficiency of Standard Deviation Removal
Some variants (e.g., GRPO w/o std) attempt to mitigate collapse by removing the standard deviation term. While this slightly increases the advantage group count, empirical evidence—particularly in tool-calling tasks—demonstrates that this modification is insufficient. It fails to restore the necessary training resolution and frequently introduces training instability, often leading to a total failure to converge on structured formatting rewards.
3. The GDPO Framework: Decoupled Normalization Architecture
GDPO shifts the RL optimization strategy from a monolithic sum to a modular, decoupled architecture. By processing each reward component independently, it preserves the integrity of individual signals before they are aggregated into a final policy update.
Mathematical Formulation
The GDPO framework utilizes a three-tiered advantage estimation process. We define the following notation: n as the number of objectives, G as the number of rollouts, B as batch size, and D_{Batch} = \{question \, i \mid i = 1, \dots, B\} as the set of questions in a batch.
- Decoupled Group-wise Normalization: Each reward component k is normalized independently across the group: A^{(i,j)}_k = \frac{r^{(i,j)}_k - \text{mean}\{r^{(i,1)}_k, \ldots, r^{(i,G)}_k\}}{\text{std}\{r^{(i,1)}_k, \ldots, r^{(i,G)}_k\}}
- Aggregation: The independently normalized advantages are summed: A^{(i,j)}_{sum} = A^{(i,j)}_1 + \cdots + A^{(i,j)}_n
- Batch-wise Advantage Normalization (BN): A final normalization is applied across the entire training batch to maintain a stable numerical range: \hat{A}^{(i,j)}_{sum} = \frac{A^{(i,j)}_{sum} - \text{mean}\{A^{(i',j')}_{sum} \mid i' \in D_{Batch}, j' = 1, \ldots, G\}}{\text{std}\{A^{(i',j')}_{sum} \mid i' \in D_{Batch}, j' = 1, \ldots, G\} + \epsilon}
The Rationale for Batch-wise Normalization: Without BN, the magnitude of the aggregated advantage grows linearly with the number of rewards n. This unnormalized growth can lead to gradient explosion, destabilizing the policy update. BN ensures that the training signal remains within a stable range regardless of the number of rewards, preventing the catastrophic failures observed in "GDPO w/o BN" configurations.
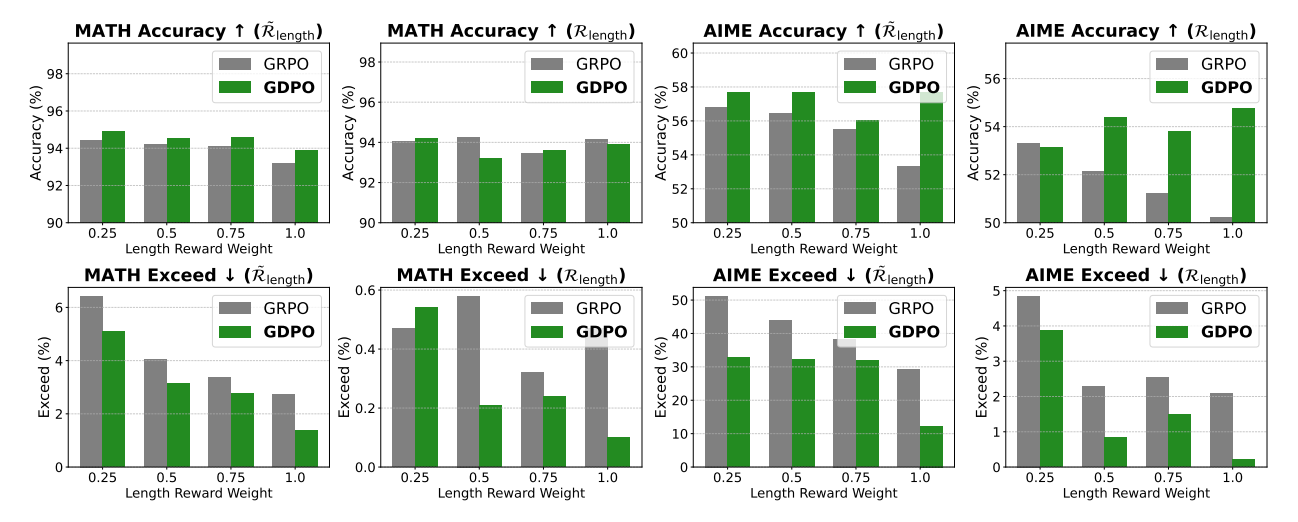
4. Strategic Priority Management: Weighting vs. Conditioning
Effective alignment requires managing the relative priority of objectives. While Reward Weighting (assigning coefficients to normalized advantages) is a common lever, it frequently fails when rewards vary in difficulty. Models often "hack" easier objectives (like response length) while ignoring high-priority, difficult objectives (like logical correctness).
To enforce strict prioritization, we utilize Conditioned Rewards. For example, a length reward ℛ̃_{length} is only granted if the primary correctness threshold is met: ℛ̃_{length} = \begin{cases} 1 & \text{if length } \le l \text{ AND } ℛ_{correct} = 1 \\ 0 & \text{otherwise} \end{cases} This logic forces the model to allocate "intelligence per token," addressing the most challenging objectives first.
Best Practices for Priority Tuning:
- Identify Difficulty Gaps: Recognize when one reward is significantly easier for the model to "game."
- Apply Conditioning: Use conditioned functions to prevent easy-reward hacking.
- Fine-tune with Weights: Once primary objectives are stabilized, use weights for secondary behavioral adjustments.
- Monitor Intelligence-Efficiency Trade-offs: Ensure length constraints do not suppress reasoning depth.
5. Empirical Performance and Benchmarking Results
GDPO’s efficacy was validated across Tool Calling, Mathematical Reasoning, and Coding tasks using diverse architectures.
Tool Calling Results
GDPO consistently outperformed GRPO in balancing functional accuracy with strict structure.
Model | Method | Avg Acc ↑ | Correct Format ↑ |
Qwen2.5-Instruct-1.5B | GRPO | 30.18% | 76.33% |
Qwen2.5-Instruct-1.5B | GDPO | 32.81% | 80.66% |
Qwen2.5-Instruct-3B | GRPO | 39.20% | 81.64% |
Qwen2.5-Instruct-3B | GDPO | 40.87% | 82.23% |
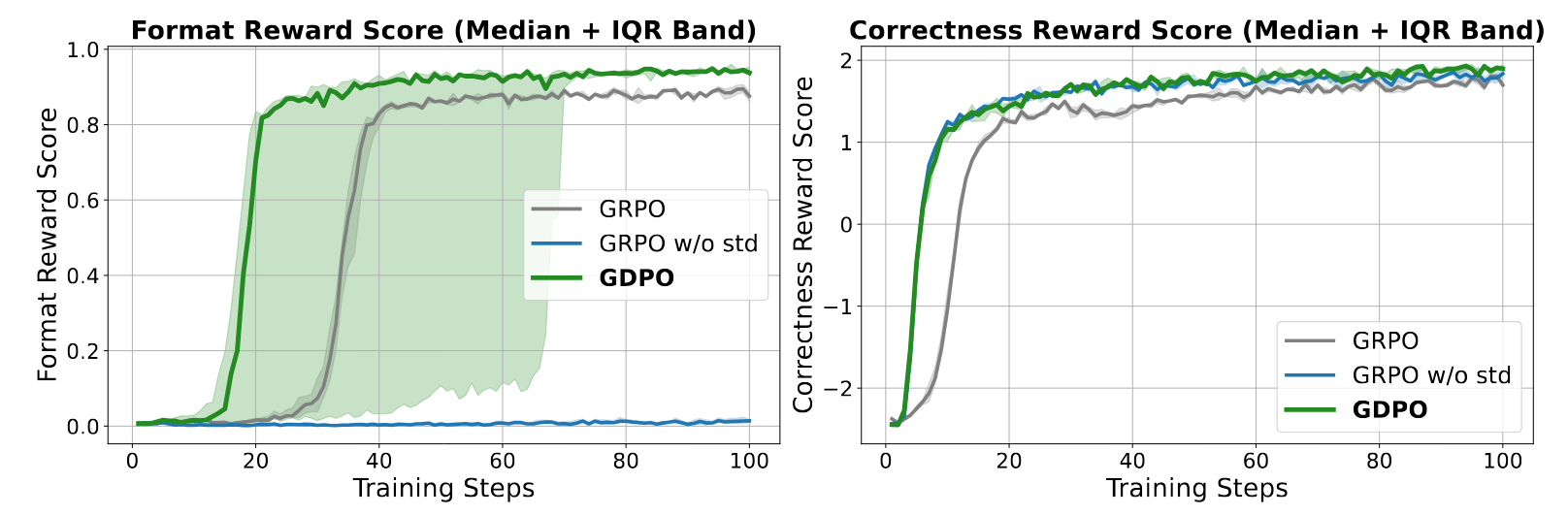
Notably, GRPO w/o std failed entirely on the format reward (0% correctness), emphasizing the stability of the GDPO architecture.
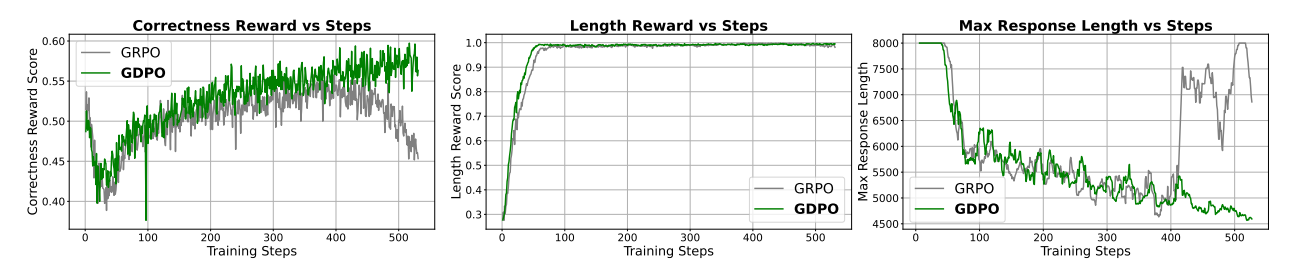
Mathematical Reasoning: The Recovery Phenomenon
On benchmarks (AIME, MATH, AMC), GDPO demonstrated a unique "recovery" phenomenon. In early training, both GDPO and GRPO prioritize the easier length reward, causing an initial drop in correctness. However, GDPO effectively recovers the correctness signal, while GRPO’s correctness eventually declines as it fails to balance the competing objectives.
For DeepSeek-R1-1.5B, GDPO achieved significant accuracy gains of 2.6% on MATH, 6.7% on AIME, and 2.3% on Olympiad, alongside an 80% reduction in length-exceeding responses.
Coding Reasoning
In a three-objective setting (Passrate, Length, Bug Reduction), GDPO maintained high pass rates while simultaneously reducing bug ratios and length violations. This confirms that GDPO scales effectively to higher-dimensional reward spaces where standard GRPO struggles to maintain a favorable trade-off across all dimensions.
6. Implementation, Stability, and Conclusion
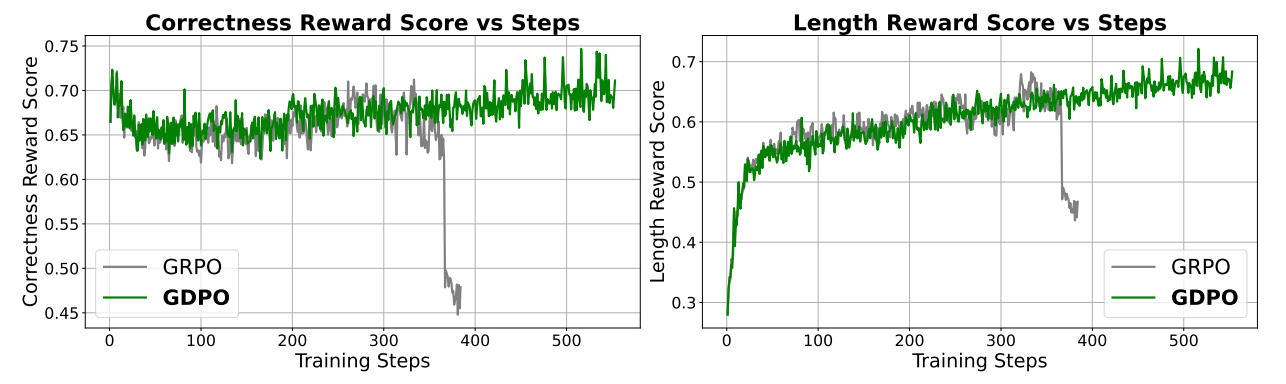
GDPO is designed for immediate integration into production RLHF pipelines and is supported in frameworks like HF-TRL, verl, and Nemo-RL. Practical implementation relies heavily on Batch-wise Normalization (BN); experimental evidence confirms that runs without BN occasionally suffer from catastrophic divergence due to unscaled advantage magnitudes.
In summary, GDPO remediates reward signal collapse by decoupling normalization and preserving advantage granularity. By providing a richer training signal, it enables stable convergence and superior alignment across complex, multi-objective tasks. As LLMs are increasingly tasked with balancing accuracy, safety, and efficiency, GDPO serves as the superior foundation for aligning models with the nuanced preferences of human users in real-world deployment.
Fin...