Learning to Discover at Test Time (TTT-Discover)

Learning to Discover at Test Time
https://arxiv.org/pdf/2601.16175
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, Yu Sun
Stanford University, NVIDIA, Astera Institute, UC San Diego, Together AI
An Explainer Video:
A Gentle Slide Deck:
Let's Dive In...
1.0 Introduction: Redefining AI's Role in Scientific Discovery
A core challenge in artificial intelligence is to create models that can generate ideas beyond their training data, moving from pattern recognition to genuine discovery. True scientific advancement requires more than extrapolating from existing knowledge; it demands the ability to learn from experience, adapt to novel problems, and synthesize new solutions. This whitepaper introduces Test-Time Training to Discover (TTT-Discover), a novel methodology that enables a Large Language Model (LLM) to learn from its own experience on a specific problem at test time. This approach moves beyond static, search-based methods and empowers the model to internalize new ideas in a process analogous to human learning.
Prior work, such as AlphaEvolve, has made significant progress by using a "frozen LLM" to conduct extensive evolutionary searches. While effective at exploring a solution space, this approach has a fundamental limitation: the model itself does not improve. The LLM can be prompted to refine previous attempts, but it cannot learn from trial and error. This is similar to a student who can never internalize the new ideas behind a difficult assignment. TTT-Discover bridges this gap by allowing the LLM to learn directly from the problem it is trying to solve.
The core concept of TTT-Discover is to perform reinforcement learning (RL) at test time. By framing a single scientific problem as an RL environment, the LLM's policy is continuously updated based on the outcomes of its own generated solutions. This form of continual learning is uniquely specialized for discovery. Unlike standard RL, the goal is not to achieve high average performance or to create a policy that generalizes to other problems. Instead, the singular objective is to produce one exceptional solution that surpasses the current state-of-the-art for a specific, out-of-distribution challenge.
The TTT-Discover methodology has demonstrated remarkable success across a diverse set of scientific and engineering domains. Key achievements include:
- Setting new state-of-the-art benchmarks in open mathematical problems, GPU kernel engineering, competitive algorithm design, and single-cell biology.
- Discovering novel, complex solutions that improve upon both the best-known human results and prior AI-driven methods.
- Achieving these results with an open model (OpenAI gpt-oss-120b), ensuring that the findings are transparent and reproducible.
To fully understand this methodology, we must first formalize the environment in which discovery takes place. The following section details how scientific problems can be structured as a common framework amenable to both search and learning.
2.0 The Discovery Problem: Formalizing the Environment for Search and Learning
A key strategic step in applying AI to scientific discovery is formalizing the problem as a Markov Decision Process (MDP). This structure provides a common, mathematically rigorous framework that allows us to apply a wide range of powerful techniques, from traditional search algorithms to modern reinforcement learning. By defining states, actions, transitions, and rewards, we can create a consistent environment for an AI agent to explore and learn within, regardless of the specific domain.
Based on this formalism, the discovery environment is defined by several key components:
- State (s): A state represents a complete candidate solution to the problem. This could be a specific mathematical construction, a piece of GPU kernel code, an algorithm implementation, or a data analysis pipeline.
- Reward (R(s)): The reward is a continuous value derived from a problem-specific function that evaluates the quality of a state. Examples include the inverse runtime of a kernel, a certified mathematical bound, or the score on a competitive benchmark.
- Discovery: A discovery is formally defined as the event of finding a state
swhose rewardR(s)is greater than the best-known rewardrsotafrom any existing solution.
An LLM acts as a policy, denoted πθ, which generates an action a given a current state s. The environment then executes this action to transition to a new state s'. The specific nature of these components varies across domains, as summarized below.
Problem | State s | Action a | Transition | Reward R(s) |
Erdős Minimum Overlap | Step function certificate | Thinking tokens and code |
| 1 / Upper bound |
Autocorr. Inequality (1st) | Step function certificate | Thinking tokens and code |
| 1 / Upper bound |
Autocorr. Inequality (2nd) | Step function certificate | Thinking tokens and code |
| Lower bound |
Kernel Engineering | Kernel code | Thinking tokens and code |
| 1 / Runtime |
Algorithm Competition | Algorithm code | Thinking tokens and code |
| Test score |
Single Cell Analysis | Analysis code | Thinking tokens and code |
| 1 / MSE |
Table 1: An overview of the discovery environments across application domains, adapted from the source.
Within this MDP framework, existing methods have primarily relied on search-based approaches. The simplest is "Best-of-N," where the policy πθ generates N independent solutions, and the best one is selected. A more sophisticated method is state-action reuse, also known as evolutionary search. This technique maintains a buffer of past attempts and uses a heuristic to select high-performing solutions to "warm start" new attempts. While these methods can effectively explore the solution space, they share a critical limitation: the underlying policy πθ remains frozen. The search improves the prompts fed to the LLM, but the model itself does not learn or adapt.
While search methods focus on improving the inputs to the policy, TTT-Discover goes a step further by improving the policy itself through direct learning.

3.0 TTT-Discover: A Novel Methodology for Learning at Test Time
The core innovation of TTT-Discover is its ability to overcome the limitations of a frozen policy by training the LLM on its own search attempts at test time. This allows the model to adapt and specialize its knowledge to the unique, out-of-distribution characteristics of a specific discovery problem. By learning from its own successes and failures in real-time, the policy becomes progressively more adept at generating high-quality solutions.
The high-level structure of TTT-Discover, outlined in Algorithm 1 of the source document, is a form of online reinforcement learning. The agent iteratively samples a starting state from a buffer of past attempts (reuse), generates a new solution, evaluates it, adds it to the buffer, and then updates its own policy weights based on this new experience (train). This cycle allows the model to continuously refine its strategy throughout the discovery process.
3.1 Overcoming the Shortcomings of Naive Reinforcement Learning
While TTT-Discover is a form of reinforcement learning, applying standard RL algorithms naively is ineffective due to critical differences between conventional RL tasks and scientific discovery problems.
Feature | Standard RL | Discovery Problems |
Primary Goal | Maximize expected (average) reward. | Find a single state that improves upon the state-of-the-art. |
Key Artifact | The policy itself. | The single best state found. |
Deployment | Policy is deployed repeatedly. | No separate deployment phase; training is solving. |
Success Metric | Robust average performance. | Maximum reward achieved, regardless of average performance. |
These distinctions lead to several shortcomings when applying naive RL to discovery:
- Objective Mismatch: Standard RL optimizes for average reward, making it indifferent to whether it finds a good solution or a groundbreaking one. A breakthrough discovery might receive a reward only marginally better than a minor improvement, providing a weak learning signal.
- Short Effective Horizon: By repeatedly starting from scratch, naive RL limits the complexity of solutions that can be developed in a single attempt. Reusing promising intermediate solutions effectively extends the problem-solving horizon.
- Ineffective Exploration: Optimizing for expected reward can cause the policy to favor safe, reliable actions over riskier but potentially more innovative ones. Naive reuse can also lead to over-exploitation of a few promising states, stifling diversity.
3.2 The Core Components of TTT-Discover
TTT-Discover introduces two key components specifically designed to address the shortcomings of naive RL and align the learning process with the goal of discovery.
- Entropic Objective (
Jβ(θ)) To focus the agent on finding exceptional solutions, TTT-Discover employs an entropic objective. This objective function mathematically favors actions that lead to the maximum reward rather than the average reward. It achieves this by exponentiating rewards (eβ(s)R(s,a)), a mechanism that gives disproportionately high weight to the best-performing solutions in a batch. This directs the policy updates toward the most promising areas of the solution space. The hyperparameterβ(s)is set adaptively for each state to manage training stability, preventing updates from becoming too aggressive early on or too timid in later stages. - PUCT-Inspired State Reuse Heuristic To extend the effective horizon and balance exploration with exploitation, TTT-Discover uses a state reuse heuristic inspired by the Predictor + Upper Confidence Bound for Trees (PUCT) algorithm. This method selects which previous solution to build upon by scoring each state in a buffer based on three factors:
- Value (
Q(s)): The maximum reward achieved by any descendant of that state. - Prior (
P(s)): A rank-based prior that favors states that have already achieved high rewards. - Exploration Bonus: A term that encourages the selection of less-explored states to maintain diversity and prevent premature convergence. This use of the maximum reward is a crucial distinction from standard tree search algorithms like AlphaZero's, which typically average rewards, and is specifically tailored for the goal of discovery where a single breakthrough outweighs average performance.
- Value (
The complete TTT-Discover method combines the entropic objective for the train routine with the PUCT heuristic for the reuse routine. This powerful combination ensures that the model learns to prioritize exceptional outcomes while intelligently exploring the vast space of possible solutions.
Parameter | Value |
Model | gpt-oss-120b |
Training Steps | 50 |
Batch Size | 512 |
Approximate Cost | ~$500 per problem |
Table 2: Key implementation details used across applications.
Having detailed the methodology, the following section provides a rigorous empirical validation of its performance across multiple domains.

4.0 Performance Analysis: Setting New State-of-the-Art Benchmarks
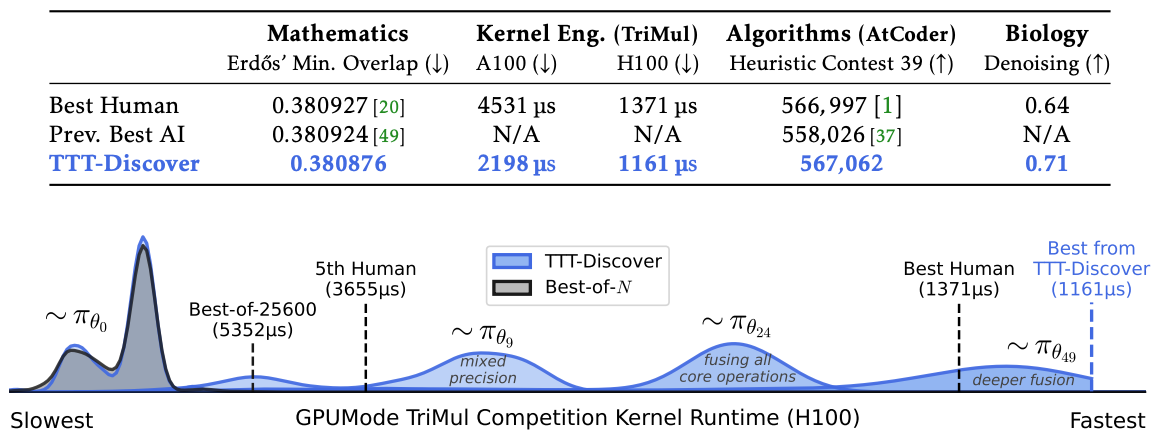
To rigorously evaluate its capabilities, TTT-Discover was applied to a diverse set of challenging problems across four distinct domains: mathematics, GPU kernel engineering, algorithm design, and biology. For every application, performance was benchmarked against the best-known human results and prior state-of-the-art AI systems. Critically, each TTT-Discover run was also compared against a "Best-of-N" baseline using the same model and an identical sampling budget (25,600 rollouts) to ensure a fair assessment of the learning component.
4.1 Domain: Mathematics
TTT-Discover was tasked with finding new constructions for open problems in mathematics, where even minor numerical improvements can represent significant advances. The method established new state-of-the-art bounds in two key areas:
- Erdős’ Minimum Overlap Problem: TTT-Discover improved the upper bound to 0.380876, surpassing the previous AI state-of-the-art (0.380924) set by AlphaEvolve. This improvement is 16 times larger than AlphaEvolve’s improvement over the previous human state-of-the-art. The discovered solution is a highly complex, 600-piece asymmetric step function, a departure from the simpler, symmetric constructions found by prior work (Figure 2, source).
- First Autocorrelation Inequality: The method improved the upper bound to prove C1 ≤ 1.50286. In contrast to prior work which refined existing constructions, TTT-Discover found this superior bound by developing a new 30,000-piece step function from scratch (Figure 3, source).
- Circle Packing: While not setting a new record, TTT-Discover matched the best-known human and AI constructions for packing 26 and 32 circles in a unit square, demonstrating its competence on established benchmarks.
Human Expert Review — Prof. Davide Torlo (Università di Roma La Sapienza)
Erdős’ minimum overlap problem and the autocorrelation inequalities are classical problems in combinatorics with applications in, among others, discrepancy theory, combinatorial optimization, and signal analysis... The upper bounds obtained by TTT-Discover for the Erdős’ minimum overlap and the AC1 autocorrelation problems are achieved by specific piecewise-constant functions. It is straightforward to verify that the provided functions give bounds that improve upon the state of the art...
4.2 Domain: GPU Kernel Engineering
TTT-Discover was applied to optimize GPU kernels for GPUMODE competitions, a domain where human experts continuously push the boundaries of hardware performance.
For the TriMul (triangular matrix multiplication) competition, kernels generated by TTT-Discover achieved state-of-the-art runtime across all tested GPU types (NVIDIA A100, H100, B200, and AMD MI300X). For example, it delivered a 2.06x speedup over the top human kernel on the NVIDIA A100 GPU (2198.2 µs vs. 4531.5 µs). The agent discovered a powerful optimization strategy: fusing memory-bound operations (like LayerNorm and gating) to reduce memory traffic and delegating the compute-heavy matrix multiplications to the highly optimized cuBLAS library.
For the MLA-Decode competition, the discovered kernels matched the performance of the top human submission but did not significantly surpass it.
Human Expert Review — Matej Sirovatka, Alex Zhang, Mark Saroufim (GPUMode)
The referenced solution correctly determined that the problem is memory bound because of the surrounding point-wise operations so the agent focuses as much as possible on operation fusions... This is similar to the current best human solutions, but executed on better. Most of the human solutions lack behind in fusing some of the more complex operators together, resulting in this solution outperforming them by a large margin.
4.3 Domain: Algorithm Engineering
The method was tested on past AtCoder Heuristic Contests (AHC), which feature complex, real-world optimization problems. The algorithms developed by TTT-Discover would have achieved 1st place in both competitions attempted.
- AHC039 (Geometry): TTT-Discover started with a 5th-place solution from a prior AI system and improved the score from a 5th-place equivalent of 550,647 to a 1st-place score of 567,062, surpassing the best human score of 566,997. The discovered algorithm combined prefix sum scoring, greedy seeding, and simulated annealing.
- AHC058 (Scheduling): Starting from scratch, TTT-Discover developed an algorithm that scored 848,414,228, outscoring all human and AI submissions, including the top human score of 847,674,723. The strategy involved building initial plans with greedy rules and beam search, followed by refinement using simulated annealing.
4.4 Domain: Single-Cell Analysis
TTT-Discover was applied to a single-cell RNA-seq denoising problem from the OpenProblems benchmark, a task aimed at improving the quality of noisy biological data. The results show that TTT-Discover achieved the highest overall score and the lowest Mean Squared Error (MSE) on both the PBMC and Tabula datasets, outperforming established methods. The agent began with the well-known MAGIC algorithm and systematically improved it by incorporating novel steps, including gene-adaptive transform ensembling, low-rank SVD refinement, and a log-space polishing step that directly optimized the benchmark metric.
Human Expert Review — Prof. Eric Sun (MIT)
The proposed improvement on the MAGIC algorithm is simple, aligns with the underlying smoothing-based approach of MAGIC, and yields empirical improvements on key metrics. However, improvements on metrics for single-cell data analysis tasks may not always transfer to enhanced ability to obtain new biological insights... Further evaluation of the proposed algorithm against MAGIC and other existing methods for biologically relevant tasks would be necessary to fully understand the extent of the reported improvements.
These strong results across four different fields demonstrate the power and versatility of the TTT-Discover methodology. We now turn to validating the specific design choices that enabled this performance.
5.0 Ablation Studies: Validating the Core Components
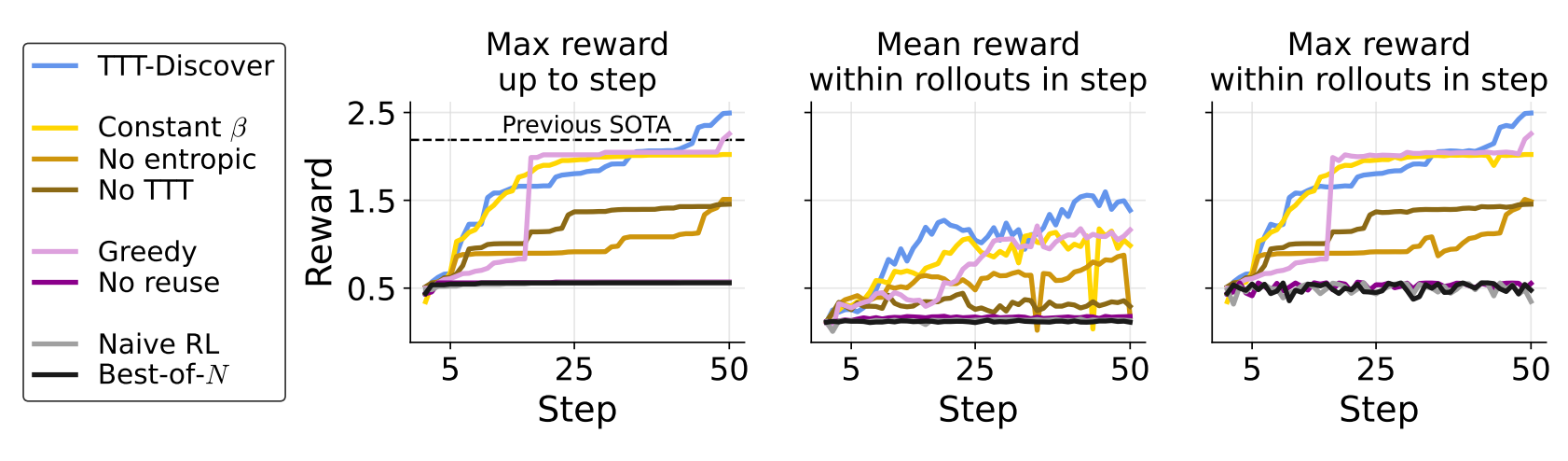
To isolate and validate the impact of TTT-Discover's key components—the entropic training objective and the PUCT reuse heuristic—a series of ablation studies were conducted. The TriMul GPU kernel engineering task served as the testbed, with performance measured by the best kernel runtime achieved. Each ablated configuration was compared against the full TTT-Discover method and relevant baselines.
Training Method | Reuse Method | Best Runtime (µs) ↓ |
TTT-Discover (Full Method) | PUCT | 1203.10 |
Best Human Kernel | — | 1371.1 |
TTT with constant | PUCT | 1483.83 |
TTT with expected reward (no entropic) | PUCT | 1985.67 |
No TTT | PUCT | 2060.70 |
TTT with adaptive entropic |
| 1328.89 |
TTT with adaptive entropic | No reuse | 5274.03 |
Naive Test-time RL (expected reward, no reuse) | No reuse | 5328.73 |
Best-of-N (no TTT, no reuse) | No reuse | 5352.36 |
Table 3: Ablation study results for the TriMul kernel optimization task on an H100 GPU, comparing the full TTT-Discover method against variants with key components removed or altered.
The analysis clearly shows that only the full TTT-Discover algorithm achieved state-of-the-art performance, surpassing the best human kernel. Analysis of reward distributions over the 50 training steps (Figure 4, source) shows that removing test-time training entirely (No TTT) or state reuse (No reuse) caused performance to stagnate after initial sampling, with maximum rewards failing to improve significantly over the course of the run, performing similarly to the Best-of-N baseline. Using a standard expected reward objective also slowed improvements considerably. These results empirically confirm that the specific combination of an adaptive entropic objective and a sophisticated PUCT-based reuse mechanism is critical to the success of the TTT-Discover methodology.
Having validated the method's internal components, we now place TTT-Discover within the broader context of related AI research.
6.0 Context and Related Work
TTT-Discover is situated at the intersection of several key areas in AI research, drawing from and extending established concepts in continual learning and, more specifically, test-time training. Its novelty lies in adapting these principles for the unique goal of scientific discovery, where finding a single exceptional solution is paramount.
Continual Learning is a broad field focused on enabling AI systems to learn continuously from a changing data distribution after initial deployment, much like humans learn throughout their lives. Conventional approaches often focus on preventing the model from forgetting past knowledge while adapting to new information.
Test-Time Training (TTT) is a specialized form of continual learning that formulates a new learning problem for each individual test instance. Instead of training a single static model to be good at all possible future inputs, TTT allows a model to adapt itself to the specific characteristics of the problem at hand.
TTT-Discover is a unique instantiation of test-time training, distinguished from related approaches by its objective and methodology:
- TTT on Nearest Neighbors: This approach fine-tunes a model on similar examples from a pre-existing training set before making a prediction on a test instance. TTT-Discover, in contrast, learns from data generated from the test problem itself.
- TTT for Novel Instances (Self-Supervision): This method generates new training data from an unlabeled test instance for an auxiliary task (e.g., masked reconstruction) to improve generalization. TTT-Discover directly optimizes for the primary task reward.
- Concurrent Work (MiGrATe & ThetaEvolve): These recent works share the high-level idea of using reinforcement learning at test time. TTT-Discover's superior empirical performance can be attributed to its specialized components: the entropic objective, which prioritizes maximum reward, and the PUCT-based reuse heuristic, which effectively balances exploration and exploitation for discovery tasks.
- One Example RL: This paradigm aims to train a policy on a single training example that generalizes well to other problems in the same dataset. TTT-Discover's goal is fundamentally different: it trains on the test problem itself with the sole objective of solving that specific problem, not generalization.
- RL on the Test Set (TTRL): TTRL trains a model on an entire test set of problems to improve average performance across the set. TTT-Discover trains on a single test problem to find one exceptional solution, prioritizing maximum reward over average performance.
By uniquely combining these concepts, TTT-Discover carves out a new niche tailored specifically for AI-driven scientific and algorithmic discovery.
7.0 Conclusion and Future Directions
Test-Time Training to Discover (TTT-Discover) is a novel methodology that redefines AI's role in scientific discovery by enabling models to learn from experience on a single problem at test time. Its core innovation is applying a specialized form of reinforcement learning—combining an entropic objective that favors maximum rewards with a PUCT-inspired reuse heuristic—to empower an AI agent to adapt, explore, and generate novel solutions in a manner that overcomes the limitations of static, search-based approaches.
The empirical evidence presented is both broad and compelling. TTT-Discover has set new state-of-the-art benchmarks across four diverse and challenging domains—mathematics, GPU kernel engineering, algorithm design, and single-cell analysis. These results, achieved with a reproducible, open model, demonstrate a powerful and generalizable approach to tackling complex scientific and engineering problems. The discovered solutions, validated by human experts, are not just incremental improvements but often represent new and more complex strategies.
The most important direction for future work is to extend this methodology beyond its current scope. The present form of TTT-Discover relies on problems with continuous, verifiable rewards. A crucial next step will be to adapt these principles to problems with sparse or binary rewards (where feedback is simply success or failure) and to non-verifiable domains where the quality of a solution cannot be easily quantified. Success in these areas would unlock the potential for AI-driven discovery in an even wider range of scientific frontiers.