Maximum Likelihood Reinforcement Learning (MaxRL)

https://arxiv.org/pdf/2602.02710
Fahim Tajwar, Guanning Zeng, Yueer Zhou, Yuda Song
Daman Arora, Yiding Jiang, Jeff Schneider, Ruslan Salakhutdinov
Haiwen Feng, Andrea Zanette
Carnegie Mellon University, Tsinghua University, Zhejiang University, UC Berkeley, Impossible, Inc.
🚀 Unlocking the Future of Reinforcement Learning with MaxRL!
In this post, we explore the innovative research paper "Maximum Likelihood Reinforcement Learning" by Fahim Tajwar, Guanning Zeng, and their colleagues from Carnegie Mellon University and other esteemed institutions. Discover how MaxRL addresses the limitations of traditional reinforcement learning by maximizing the true likelihood of outcomes, rather than just optimizing for rewards.
We delve into the key differences between reinforcement learning and maximum likelihood methods, uncovering why focusing on low-probability failures can lead to more robust learning. Join us as we unpack the mechanics of MaxRL, its computational advantages, and how it significantly enhances inference efficiency in various applications, including navigation and problem-solving.
📌 What You'll Learn:
• The critical distinction between reinforcement learning and maximum likelihood optimization
• How MaxRL changes the learning dynamics to focus on harder prompts
• The efficiency gains in training and inference with MaxRL
• Empirical results showing MaxRL's superiority on mathematical benchmarks
An Explainer Video:
A Gentle Slide Deck:
Let's Dive In...
1. The Paradigm Shift: From Expected Reward to Maximum Likelihood
In the optimization of large language models (LLMs) for verifiable tasks—such as code generation, mathematical reasoning, and navigation—Reinforcement Learning (RL) is frequently deployed as a "workaround" for the non-differentiability of the sampling process. While Maximum Likelihood (ML) remains the foundational objective for generative modeling in differentiable settings, researchers pivot to RL when success is determined post-sampling by an external verifier. This pivot, however, often overlooks a critical theoretical discrepancy: the choice of objective fundamentally alters the resulting optimization dynamics.
The "First-Order" Limitation and the Vanishing Gradient Standard RL approaches, primarily the REINFORCE algorithm, operate as first-order approximations of the ML objective. By evaluating the population-level gradients, the distinction becomes mathematically evident:
- Standard RL Gradient: \nabla_\theta J_{RL} = E_x[\nabla_\theta p_\theta(x)]
- Maximum Likelihood Gradient: \nabla_\theta J_{ML} = E_x[\frac{1}{p_\theta(x)} \nabla_\theta p_\theta(x)]
The 1/p_\theta(x) term in the ML gradient serves as a crucial importance reweighting mechanism. In standard RL, the gradient is proportional to the success probability p; consequently, for "hard" tasks where p \to 0, the learning signal vanishes. MaxRL addresses this "Vanishing Gradient" problem by incorporating the inverse-probability term, ensuring that the gradient signal remains robust even for the most difficult inputs in the distribution.
The Implicit Likelihood Argument From a system-level perspective, a model acts as a latent-generation system that induces a Bernoulli distribution over success for any given input. Direct optimization of this implicit likelihood is a principled choice, yet it has been historically avoided due to the computational difficulty of estimating \log p when success events are rare.
Connective Tissue Bridging this approximation gap requires a framework that leverages increased compute to move beyond first-order approximations. Maximum Likelihood Reinforcement Learning (MaxRL) provides this bridge by indexing the optimization objective to the available sampling budget.
--------------------------------------------------------------------------------
2. The MaxRL Framework: Principles and Mathematical Foundations
MaxRL introduces a compute-indexed family of objectives, allowing the optimization target to interpolate between standard RL and exact maximum likelihood. This creates a strategic trade-off where researchers can exchange increased sampling compute for higher-fidelity approximations of the ML target.
The Maclaurin Expansion The mathematical core of MaxRL is the expansion of the log-likelihood in terms of failure events. As detailed in the source context, the ML objective J_{ML}(x) = \log p can be expressed as: J_{ML}(x) = -\sum_{k=1}^{\infty} \frac{(1-p)^k}{k} = -\sum_{k=1}^{\infty} \frac{fail@k(x)}{k} Differentiating this expansion yields the population-level gradient as an infinite harmonic mixture of pass@k gradients:
- \nabla_\theta J_{ML}(x) = \sum_{k=1}^{\infty} \frac{1}{k} \nabla_\theta pass@k(x)
- Truncating this series at order T yields J_{MaxRL}^{(T)}.
- When T=1, the objective recovers standard REINFORCE; as T \to \infty, it converges to exact ML.
Structural Integrity: Theorems 1 & 2 The framework rests on two theoretical proofs:
- Theorem 1 (Conditional Form of ML Gradient): Proves that \nabla_\theta J_{ML}(x) = E[\nabla_\theta \log m_\theta(z|x) | f(z) = y^*(x)]. This confirms that the ideal gradient is the average of gradients derived exclusively from successful trajectories.
- Theorem 2 (Estimator–Objective Equivalence): Establishes that for N rollouts, the estimator is unbiased for the MaxRL objective of order T=N.
Importantly, this implies that in MaxRL, increasing N improves the objective itself by moving it closer to the true ML target, rather than merely reducing the variance of a static first-order objective.
Implementation Mechanics The on-policy implementation utilizes a variance-reduced formulation with the unconditional average score (V_N) as a control variate:
- Batching: For each input, generate N latent trajectories.
- Reward Attribution: Assign binary rewards r_i \in \{0, 1\}.
- Advantage Normalization: Compute the advantage A_i = \frac{r_i - \hat{r}}{N \hat{r}}, where \hat{r} is the per-task mean reward.
- Gradient Update: Apply the score function S_i weighted by the normalized advantage. If \hat{r} = 0, the gradient is set to zero.
Connective Tissue The theoretical convergence to ML ensures structural soundness, but the practical utility of MaxRL is best demonstrated by how it reallocates the learning signal across the data distribution.
--------------------------------------------------------------------------------
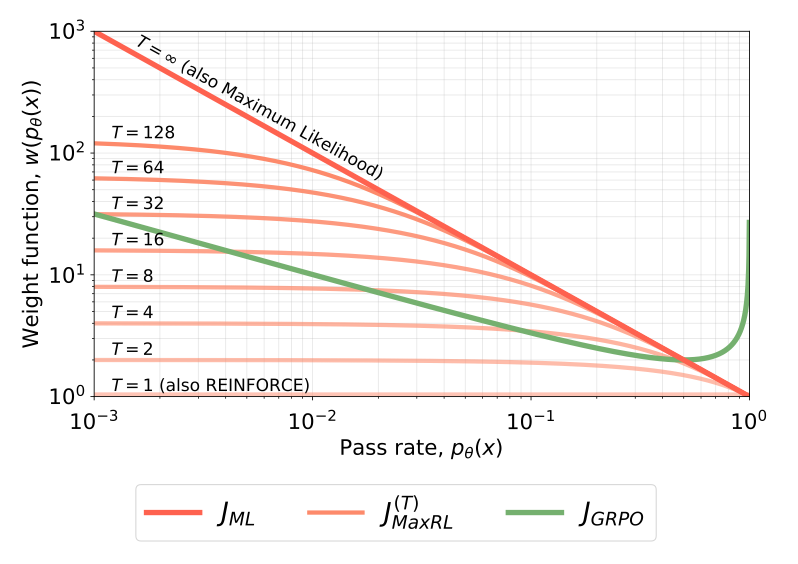
3. Qualitative Analysis: The Weight-Function Perspective
The scalar weight function w(p) determines the allocation of learning signals across prompts of varying difficulty. MaxRL’s weighting behavior is the primary driver of its robustness against the "hard prompt" problem.
Comparative Weighting Analysis
Objective | Population Weighting Function w(p) | Characterization |
Standard RL (REINFORCE) | 1 | Uniform; marginalizes hard tasks due to p scaling. |
GRPO | \frac{1}{\sqrt{p(1-p)}} | Moderate upweighting of hard prompts; inverts as p \to 1. |
MaxRL (Order T) | \frac{1-(1-p)^T}{p} | Compute-indexed interpolation toward ML. |
Exact ML | \frac{1}{p} | Maximally prioritizes low-pass-rate (hard) prompts. |
The "Hard Prompt" Advantage and Distribution Sharpening Unlike GRPO, which employs a heuristic Z-normalization that causes the weighting function to invert (increasing as p \to 1), MaxRL monotonically prioritizes harder tasks. GRPO’s inversion favors "overly easy" inputs, contributing to distribution sharpening—a phenomenon where the model collapses its diversity to focus on high-probability paths. MaxRL avoids this collapse by concentrating the gradient signal on hard, low-pass-rate inputs, effectively importance-reweighting the learning signal.
Connective Tissue By preventing the marginalization of difficult tasks, MaxRL achieves superior scaling and convergence across training regimes.
--------------------------------------------------------------------------------
4. Empirical Validation across Training Regimes
Empirical evidence confirms that MaxRL Pareto-dominates existing baselines across differentiable and non-differentiable environments.
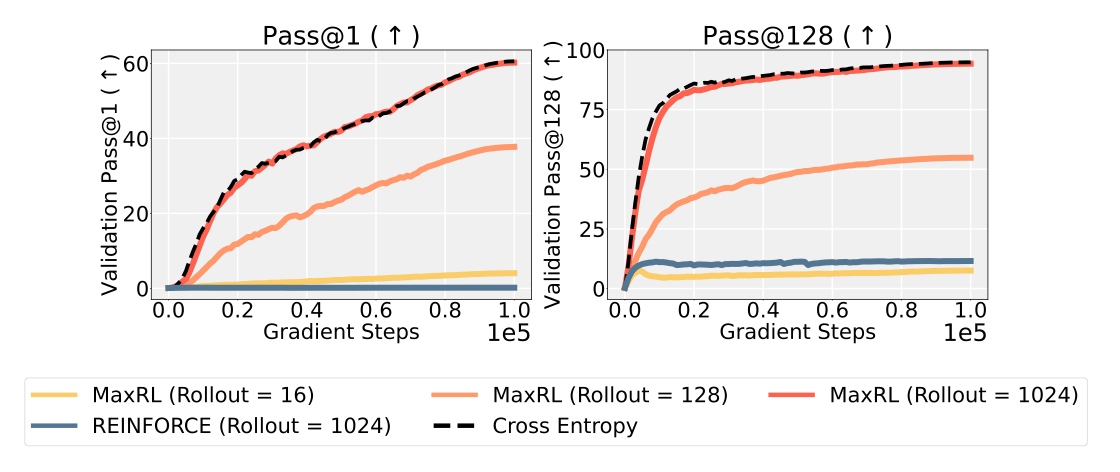
The ImageNet Benchmark In ResNet-50 experiments where exact cross-entropy (ML) is the ground truth, REINFORCE failed to progress from an initial pass rate of ~0.1%. In contrast, MaxRL closely tracked the exact cross-entropy training curve. As rollout counts increased, MaxRL's performance mirrored the ML target, validating the "objective evolution" hypothesis.
Scaling Trends and Overfitting Resistance
- Data-Rich (Maze Navigation): In a 3M-parameter transformer model trained on 1 million unique mazes, MaxRL demonstrated extreme efficiency. At only 4 rollouts, MaxRL outperformed the RLOO baseline using 128 rollouts, representing a 32x increase in sample efficiency.
- Data-Scarce (GSM8K): Using SmolLM2-360M-Instruct, standard RL (RLOO/GRPO) achieved peak performance at 10 epochs before suffering from diversity collapse. MaxRL, however, maintained "healthy" diversity—as measured by superior pass@128 and pass@256 metrics—and continued to improve through 50 epochs.
Connective Tissue The resilience of MaxRL in data-scarce and data-rich environments makes it a necessary framework for the alignment of larger reasoning models.
--------------------------------------------------------------------------------
5. Large-Scale Reasoning and Test-Time Efficiency
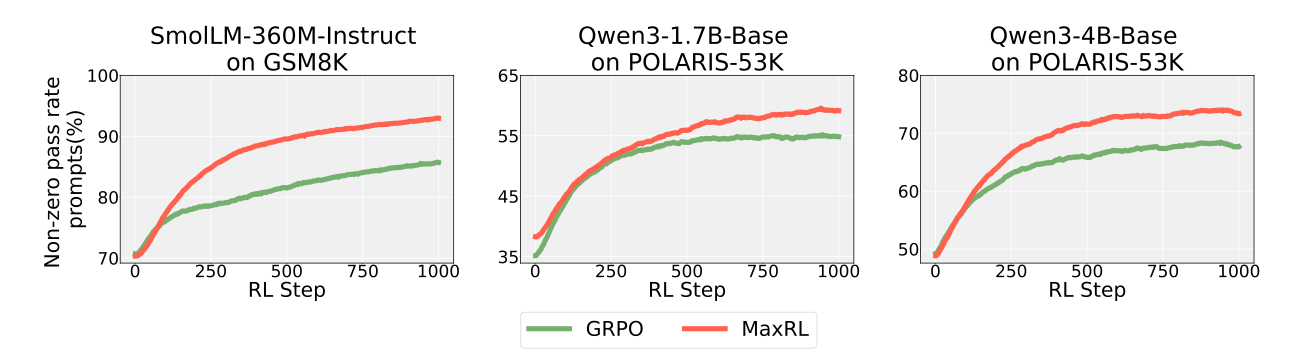
When applied to billion-parameter reasoning models trained on the POLARIS-53K dataset, MaxRL demonstrates substantial gains in both accuracy and inference efficiency.
Reasoning Model Performance Evaluation of Qwen3-1.7B and 4B-Base models across AIME 2025, BeyondAIME, MATH-500, and Minerva shows that MaxRL consistently Pareto-dominates GRPO:
- Superior Pass Rate: Achieves higher pass@1 accuracy on all benchmarks.
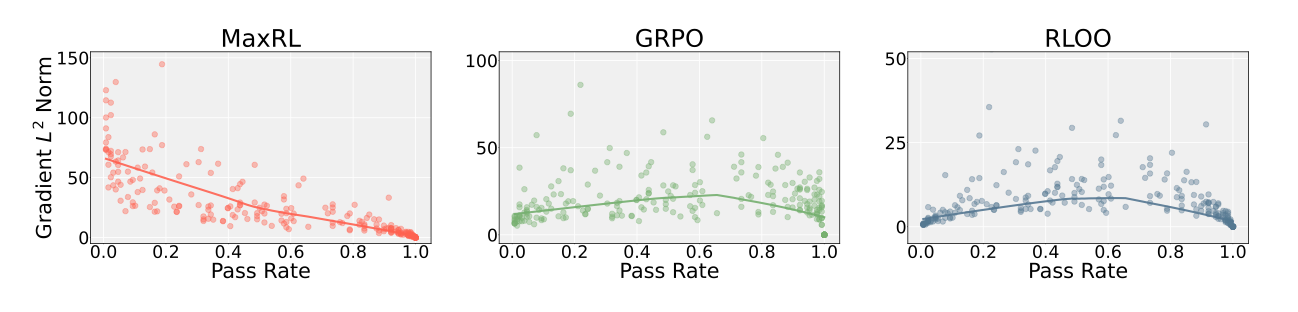
- Diversity Preservation: Unlike GRPO, which causes mode collapse, MaxRL improves pass@k relative to the base model in 7 of 8 settings.
- Gradient Concentration: Generates significantly larger gradient norms on harder prompts (near-zero pass rate), extracting more signal from the training distribution.
The Inference Efficiency Multiplier MaxRL delivers massive test-time scaling gains, including a 16.4x gain on BeyondAIME for Qwen3-4B and a 19.2x gain on Minerva. This efficiency stems from MaxRL’s preservation of output diversity (coverage). Because the model avoids mode collapse, the probability of finding a correct solution in a set of samples is higher, allowing verifiers to identify a "needle in a diverse haystack" with significantly fewer rollouts compared to GRPO-trained models.
Connective Tissue These findings underscore MaxRL's role as a scalable, principled alternative to traditional reward-maximization strategies.
--------------------------------------------------------------------------------
6. Conclusions and Future Directions
MaxRL represents a paradigm shift from simple reward maximization to a compute-indexed maximum likelihood framework. By addressing the fundamental "first-order error" of standard RL, MaxRL enables the training of more robust and diverse reasoning models.
Summary of Innovations
- Convergence to ML: Explicitly targets the maximum likelihood objective as sampling compute scales.
- Superior Compute Scaling: Achieves higher accuracy with orders of magnitude fewer rollouts than RLOO.
- Overfitting Resistance: Sustains learning over many epochs on fixed datasets without the diversity collapse seen in GRPO.
- Transferability to Reasoning: Demonstrated Pareto-dominance in large-scale LLM post-training on POLARIS-53K.
- Distinct Optimization Dynamics: Effectively counteracts vanishing gradients by concentrating signal on hard prompts.
Future Research Frontiers Current constraints involve binary reward structures. High-priority research directions include:
- Expanding the framework to continuous reward signals.
- Integrating MaxRL into off-policy training pipelines (e.g., PPO-style updates).
- Developing Multi-turn RL variants of the MaxRL objective.
MaxRL is the essential correction to the historical limitations of RL scaling, providing the mathematical foundation for the next generation of verifiable-reward reinforcement learning.
fin..