MemRL: A Framework for Continuous, Non-Parametric Learning in AI Agents
Can AI actually learn from its mistakes the same way we do? 🧠
In this post, we explore MemRL (Memory-Augmented Reinforcement Learning), an interesting AI framework designed to mimic the human brain’s ability to balance long-term knowledge with new, real-world experiences.
We dive into the "Stability-Plasticity Dilemma," why traditional AIs suffer from "catastrophic forgetting," and how MemRL achieves a massive 56% performance leap over previous memory-based methods. 🚀
If you’re interested in the future of Artificial Intelligence and how we’re making machines more human-like, this deep dive is for you!
In this post, you’ll learn:
The core problem with AI learning today ❌
How the human brain handles memory vs. how robots do 🤖
The architecture of MemRL: Memory Triplets and Utility Scores 📊
Results from the ALFWorld navigation benchmark 🏆
An Explainer Video:
MemRL: Sel-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
https://arxiv.org/pdf/2601.03192
Shengtao Zhang 1,∗, Jiaqian Wang 2,* , Ruiwen Zhou 3 , Junwei Liao 1,4 , Yuchen Feng 5 , Weinan Zhang 1,4 , Ying Wen 1,4 , Zhiyu Li 5 , Feiyu Xiong 5 , Yutao Qi 2 , Bo Tang 6,5,†, Muning Wen 1,†
1 Shanghai Jiao Tong University, 2 Xidian University, 3 National University of Singapore, 4 Shanghai Innovation Institute, 5 MemTensor (Shanghai) Technology Co., Ltd., 6 University of Science and Technology of China
A Gentle Slide Deck:
Let's Dive In...
1.0 Introduction: Addressing the Stability-Plasticity Dilemma
A central challenge in the development of advanced Artificial Intelligence (AI) agents is the "stability-plasticity dilemma." This fundamental trade-off forces a difficult choice between retaining stable, pre-existing knowledge (stability) and adapting to new information by acquiring new skills (plasticity). Achieving a balance is critical for creating agents that can learn and evolve without compromising their core competencies.
Conventional approaches have struggled to resolve this dilemma effectively. Fine-tuning, a common method for updating model knowledge, is not only computationally expensive but also highly susceptible to "catastrophic forgetting," where the process of learning new information overwrites and destroys previously acquired knowledge. On the other hand, non-parametric alternatives like standard Retrieval-Augmented Generation (RAG) offer stability by keeping the model's core parameters fixed. However, RAG is a fundamentally passive system; it retrieves information based solely on semantic similarity and lacks any mechanism to evaluate the actual utility or effectiveness of the retrieved context. It cannot distinguish between a helpful past experience and a superficially similar but ultimately useless one.
MEMRL (Memory-Augmented Reinforcement Learning) introduces a novel framework designed to resolve this dilemma. It enables continuous learning and adaptation in AI agents by applying reinforcement learning to an external, evolving memory, all while keeping the Large Language Model's (LLM) core parameters frozen. This innovative approach decouples stable reasoning from adaptive learning, allowing an agent to improve its performance through experience without the risks associated with direct parameter modification. The following sections will explore the core concepts underpinning MEMRL's design and demonstrate its effectiveness.
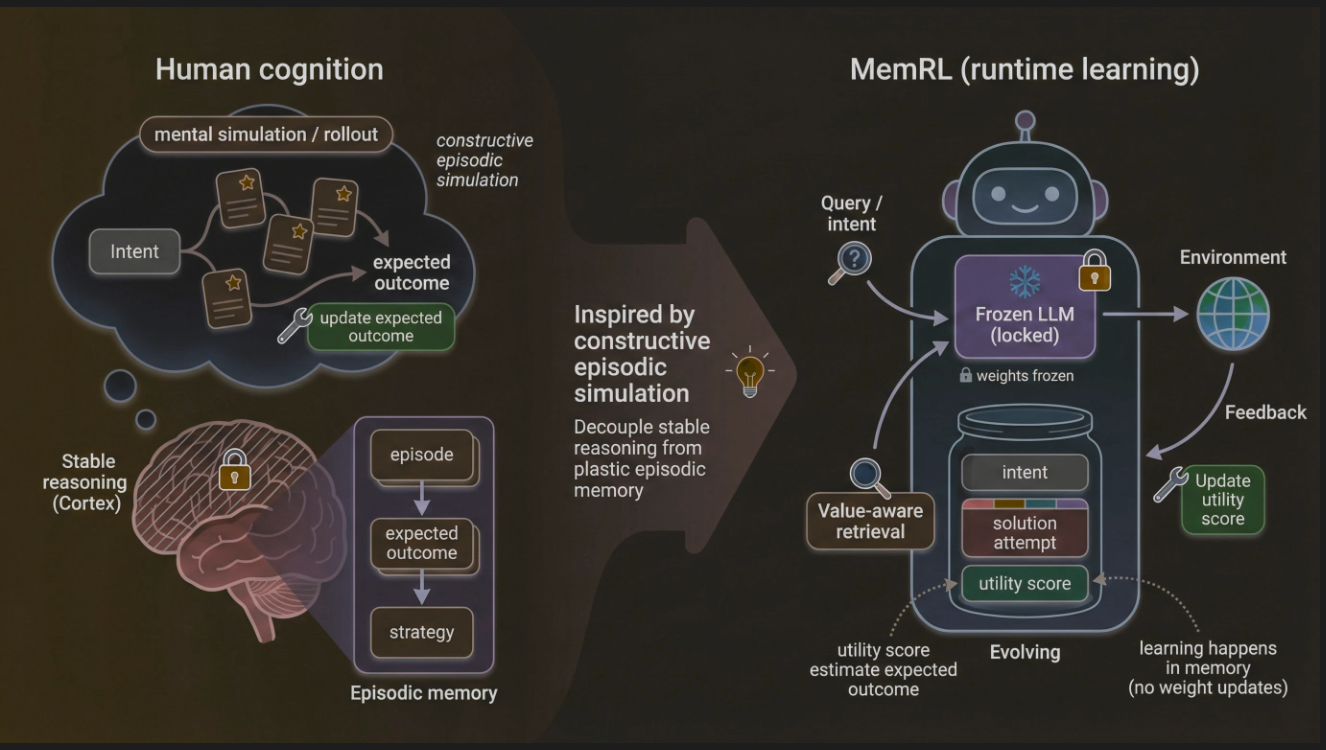
2.0 The Conceptual Framework: Decoupling Reasoning from Memory
The strategic power of MEMRL's design stems from its inspiration from human cognition, specifically the principle of "Constructive Episodic Simulation." In this model of human intelligence, the brain leverages past experiences (episodic memory) to simulate and construct solutions for new challenges. This process is further analogous to memory reconsolidation, where retrieved memories are updated based on new outcomes before being re-stored, providing a biologically plausible foundation for the agent's learning mechanism.
MEMRL's architecture operationalizes this cognitive model by decoupling stable reasoning from plastic memory. It draws a parallel between the stable reasoning of the human cortex and the frozen, locked parameters of its core LLM. This LLM serves as a reliable, unchanging foundation for cognitive tasks. In contrast, the learning and adaptation—the system's plasticity—are confined to an external episodic memory, which evolves and improves over time. The learning process is thus shifted from the model's parameters to this external memory structure.
This decoupling is the core architectural principle that resolves the stability-plasticity dilemma. By ensuring the LLM's weights remain unchanged, MEMRL completely avoids the risk of catastrophic forgetting. The agent's knowledge base and reasoning capabilities remain stable and intact, while its ability to select and apply the right experience for a given task continuously improves. This elegant separation allows the agent to evolve safely and efficiently, paving the way for a detailed examination of the framework's specific architectural components.
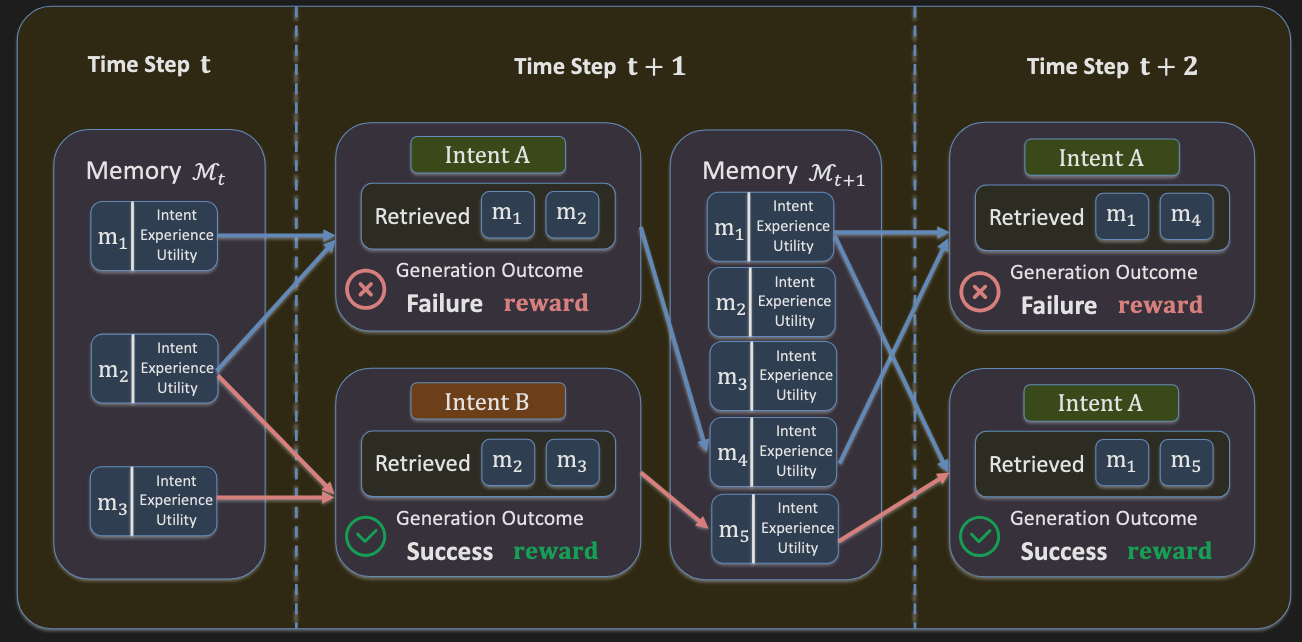
3.0 Architectural Deep Dive: The Mechanics of MEMRL
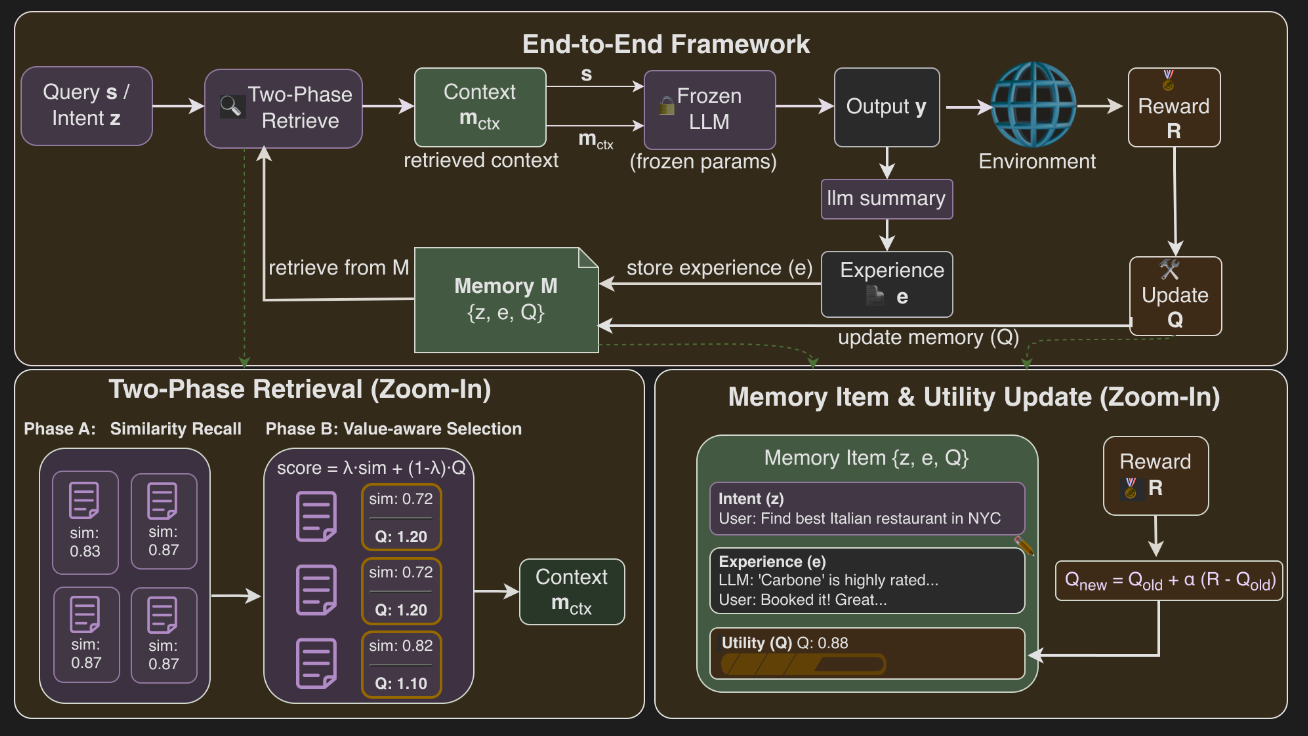
The MEMRL architecture is composed of several strategic components that work in a closed loop to enable continuous, non-parametric learning. This section deconstructs this end-to-end operational cycle, detailing the memory's unique structure, its sophisticated retrieval mechanism, and the reinforcement learning process that drives its evolution.
System Workflow
The MEMRL agent operates in a continuous learning loop that refines its memory based on environmental feedback. The process unfolds as a clear, sequential workflow:
- Query Reception: A query or intent is received.
- Two-Phase Retrieval: The agent performs Two-Phase Retrieval to select context from the memory bank.
- Generation: A Frozen LLM generates an output using the query and retrieved context.
- Environmental Interaction: The agent's action produces an outcome in the environment, which returns a reward signal.
- Memory Update: The reward is used to update the utility score of the retrieved memory items, and the new experience is stored.
Memory Structure: The Intent-Experience-Utility Triplet
MEMRL transforms memory from a simple repository of facts into a dynamic, structured system. Each memory item is an Intent-Experience-Utility Triplet, defined as (z_i, e_i, Q_i).
- Intent Embedding (z_i): The vector representation of the user query or task description that prompted the experience.
- Raw Experience (e_i): The solution trace or action sequence.
- Learned Utility (Q_i): The dynamic Q-value representing the expected utility of the experience.
This triplet structure is the cornerstone of MEMRL's learning capability. By associating each experience with a learned, updateable utility score, the framework ensures that the value of each memory is continuously evaluated based on its real-world effectiveness, not just its semantic content.
The Two-Phase Retrieval Mechanism
To overcome the limitations of passive semantic matching, MEMRL employs a deliberate Two-Phase Retrieval architecture designed to filter for contextual relevance before optimizing for proven utility.
Phase A: Similarity-Based Recall
The first phase acts as a coarse filter to identify a pool of contextually relevant memories. Given a new query, the system calculates the cosine similarity between the query and all intent embeddings (z_i) in the memory bank. It then forms a candidate pool (C(s)) containing the top-k₁ memories that also exceed a minimum similarity threshold (δ). This step efficiently narrows the search space to a manageable subset of semantically appropriate candidates.
Phase B: Value-Aware Selection
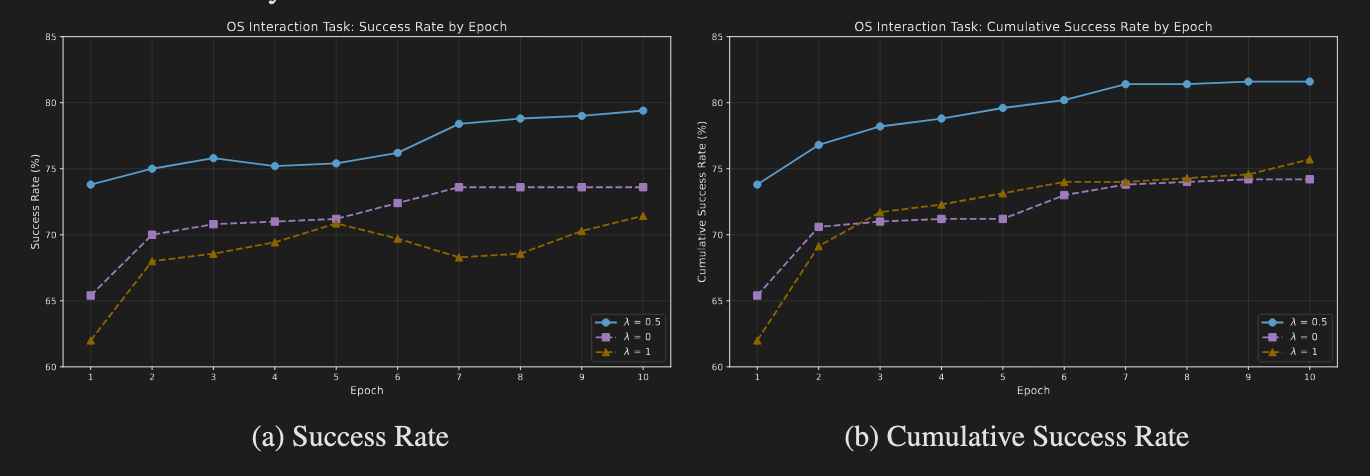
The second phase re-ranks the candidate pool to select memories based on their proven utility. This is achieved using a composite scoring function. The score is calculated as score = (1 - λ) · ˆsim + λ · ˆQ, where ˆsim and ˆQ represent the z-score normalized similarity and utility values within the candidate pool. This normalization is architecturally vital as it ensures a fair, apples-to-apples comparison between two metrics on different scales, preventing one from arbitrarily dominating the selection process. The weighting factor λ allows for a tunable balance between exploration (favoring novel but similar memories) and exploitation (favoring memories with high, proven utility).
Runtime Learning: Non-Parametric Reinforcement on Memory
The engine of MEMRL's continuous improvement is its runtime learning mechanism, which updates memory utilities based on environmental feedback. After an action is taken and a reward r is received, the Q-values of the memories used in that action are updated via a simple but powerful Monte Carlo-style rule:
Q_new ← Q_old + α[r - Q_old]
In this equation, α is the learning rate. This update incrementally adjusts the memory's utility score (Q_old) toward the empirical reward (r) that was actually received. Over time, this process drives the Q-values to accurately reflect the true expected returns of using a particular memory, allowing the agent to "remember what works" and prioritize successful strategies. This entire learning process is confined to the memory structure, leaving the LLM's parameters untouched and thus guaranteeing the stability of the core reasoning engine.
4.0 Theoretical Foundations and Stability Guarantees
Beyond its innovative architecture, MEMRL's reliability is grounded in a solid theoretical framework that ensures stable and convergent learning. This section formalizes the learning problem and presents the mathematical guarantees that underpin the system's performance, preventing the erratic behavior that can plague heuristic-based learning systems.
Formulation as a Memory-Based Markov Decision Process (M-MDP)
The agent's behavior is formally modeled as a Memory-Based Markov Decision Process (M-MDP). In this formulation, the agent's policy is decomposed into two distinct components:
- Retrieval Policy (
μ(m|s_t, M_t)): This policy determines which memorymto select from the memory bankM_tgiven the current states_t. - Inference Policy (
p_LLM(y_t|s_t, m)): This is the frozen LLM's policy for generating an outputy_tbased on the state and the retrieved memorym.
MEMRL's key innovation is to focus its optimization efforts exclusively on the retrieval policy. By learning which memories to retrieve, the agent can adapt its behavior and improve its performance without ever altering the stable, pre-trained inference policy of the LLM.
Stability and Convergence Guarantees
MEMRL's learning process is not merely heuristic; it comes with strong theoretical guarantees of stability and convergence.
- Convergence of Utility Estimates: The core stability result, formally stated in Theorem 1 of the source research, proves that under realistic assumptions (such as a stationary reward distribution), the Q-value estimates are guaranteed to converge in expectation to the true mean reward for a given memory. This ensures that the learned utilities are accurate and meaningful reflections of a memory's actual value.
- Bounded Variance: The theoretical analysis also shows that the variance of the Q-value estimates remains bounded over time. This is critical for stability, as it prevents unbounded oscillations in utility scores and ensures that the system tracks a memory's effectiveness smoothly.
- Convergence via Generalized Expectation-Maximization (GEM): The entire learning loop can be understood as a Generalized Expectation-Maximization (GEM) process. The system alternates between two steps: policy improvement (the value-aware selection of memories) and value updates (updating Q-values based on rewards). This alternating optimization is mathematically guaranteed to converge to a stationary point where the retrieval policy stabilizes. This convergence is the key mechanism that prevents catastrophic forgetting, as it ensures the system finds and settles on a stable, effective strategy for memory usage rather than drifting unpredictably.
These theoretical guarantees are not just academic; they are validated through the extensive empirical testing discussed in the next section.
5.0 Empirical Validation and Performance
To validate its theoretical promises, the MEMRL framework was subjected to rigorous empirical testing across a wide range of complex tasks. The results provide clear evidence of its effectiveness, demonstrating superior performance and generalization capabilities compared to existing state-of-the-art methods.
Benchmark and Baseline Overview
The evaluation was conducted on four diverse benchmarks, each designed to test a different facet of agentic intelligence:
- BigCodeBench: A benchmark for complex code generation.
- ALFWorld: An embodied navigation environment requiring multi-step, procedural reasoning.
- Lifelong Agent Bench: A suite of tasks involving interaction with operating systems (OS) and databases (DB).
- Humanity's Last Exam (HLE): A test of complex, multidisciplinary reasoning.
MEMRL's performance was compared against several categories of baseline methods, including standard RAG-based approaches (RAG, Self-RAG) and other agentic memory frameworks like MemP, which focuses on procedural memory distillation.
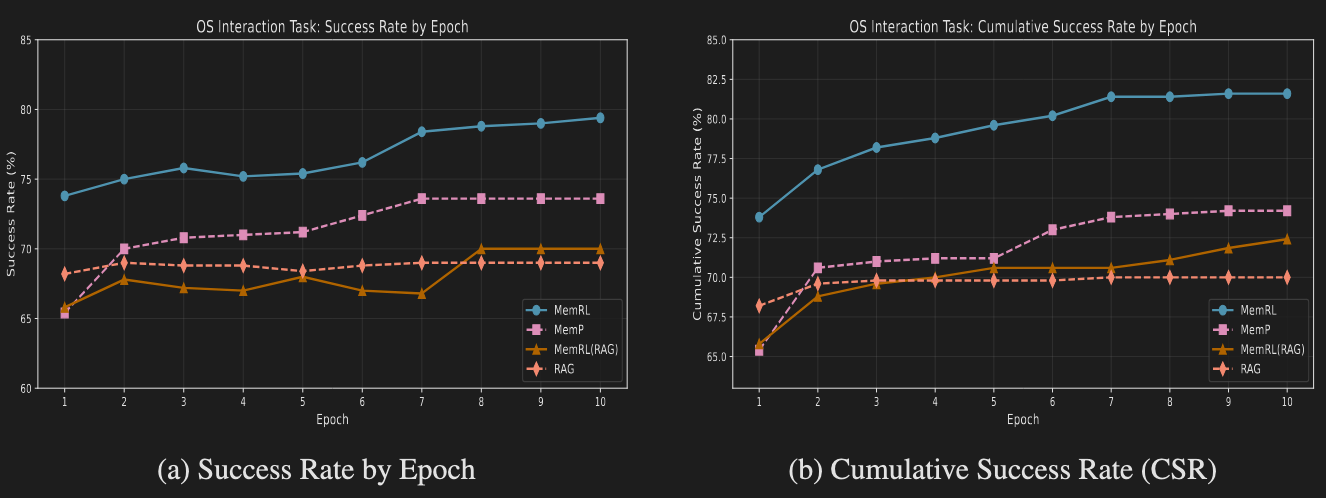
Analysis of Runtime Learning Performance
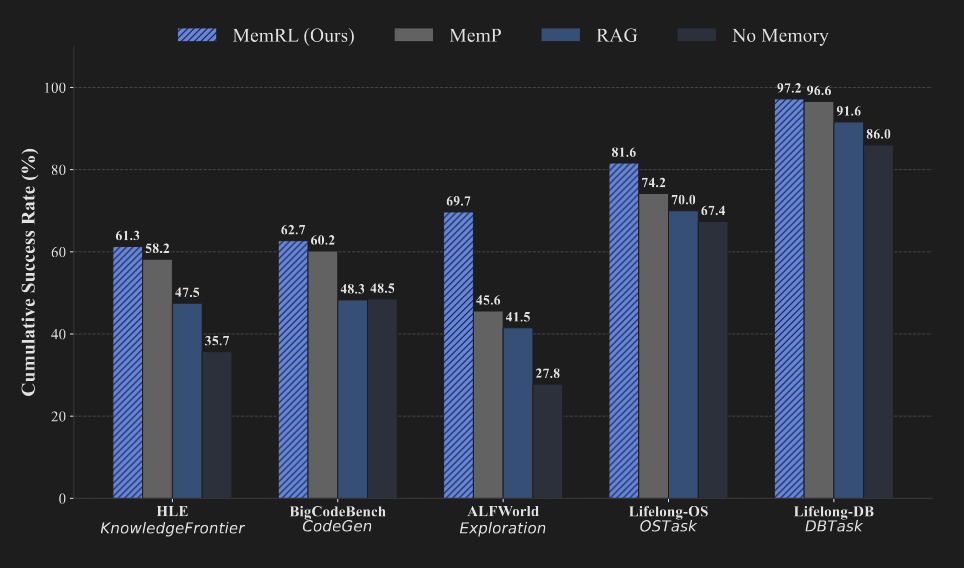
MEMRL consistently outperformed all baselines in runtime learning, as measured by the Cumulative Success Rate (CSR), which indicates the percentage of tasks solved at least once during training.
Benchmark | MEMRL (CSR %) | MemP (CSR %) | RAG (CSR %) |
HLE | 61.3 | 58.2 | 47.5 |
BigCodeBench | 62.7 | 60.2 | 48.3 |
ALFWorld | 69.7 | 45.6 | 41.5 |
Lifelong-OS | 81.6 | 74.2 | 70.0 |
Lifelong-DB | 97.2 | 96.6 | 91.6 |
The results clearly show MEMRL's superiority across all domains. The most significant performance gain was observed in the ALFWorld benchmark, where MEMRL achieved a 69.7% CSR. In last-epoch accuracy, a critical measure of final learned performance, MEMRL demonstrated a 56% relative improvement over MemP. This highlights the framework's exceptional effectiveness in learning and transferring procedural knowledge in exploration-heavy and structurally complex environments.
Analysis of Transfer Learning and Generalization
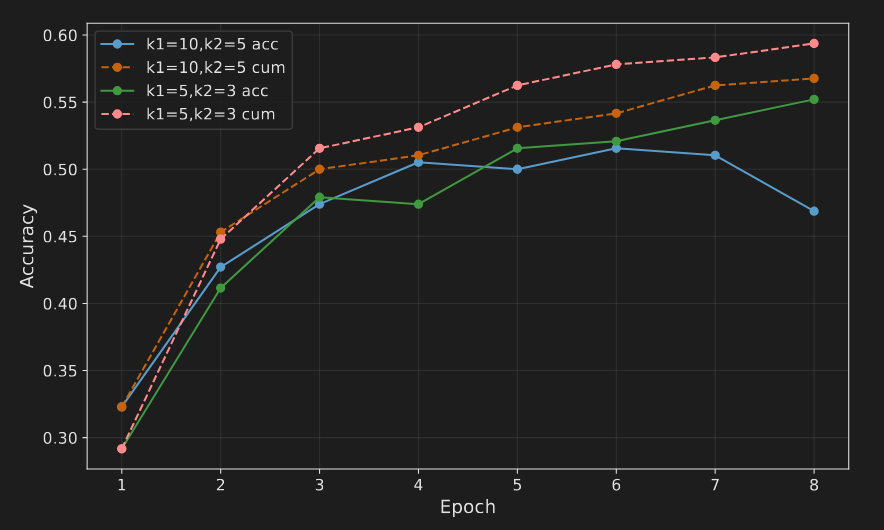
Beyond runtime learning, MEMRL also exhibited superior generalization. In this evaluation, the memory bank learned during training was frozen and tested on a set of unseen tasks. Even without further adaptation, the high-utility memory curated by MEMRL provided a significant performance advantage.
For instance, on the BigCodeBench transfer task, MEMRL achieved the highest accuracy of 0.508. Similarly, on the Lifelong Agent Bench OS tasks, it reached an accuracy of 0.746, outperforming all baseline methods. These results validate that MEMRL does not simply overfit to its training experiences. Instead, it learns to identify and retain high-utility strategies that are robust and generalizable to novel problems. The performance data provides a clear mandate to dissect the underlying reasons for this success.
6.0 Dissecting the Performance: Key System Insights
Moving beyond raw performance metrics, an analysis of MEMRL's behavior reveals the specific mechanisms that drive its success. These insights explain why the framework is so effective, particularly in resolving long-standing challenges in agentic AI.
MEMRL as a Trajectory Verifier in Multi-Step Tasks
The performance gains from MEMRL are most profound in tasks requiring complex, multi-step sequential actions, such as ALFWorld, where it achieved a 24.1 percentage point gain over the MemP baseline. This is because MEMRL functions as a powerful "Trajectory Verifier." Standard semantic retrieval might find a memory that matches the initial step of a task but leads to a dead end later. MEMRL's (Intent, Experience, Utility) triplet structure enables this verification; by propagating the final task reward back to the Utility (Q_i) score, MEMRL learns to rate an Experience (e_i) based on its ability to fulfill a specific Intent (z_i), which requires the structural integrity of the complete solution trajectory.
The Predictive Power of Learned Q-Values
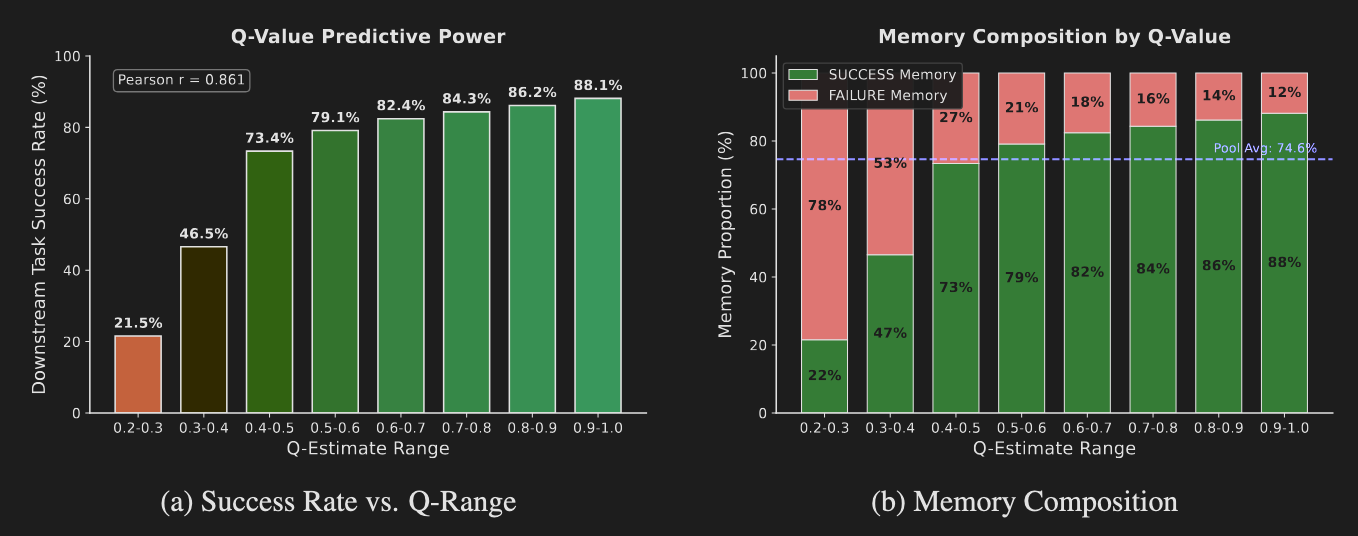
The learned Q-values are not arbitrary numbers; they are highly predictive of actual task success. Analysis revealed a strong positive correlation (Pearson r = 0.861) between a memory's Q-value and the empirical success rate of tasks that used it. This confirms that the internal critic is accurately identifying and ranking memories by their likelihood of leading to a successful outcome.
Critically, this analysis also uncovered the strategic value of "near-miss" failures. Even the highest-Q memory pools contain a small fraction (~12%) of experiences from failed tasks. These are not system errors but trajectories that encode valuable, transferable corrective heuristics. This demonstrates that MEMRL's utility function learns a nuanced representation of value beyond simple binary success, retaining experiences that encode high-value corrective heuristics. This is a key differentiator from simpler success-replay memory systems.
Resolving the Stability-Plasticity Dilemma
This empirical stability is a direct validation of the theoretical convergence guarantees established by the Generalized Expectation-Maximization (GEM) framework discussed in Section 4.0. MEMRL provides a robust, empirically verified solution to catastrophic forgetting. In long-term training, MEMRL achieves a lower mean forgetting rate (0.041) compared to the MemP baseline (0.051). While heuristic-based systems often see performance degrade as new experiences overwrite effective old ones, MEMRL maintains stable, synchronized growth in both cumulative and current-epoch success.
This stability is not accidental; it is mathematically enforced. As described in the source, the value update process benefits from the Bellman contraction property, which guarantees that the estimation error shrinks at each step, ensuring convergence rather than heuristic drift. The importance of the architectural design is further validated by ablation studies: removing key components like z-score normalization and the strict similarity gate causes the forgetting rate to spike, confirming their crucial role in filtering noise and ensuring stable, productive evolution.
7.0 Conclusion: A New Paradigm for Self-Evolving Agents
The MEMRL framework offers a robust, efficient, and theoretically grounded solution to the stability-plasticity dilemma, one of the most persistent challenges in AI development. By reframing memory retrieval as a value-based decision process governed by reinforcement learning, MEMRL enables agents to learn continuously from experience without the high costs and inherent risks of modifying the core model's parameters.
The primary advantages of the MEMRL framework can be summarized as follows:
- Non-Parametric Learning: Enables continuous improvement without costly and risky weight updates to the core LLM.
- Guaranteed Stability: Solves the catastrophic forgetting problem through a theoretically grounded approach that ensures convergence.
- Superior Performance: Empirically validated across diverse and complex domains, especially those requiring multi-step, procedural reasoning.
Ultimately, MEMRL provides a blueprint for a new class of self-evolving agents, moving the industry beyond static models and toward systems that learn, adapt, and improve continuously and safely through real-world interaction.
fin...