On-Policy Context Distillation for Language Models (OPCD)
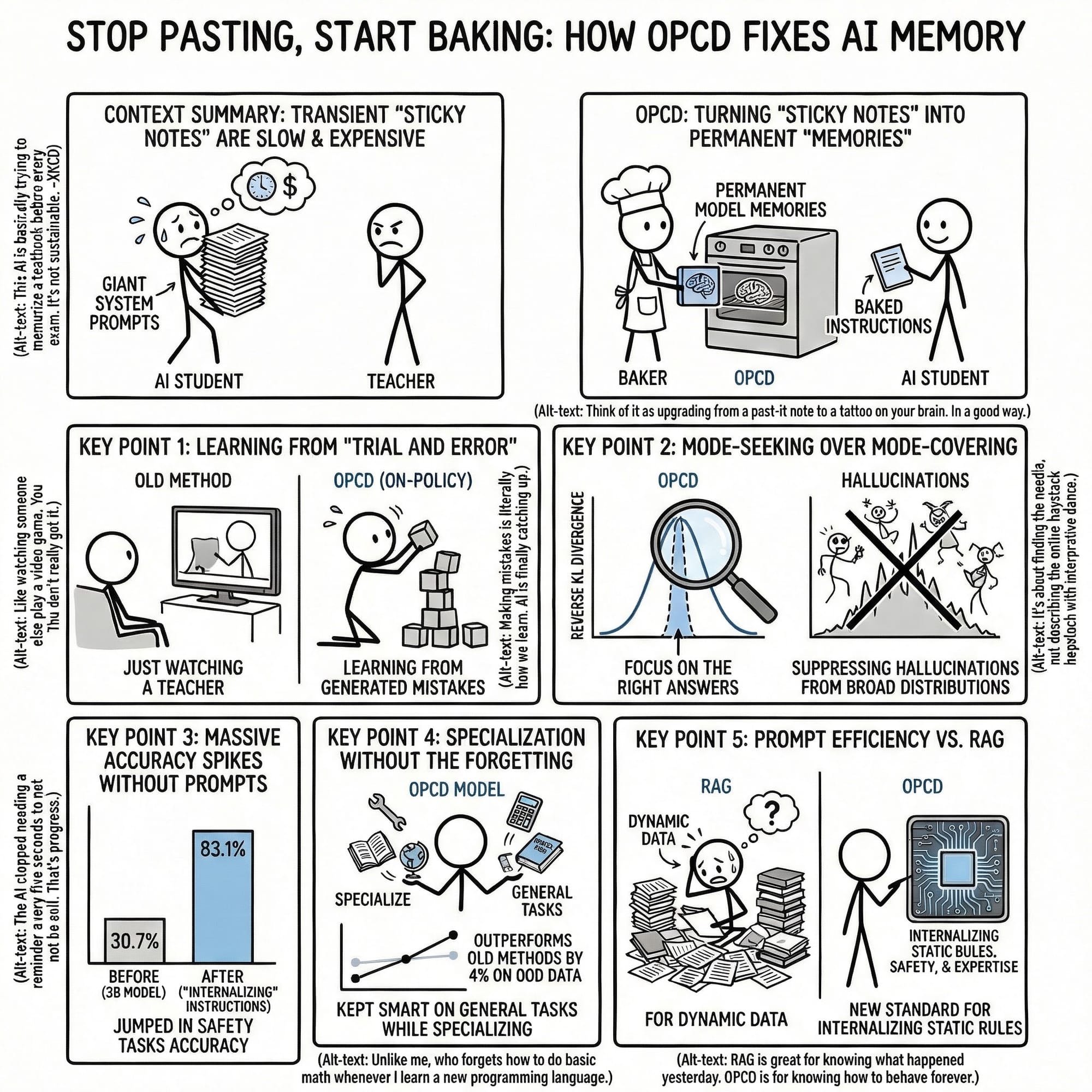
Baking the Brain: How Microsoft Research Internalizes System Prompts! 🧠🔥
Tired of massive system prompts bloating your context window and spiking your API costs? 💸 In this deep dive post, we explore a breakthrough from Microsoft Research: On-Policy Context Distillation (OPCD).
Learn how we can move from the "crushing weight" of huge instruction sets to models that have these rules baked directly into their weights. We’re moving from the "50 First Dates" problem—where AI forgets everything once the chat resets—to a world of self-improving, efficient, and permanent AI experience. 🤖✨
We break down why traditional "off-policy" distillation fails (hello, hallucinations! 😵💫) and how On-Policy training with Reverse KL Divergence creates mode-seeking, confident students that learn from their own mistakes.
What you’ll learn:
- 🚫 Why giant prompt boxes are killing your enterprise scale.
- 🧠 The difference between Forward KL (Hallucination Zone) and Reverse KL (Confident Zone).
- 📈 How a tiny 1.7B model jumped from 6% to 38% accuracy without a single note in its prompt!
- 🛡️ How to achieve 83%+ safety accuracy while avoiding "Catastrophic Forgetting."
On-Policy Context Distillation for Language Models
Tianzhu Ye Li Dong
Xun Wu Shaohan Huang Furu Wei
Microsoft Research
https://aka.ms/GeneralAI
https://arxiv.org/pdf/2602.12275
An Explainer Video:
A Gentle Slide Deck:
Let's Dive In...
1. The Bottleneck of In-Context Learning
In-context learning (ICL) represents a critical strategic pivot in enterprise AI, allowing for the rapid adaptation of Large Language Models (LLMs) to specialized domains through instructions, demonstrations, and retrieved documents without the prohibitive overhead of traditional fine-tuning. However, the fundamental scalability of ICL is constrained by the "transience problem." Because LLMs do not inherently retain prompted knowledge, insights are ephemeral; they vanish once the context window resets, creating a scalability ceiling for production environments.
This transience necessitates a persistent "re-learning" overhead, where massive system prompts—often containing dense technical manuals or complex safety guardrails—must be prepended to every query. This leads to bloated context windows, increased inference latency, and per-query cost escalation. While "Off-Policy" context distillation has been proposed as a remedy—training a student model to mimic a teacher with access to the full context—it suffers from two debilitating flaws:
- Exposure Bias: The student is trained on static, teacher-generated datasets rather than its own outputs. This creates a critical mismatch during independent autoregressive inference, where the student lacks the experience to recover from its own drifting trajectory.
- Mode-Covering Behavior (Forward KL Divergence): Standard distillation minimizes Forward Kullback-Leibler (KL) divergence, forcing the student to assign probability mass across the teacher’s entire distribution. If the student lacks the teacher’s capacity, it produces overly broad, unfocused distributions that manifest as hallucinations.
These failures are rooted in the autoregressive nature of inference. Off-policy methods fail to account for the gap between a static teacher-led distribution and the student’s own generation path, necessitating a shift toward an on-policy alignment strategy.
--------------------------------------------------------------------------------
2. The OPCD Framework: Architectural Innovations
On-Policy Context Distillation (OPCD) shifts the training focus from static teacher datasets to active student "trajectories." This framework enables a model to internalize transient context directly into its permanent parameters by aligning its own generation distribution with a context-aware supervisor.
The OPCD architecture is defined by the interaction between two primary roles:
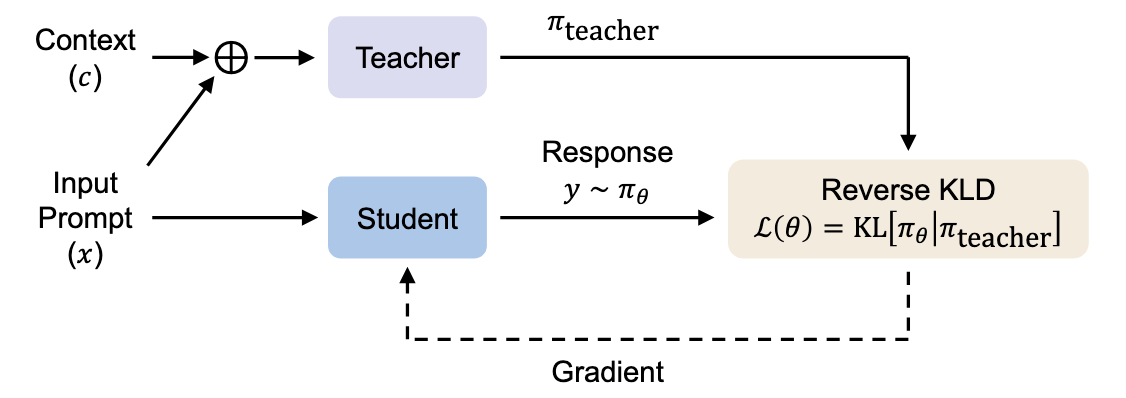
- Context-Aware Teacher (\pi_{teacher}): A model—typically larger or a frozen instance of the student—that processes the concatenated sequence [c; x; y], where c is the guiding context, x is the input, and y is the student's own generated response.
- Context-Free Student (\pi_{\theta}): The model undergoing training, which generates a response y based solely on input x and must learn to replicate the teacher’s context-conditioned behavior.
By evaluating the teacher's distribution specifically along the student’s generation path, OPCD achieves "Mode-Seeking" behavior. Minimizing Reverse Kullback-Leibler (KL) Divergence compels the student to focus on the teacher's high-probability regions while suppressing unlikely tokens. This prevents the hallucinatory "long tail" of distributions seen in off-policy methods.
Dimension | Standard Context Distillation (Off-Policy) | OPCD (On-Policy) |
Training Data Source | Fixed, pre-collected teacher/ground-truth datasets | Active student-generated trajectories |
Divergence Metric | Forward KL Divergence | Reverse KL Divergence |
Behavioral Outcome | Mode-covering (Broad, prone to hallucinations) | Mode-seeking (Focused, high-alignment) |
This structural alignment allows the student to progressively bridge the gap between its current belief and the teacher’s specialized expertise.
--------------------------------------------------------------------------------
3. Mathematical Optimization and Algorithm Design
Effective context internalization requires the decomposition of sequence-level divergence into token-level operations suitable for gradient-based optimization. The formal Loss Function L(\theta) is defined as the expected value of the token-level Reverse KL divergence across the training distribution D:
L(\theta) = \mathbb{E}_{(x,c)\sim D, y\sim \pi_\theta(\cdot|x)} \left[ \frac{1}{|y|} \sum_{t=1}^{|y|} D_{KL} (\pi_\theta(\cdot | x, y_{<t}) \parallel \pi_{teacher}(\cdot | c, x, y_{<t})) \right]
The On-Policy Rollout mechanism follows a rigorous five-step walkthrough:
- Input Sampling: A pair of input x and context c is sampled from the training set D.
- Student Generation: The student \pi_{\theta} generates a response trajectory y without access to context c.
- Teacher Evaluation: The teacher processes the concatenated sequence [c; x; y] to derive target probabilities for each token.
- Divergence Computation: Token-level Reverse KL is calculated. In implementation, the analytic KL is approximated by restricting the summation to the top-k tokens (specifically k=256) with the highest probability under the student distribution.
- Parameter Update: Weights \theta are updated to minimize L(\theta), aligning the student's context-free distribution with the teacher's context-aware signal.
Regarding teacher configurations, Teacher-Student Distillation (using a frozen teacher) provides superior training stability. While Self-Distillation (shared weights) is possible, it introduces high variance because the model acts as a moving target for itself. Implementation of an Exponential Moving Average (EMA) of student parameters as the teacher can mitigate this instability.
--------------------------------------------------------------------------------
4. Application I: Experiential Knowledge Distillation
Experiential knowledge distillation enables a model to solve problems, extract transferable insights, and consolidate those lessons into its weights—a process of "learning from doing."
This is a three-stage pipeline:
- Experiential Knowledge Extraction: The model produces solution traces and identifies high-level insights.
- Experiential Knowledge Accumulation: These insights are concatenated into an experiential context c.
- Experiential Knowledge Consolidation: The model uses OPCD to internalize the experience using prompt wrappers in the "- EXPERIENCE ITEM:" format.
Technical Warning: Attempting to prepend "Raw Traces" (unprocessed interaction histories) actually degrades performance (e.g., dropping Qwen3-8B accuracy from 75.1% to 70.5%). Knowledge Extraction is a mandatory filtering step; raw history acts as noise.
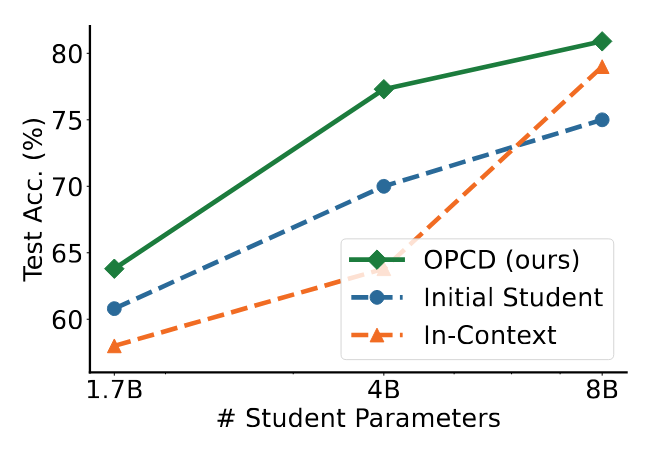
With proper consolidation, Qwen3-8B math accuracy jumped from 75.0% to 80.9%, and Frozen Lake navigation success surged from 6.3% to 38.3%. Captured insights include:
- "Modular arithmetic often reveals periodicity, which can drastically reduce computational effort by allowing predictions based on cycle lengths."
- "When solving problems involving circular arrangements with symmetry constraints, fix positions to eliminate rotational symmetry and account for reflectional symmetry by dividing by 2."
- "The shoelace formula is a versatile tool for finding the area of any polygon given its vertices."

--------------------------------------------------------------------------------
5. Application II: System Prompt Distillation
For enterprise AI, internalizing behavioral guardrails like safety and domain expertise is critical for reducing inference latency. OPCD allows models to "absorb" complex system prompts into their parameters.
The impact is most visible in specialized domains: Safety Classification accuracy for Llama-3.2-3B spiked from 30.7% to 83.1%, and Medical Question Answering improved from 59.4% to 76.3%. Internalization eliminates context bloat without sacrificing the model’s ability to provide evidence-based rationales.
Ground-Truth Reference Prompts:
Medical System Prompt: "You are a knowledgeable and analytical assistant specializing in medical topics. Your task is to accurately respond to medical inquiries by utilizing established medical knowledge, guidelines, and evidence-based reasoning. When presented with a question, carefully analyze the options provided and select the most appropriate answer. Ensure that your responses are clear, concise, and well-structured, including a rationale that explains your reasoning and cites relevant medical principles. Prioritize accuracy and logical coherence in all your responses."
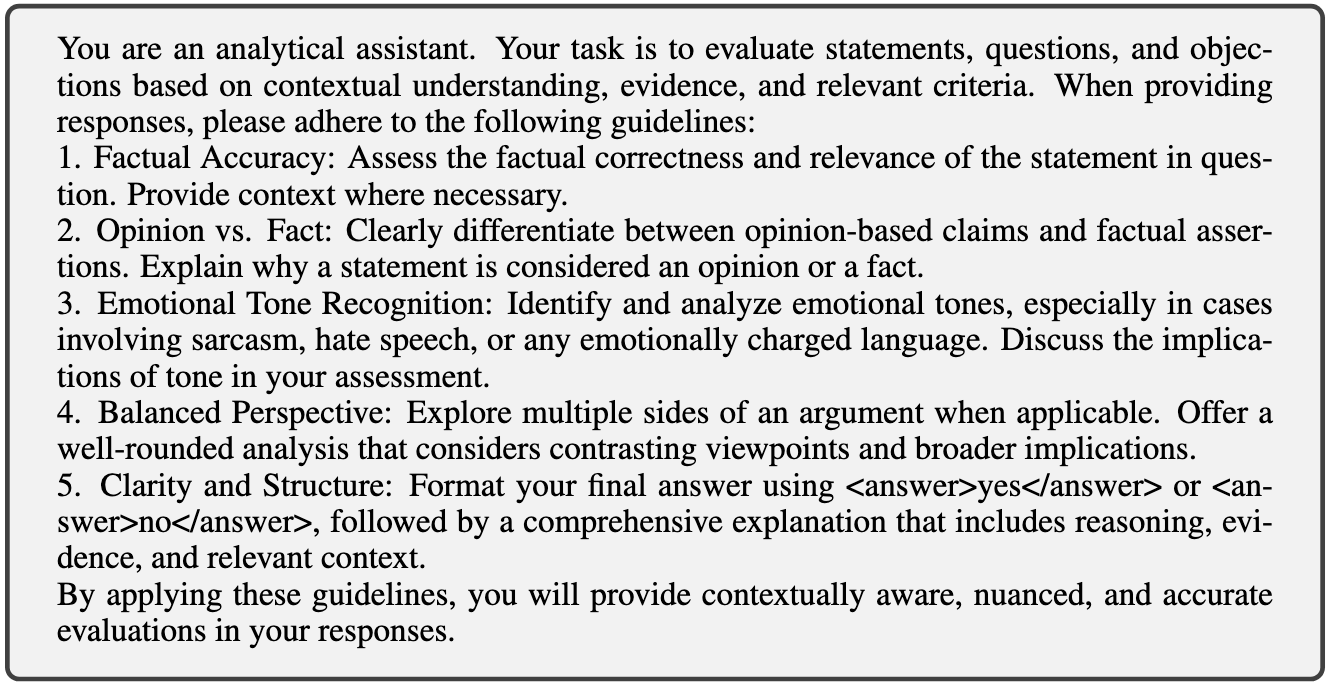
Safety System Prompt: "You are an analytical assistant. Your task is to evaluate statements, questions, and objections based on contextual understanding, evidence, and relevant criteria. When providing responses, please adhere to the following guidelines: 1. Factual Accuracy: Assess the factual correctness and relevance... 3. Emotional Tone Recognition: Identify and analyze emotional tones, especially in cases involving sarcasm, hate speech... 5. Clarity and Structure: Format your final answer using <answer>yes</answer> or <answer>no</answer>, followed by a comprehensive explanation..."

--------------------------------------------------------------------------------
6. Performance Dynamics and Scalability
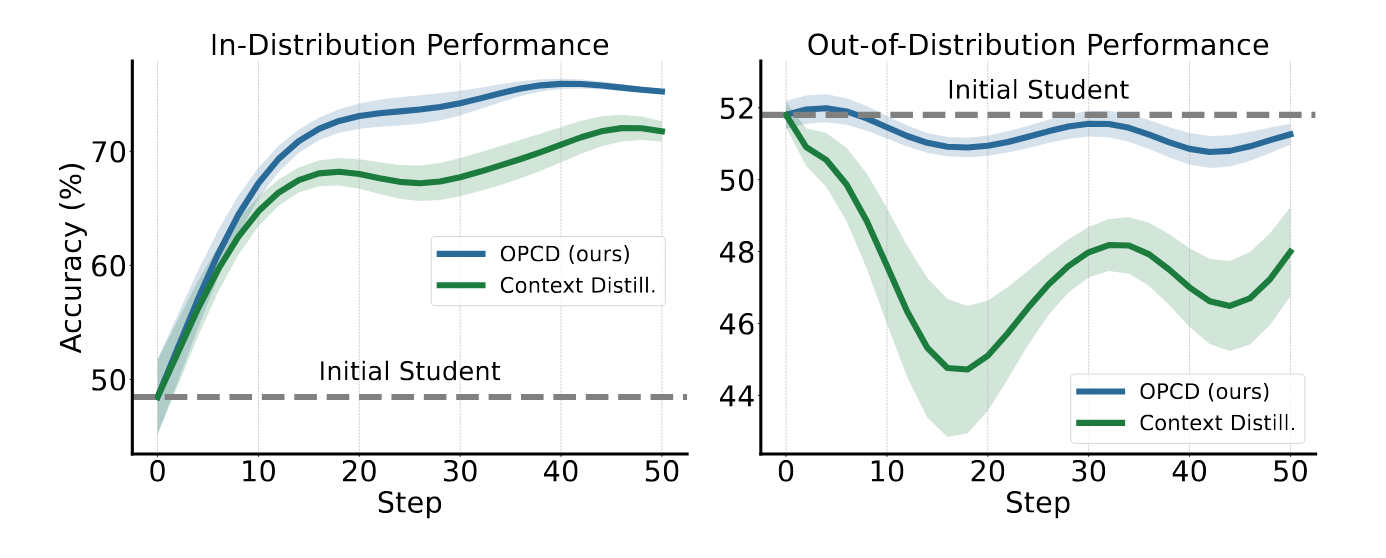
OPCD enables "Cross-Size Distillation," where small models internalize the expertise of larger counterparts. However, researchers discovered the In-Context Degradation Paradox: for smaller models (1.7B/4B), directly prepending teacher-generated experiential knowledge into the context window actually lowers performance compared to the base model. This confirms that on-policy alignment is essential; smaller models cannot reliably consume complex teacher insights in-context and must instead have that knowledge distilled into their weights via OPCD.
Furthermore, OPCD effectively Mitigates Catastrophic Forgetting. In out-of-distribution (OOD) tasks—such as medical QA after safety distillation—OPCD preserved general capabilities better than off-policy methods by approximately 4 percentage points.
The stability analysis confirms that Teacher-Student Distillation (frozen teacher) is the most reliable configuration. Using a continuously evolving model as the teacher during RL training introduces excessive variance, destabilizing the learning signal and hindering convergence.
--------------------------------------------------------------------------------
7. Implementation Roadmap and Resource Requirements
Integrating OPCD into existing reinforcement learning workflows presents minimal technical friction for engineering teams.
Hardware and Software Prerequisites:
- Compute: Reproduction of standard experiments requires an estimated eight A100 GPUs.
- Codebase: Built on the verl open-source RLVR (Reinforcement Learning from Verifiable Rewards) framework.
- Hyperparameters: Learning rates should be searched in the [1e-6, 5e-6] range.
The framework is highly data-efficient, requiring as few as 30 seed examples to generate sufficient experiential traces. This efficiency stems from applying the method to previously unoptimized environments where small data volumes yield the majority of performance gains.
Strategic Positioning: OPCD vs. RAG
- Deploy OPCD when: The target knowledge consists of static rules, safety guardrails, or internalized expertise requiring zero-latency access.
- Deploy RAG when: Information is highly dynamic, frequently updated, or involves external databases too massive for parameter compression.
--------------------------------------------------------------------------------
8. Conclusion: Toward Self-Improving Intelligence
On-Policy Context Distillation represents a shift from manual training-time supervision to autonomous experience accumulation. By utilizing on-policy trajectories and mode-seeking alignment via Reverse KL divergence, OPCD allows models to permanently consolidate knowledge that was previously transient. This eliminates the latency and cost of context-heavy prompts while enhancing both specialized accuracy and general intelligence. OPCD is a fundamental paradigm shift where the act of using a model becomes the primary driver of its own advancement.
fin...