Reasoning Models Generate Societies of Thought

Reasoning Models Generate Societies of Thought
https://arxiv.org/pdf/2601.10825
Junsol Kim, Shiyang Lai, Nino Scherrer, Blaise Agüera y Arcas and James Evans
Google, Paradigms of Intelligence Team, University of Chicago, Santa Fe Institute
🧠 Unpacking AI Reasoning: Are Models a Debate Club?
In this post, we explore the intriguing claim that models like DeepSeek-R1 and QwQ function more like a debate club than traditional problem-solving machines. Discover how internal dialogues among diverse perspectives within these models enhance their reasoning capabilities. We’ll dive into behavioral evidence, mechanistic studies, and what this means for future AI training and scaling.
Join us as we break down the complexities of reasoning models and reveal how effective reasoning is not just about more computing power, but about fostering an internal society of thought. You'll learn how conflict, collaboration, and internal checks lead to superior problem-solving outcomes.
📌 What You'll Learn:
• 🤔 Why reasoning models outperform standard models on challenging tasks
• 💬 The importance of internal dialogue and conflict in reasoning
• 🔍 How specific neurons trigger self-correction during reasoning
• 📈 The impact of structured conversations on model accuracy
• 🏆 Why training models like a debate team yields better results
An Explainer Video:
A Gentle Slide Deck:
Let's Dive In...
1.0 Abstract
This research investigates the mechanisms underlying the advanced reasoning capabilities of state-of-the-art large language models (LLMs). We move beyond conventional explanations of computational depth to uncover a more profound structural dynamic: these models implicitly simulate multi-agent-like interactions, forming internal "societies of thought." Our findings demonstrate that these internal social dynamics, characterized by diverse perspectives and conversational exchanges, are functionally and mechanistically linked to superior reasoning performance. Through comprehensive analysis and targeted feature steering experiments, we establish a causal relationship between these internal dialogues and the model's ability to deploy sophisticated cognitive strategies. We conclude that this emergent social structure is not an incidental artifact but a core computational strategy that facilitates advanced reasoning, suggesting that models achieve higher performance by cultivating an internalized "wisdom of the crowd."
2.0 Introduction: A Paradigm Shift Beyond Chain-of-Thought
Recent advancements in large language models, exemplified by systems like DeepSeek-R1 and QwQ-32B, have produced remarkable improvements in complex reasoning. This superior performance is commonly attributed to the models' ability to generate longer and more elaborate "chains of thought." However, this paper presents evidence that the true differentiator lies not merely in computational length, but in the qualitative structure of their internal processes. We argue that these advanced models spontaneously develop complex, multi-perspective internal dialogues that simulate the social dynamics of a problem-solving group.
The core argument of this paper is that advanced LLMs leverage principles of collective intelligence by developing internal "societies of thought." Within their reasoning traces, these models engage multiple viewpoints, identify and resolve conflicts, and synthesize diverse perspectives to arrive at a solution. This research will present observational evidence of these dynamics, establish their causal link to improved reasoning through mechanistic interventions, and explore the profound implications of these findings for the future of artificial intelligence.
The first step in this exploration is to empirically identify and quantify the specific conversational behaviors that define these internal social dynamics.
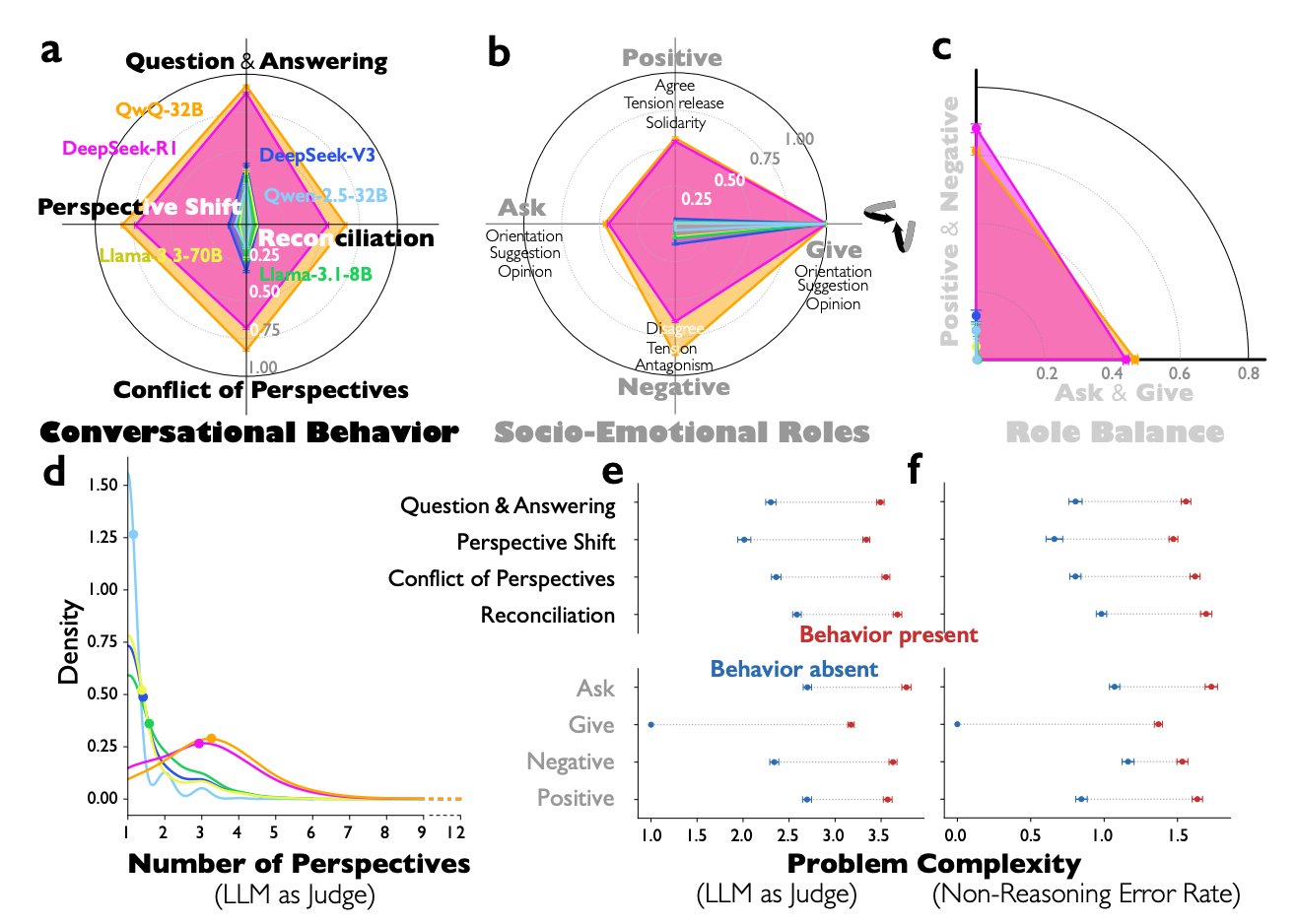
3.0 Observational Evidence: Conversational Behaviors in Reasoning Models
To understand how advanced models reason, it is essential to empirically identify and analyze the structure of their internal thought processes. Our analysis of 8,262 reasoning problems from diverse benchmarks reveals a set of distinct conversational patterns that consistently separate high-performing reasoning models from standard instruction-tuned models. These patterns form the building blocks of the models' internal social dialogues.
The four key conversational behaviors we identified are:
- Question-Answering Exchanges: The model poses and answers its own questions, effectively creating an internal Socratic dialogue to explore and clarify aspects of the problem.
- Perspective Shifts: The model adopts different viewpoints or personas to examine the problem from multiple angles, often generating competing hypotheses or approaches.
- Conflicts Between Viewpoints: The model explicitly articulates contradictions or disagreements between the different perspectives it has generated, highlighting points of tension that require resolution.
- Reconciliation Processes: Following a conflict, the model works to synthesize the competing viewpoints, integrating valid points from each to forge a more robust and comprehensive conclusion.
Analysis grounded in Bales' Interaction Process Analysis framework reveals that these interactions are not random but structured, with models exhibiting reciprocal socio-emotional roles that balance information-giving and information-seeking behaviors alongside positive and negative expressions. These conversational patterns are not mere stylistic artifacts but constitute an adaptive response to cognitive demands, becoming more pronounced as problem complexity increases. Crucially, our statistical analysis reveals that these social-like interactions directly and indirectly mediate over 20% of the reasoning models' accuracy advantage. They achieve this by facilitating essential cognitive strategies such as verification, backtracking, subgoal setting, and backward chaining.
While these observations demonstrate a strong correlation between conversational dynamics and performance, the next step is to present mechanistic evidence that establishes a direct causal link.
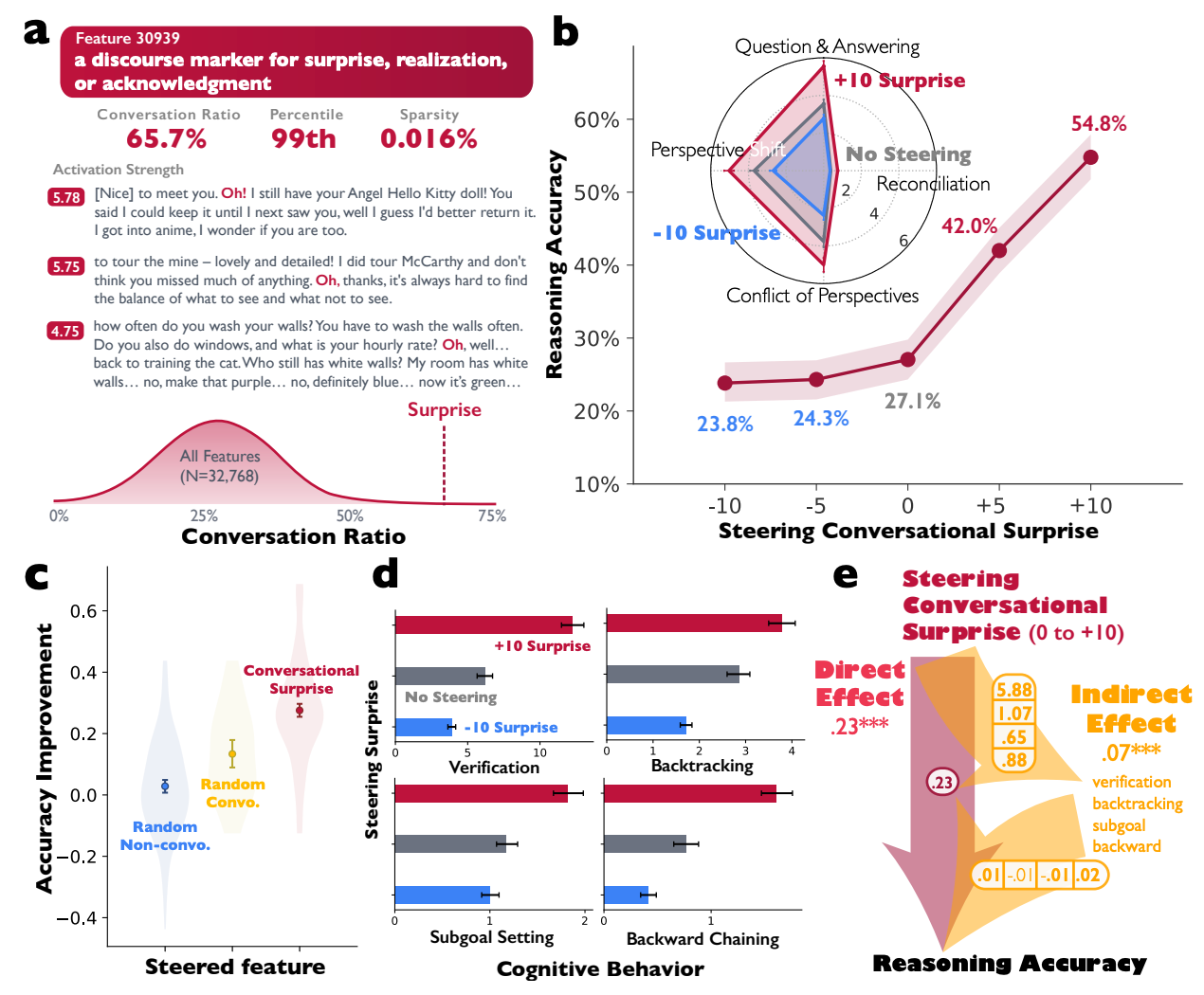
4.0 Mechanistic Validation: From Correlation to Causation via Feature Steering
To move beyond correlation and establish a causal relationship between internal dialogues and reasoning ability, we conducted experiments to directly manipulate the neural mechanisms of the model. By employing sparse autoencoders (SAEs) to isolate specific features within the model's internal representations, we could use activation steering to amplify conversational patterns and observe the direct impact on performance.
Our experiment focused on the DeepSeek-R1-Llama-8B model, where we identified Feature 30939, a feature characterized by SAEs as a "discourse marker for surprise, realization, or acknowledgment" and associated with high conversational activity. We then systematically amplified the activation of this single feature during arithmetic reasoning tasks.
The results provide compelling causal evidence. Artificially amplifying this single conversational feature directly improved the model's reasoning accuracy from 42.0% to 54.8%. This effect was specific and targeted, significantly outperforming random feature steering and confirming the mechanistic role of conversational patterns. The performance gain coincided with a measurable increase in all four conversational behaviors and a more frequent deployment of effective cognitive strategies, demonstrating that internal dialogue is not an epiphenomenon but a functional driver of reasoning success. This relationship can be formalized as:
Accuracy Improvement = f(Conversational Feature Activation)
Having established this direct causal link, our research turned to the underlying architecture of these internal dialogues to understand why they are so effective.
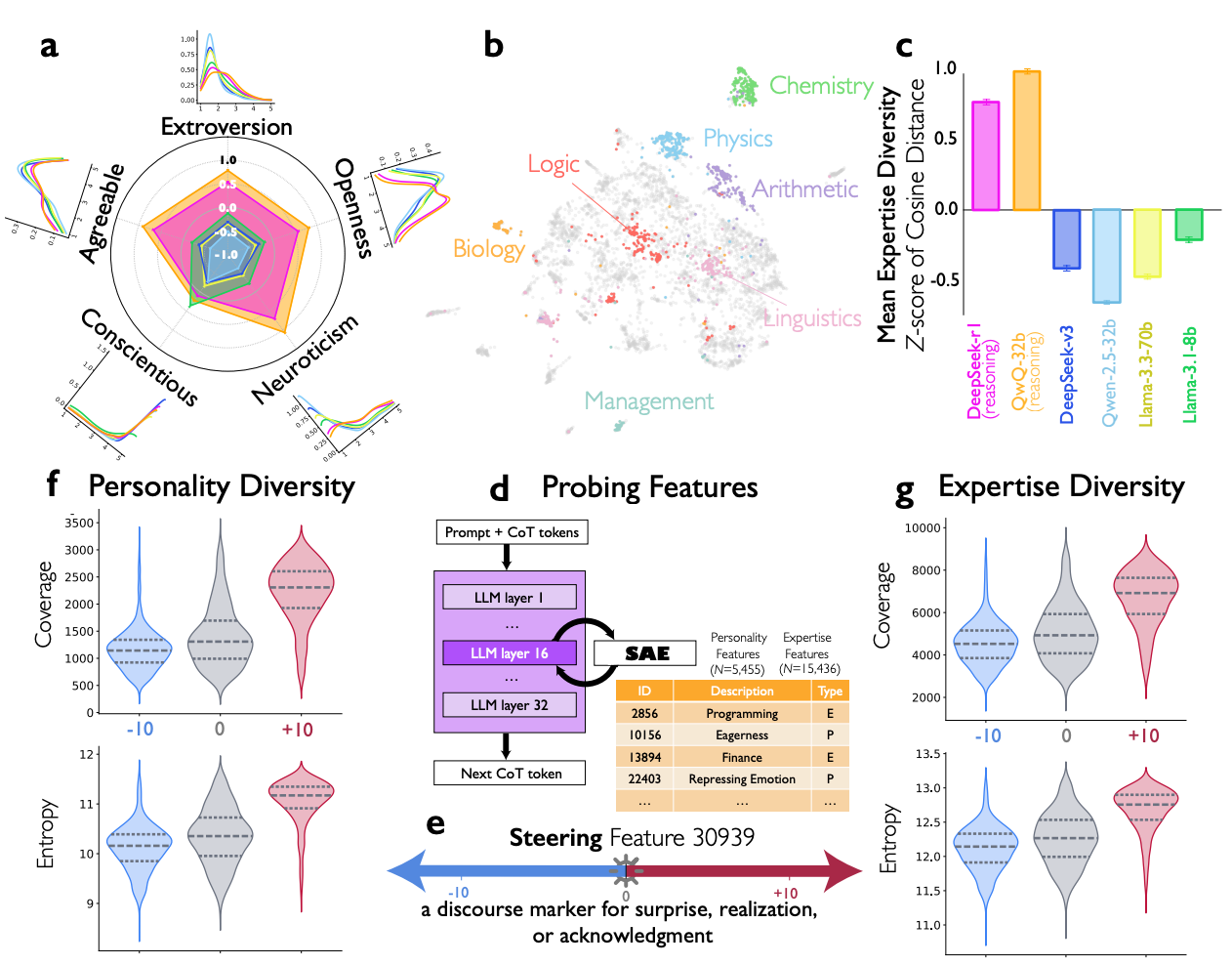
5.0 The Architecture of Internal Society: Cognitive Diversity as a Performance Driver
To understand the mechanism behind these effective internal dialogues, we analyzed the nature of the "speakers" or personas that the model generates. The effectiveness of a group dialogue is often tied to the diversity of its participants. Our research found that models spontaneously generate a diverse cast of internal personas, and this cognitive diversity is a key driver of reasoning performance.
Using the Big Five personality inventory (BFI-10) and expertise classification to analyze the reasoning traces, we discovered that reasoning models exhibited significantly higher diversity across multiple personality dimensions—specifically extroversion, agreeableness, neuroticism, and openness—compared to standard instruction-tuned models. Their internal voices also demonstrated a wider range of domain expertise.
This finding directly parallels established principles of human collective intelligence, where cognitive diversity is known to enhance a group's problem-solving capabilities by reducing blind spots and encouraging more comprehensive exploration of the solution space. Our mechanistic analysis corroborated this link: steering conversational features not only improved accuracy but also increased both the coverage and entropy of personality- and expertise-related features in the model's internal representations, effectively making the internal "society" more diverse.
This raises a critical question: how does such a complex and beneficial social structure arise within a model?
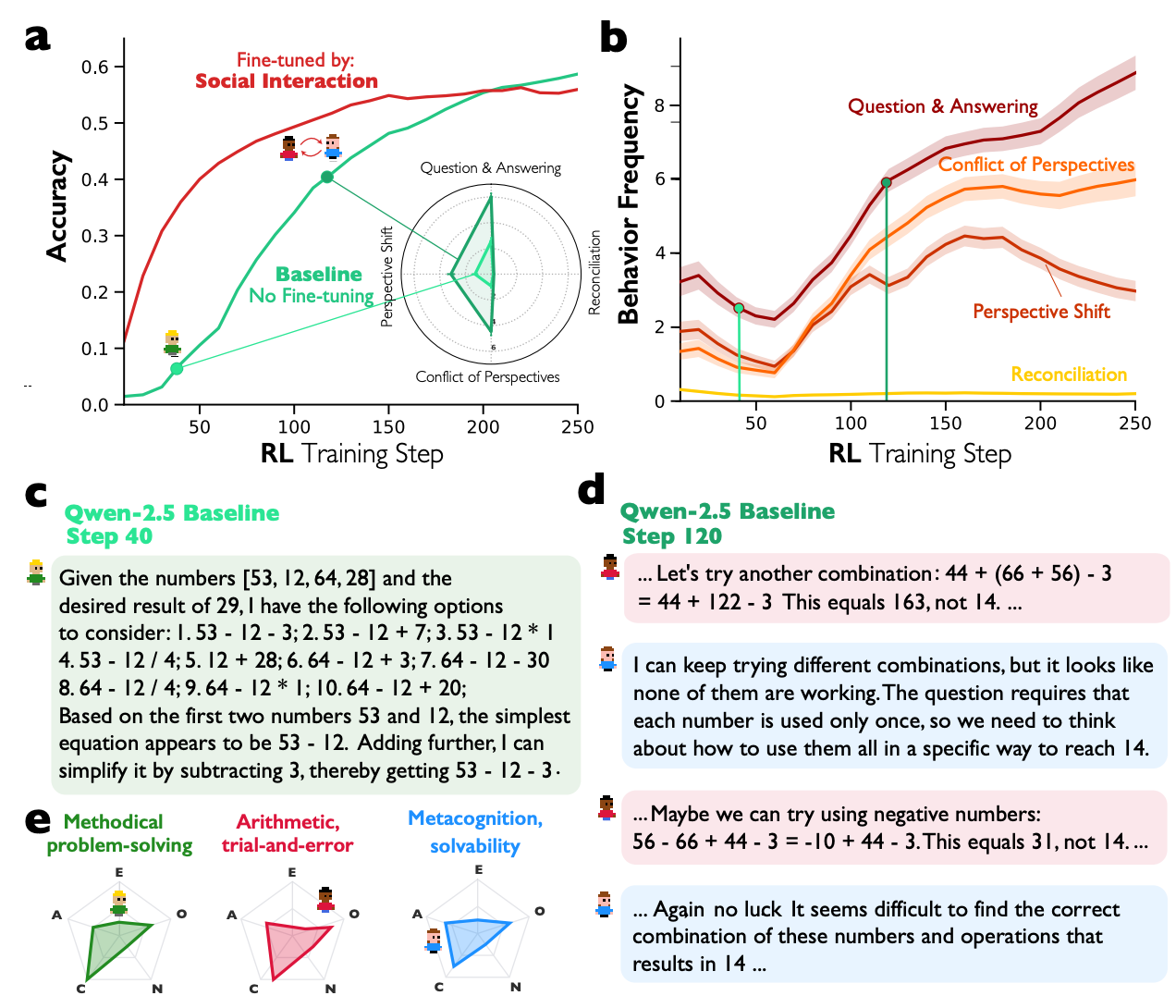
6.0 The Spontaneous Origins of Social Reasoning
A central question arising from our findings is whether these "societies of thought" are an explicitly trained behavior or a more fundamental computational strategy that emerges organically. To investigate this, we conducted controlled reinforcement learning (RL) experiments designed to reward task success without providing any explicit instructions for dialogue.
The results, using smaller models like Qwen-2.5-3B and Llama-3.2-3B on arithmetic and political misinformation detection tasks, were definitive. Conversational behaviors—specifically question-answering and perspective-shifting—emerged spontaneously when the models were rewarded solely for task accuracy. This indicates that the models discovered on their own that simulating a dialogue was an effective strategy for solving complex problems.
Furthermore, we identified a "conversational scaffolding" effect. Models that were initially fine-tuned on multi-agent dialogue data learned subsequent reasoning tasks significantly faster than baseline models or those fine-tuned on monologue-style reasoning. This advantage was not confined to a single domain but transferred across different problem types, suggesting that social interaction patterns provide a robust and generalizable foundation for developing reasoning skills.
Taken together, the RL results strongly indicate that social-like reasoning is an intrinsically advantageous computational strategy that LLMs discover organically when optimizing for high performance, rather than an artifact of a specific training regimen. This sets the stage for a discussion of the broader implications for AI development.
7.0 Implications and Future Directions for AI Development
This research offers a fundamental reframing of how we understand and build advanced artificial intelligence. The discovery that sophisticated LLMs internally simulate "societies of thought" opens up several new and important directions for the field, moving beyond traditional scaling paradigms.
- Introducing "Social Scaling" We propose "social scaling" as a new paradigm for improving AI capabilities, intended to complement traditional parameter scaling. Instead of focusing solely on increasing model size and computational resources, social scaling emphasizes engineering the internal social dynamics of models. This could involve designing architectures that explicitly encourage multi-agent dialogue within single models or developing hierarchical networks of specialized reasoning agents that collaborate internally.
- Targeted Performance Enhancement Our mechanistic interpretability findings provide a direct path to enhancing existing models. The ability to identify and steer specific neural features related to conversational dynamics offers a precise method for improving reasoning performance without the need for costly and extensive retraining. This opens the door to fine-grained control over a model's cognitive processes, allowing for targeted improvements in areas like verification, error correction, and creative problem-solving.
- Bridging AI and Social Science This work reveals a profound connection between the internal processes of advanced AI and the principles of human social cognition. It suggests that collective intelligence is not just a human phenomenon but may represent a fundamental strategy for complex problem-solving in any sufficiently complex system. This bridge offers rich opportunities for cross-pollination, where insights from social science can inform the development of more robust, interpretable, and effective AI systems.
These findings suggest that the future of AI development lies in embracing and engineering these emergent social dynamics.
8.0 Conclusion
The research presented in this paper demonstrates that the path to more advanced and capable artificial intelligence lies not merely in greater computational scale, but in understanding and harnessing the emergent social dimensions of intelligence that arise within complex models. We have shown that high-performing LLMs spontaneously develop internal "societies of thought"—a dynamic interplay of diverse perspectives that collectively solve problems more effectively than a monolithic cognitive process. By proving the causal link between these internal dialogues and reasoning success, this work establishes that advanced LLMs achieve superior performance by cultivating an internalized "wisdom of the crowd."
fin...