Reinforcement Learning via Self-Distillation

https://arxiv.org/pdf/2601.20802
Jonas Hübotter,Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta1, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, Andreas Krause1
ETH Zurich, Max Planck Institute for Intelligent Systems, MIT, Stanford
🚀 Unlocking Reinforcement Learning: The Power of Self-Distillation!
In this post, we delve into the innovative research paper "Reinforcement Learning via Self-Distillation (SDPO)" by Jonas Hübotter and colleagues.
Discover how the SDPO framework addresses the prevalent scalar reward bottleneck in reinforcement learning, transforming rich feedback from the environment into an effective training signal.
We’ll explore the mechanics of how self-distillation enhances the learning process, enabling models to learn from their errors and adapt dynamically.
From improving sample efficiency to leveraging feedback for better performance, this post is packed with insights that can revolutionize your understanding of reinforcement learning.
📌 What You'll Learn:
• The limitations of scalar rewards in reinforcement learning
• How rich feedback can transform error messages into training signals
• The "Hindsight Maneuver" and its role in effective learning
• The impact of self-teaching on model performance and efficiency
An Explainer Video:
A Gentle Slide Deck:
Let's Dive In...
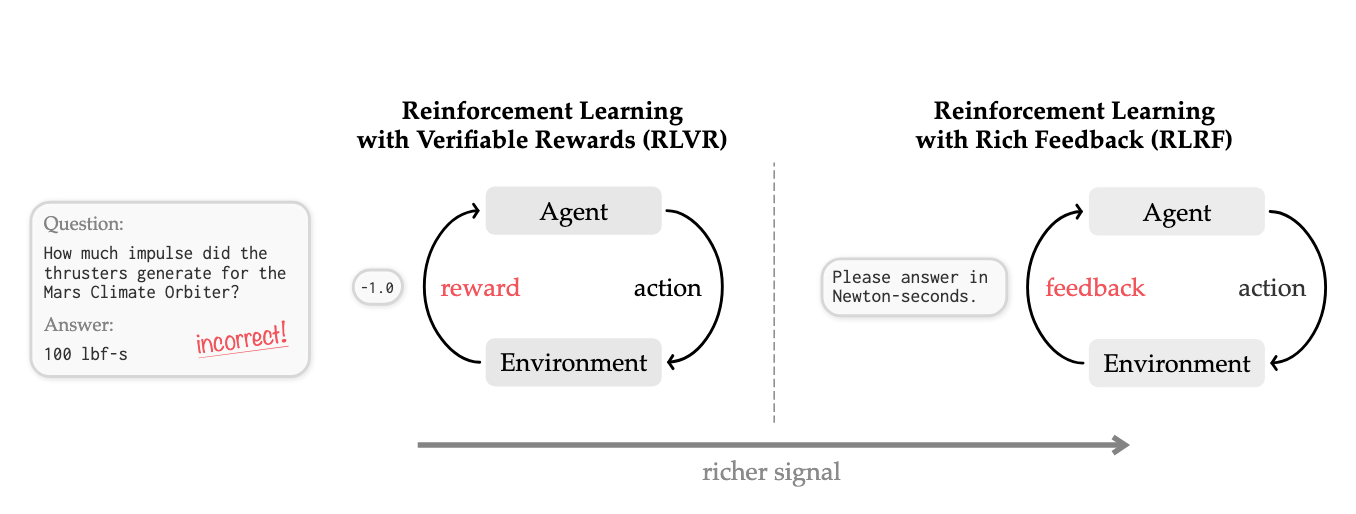
1. The Information Bottleneck in Reinforcement Learning with Verifiable Rewards (RLVR)
The contemporary paradigm for enhancing reasoning capabilities in Large Language Models (LLMs) centers on Reinforcement Learning (RL) within verifiable domains, such as competitive programming and mathematics. By iteratively interacting with an environment, receiving feedback, and updating the policy, models can transcend the limitations of static supervised fine-tuning. However, current post-training architectures are predominantly restricted to the Reinforcement Learning with Verifiable Rewards (RLVR) framework. While effective for basic alignment, RLVR is fundamentally constrained by its reliance on sparse, scalar rewards—often a binary pass/fail signal—which imposes a strategic information bottleneck as we attempt to scale to complex, multi-step reasoning.
1.2 The "Scalar Bottleneck" and Credit-Assignment Crisis
Standard RLVR methods, such as Group Relative Policy Optimization (GRPO), estimate advantages based on these 1-bit or scalar outcomes. This creates a severe credit-assignment crisis: because a single reward is applied uniformly to an entire sequence of tokens, the model lacks the granularity to distinguish between critical logical breakthroughs and catastrophic errors within the same rollout. Furthermore, RLVR frequently suffers from "learning stalls." In difficult tasks where the initial success rate is low, rollout groups often receive identical (zero) rewards, causing advantages to collapse and providing no gradient signal for improvement.
1.3 Comparison: RLVR vs. Reinforcement Learning with Rich Feedback (RLRF)
To address this, we propose a shift to Reinforcement Learning with Rich Feedback (RLRF). Unlike RLVR, which masks the environment state behind a scalar, RLRF utilizes the tokenized feedback already available in many verifiable systems—such as compiler logs, runtime errors, or LLM-judge critiques.
Feature | Reinforcement Learning with Verifiable Rewards (RLVR) | Reinforcement Learning with Rich Feedback (RLRF) |
Learning Signal | Scalar reward r (e.g., binary pass/fail) | Tokenized feedback f (e.g., runtime errors, judge evaluations) |
Information Density | Sparse; masks underlying environment state | Rich; provides diagnostic data on why an attempt failed |
Credit Assignment | Sequence-level; constant reward across all tokens | Token-level; dense and specific to logical mistakes |
Failure Handling | Collapses to zero signal if all attempts fail | Utilizes error messages to guide precise corrections |
This transition necessitates an optimization paradigm capable of transforming high-dimensional textual feedback into a dense, logit-level learning signal.
--------------------------------------------------------------------------------
2. The SDPO Framework: Policy as Self-Teacher
Self-Distillation Policy Optimization (SDPO) leverages a model’s emergent in-context learning (ICL) capabilities to resolve the credit-assignment bottleneck. Rather than relying on an external, compute-heavy teacher model, SDPO treats the current policy as a "Self-Teacher" that can re-evaluate its own performance in hindsight when provided with environmental context.
2.1 The Self-Teacher Mechanism
We define the Self-Teacher as \pi_\theta(\cdot | x, f), which is the current policy prompted with the original question x and the rich feedback f received from the environment. Because the model observes the feedback in-context, it can retrospectively identify which specific tokens led to the error. This transforms the model's next-token distribution, allowing the Self-Teacher to "disagree" with the student’s original choices at a granular, logit level.
2.2 Optimization via Distillation
The SDPO objective minimizes the divergence between the student's next-token distribution and the feedback-informed predictions of the Self-Teacher:
L_{SDPO}(\theta) := \sum_t KL(\pi_\theta(\cdot | x, y_{<t}) \parallel stopgrad(\pi_\theta(\cdot | x, f, y_{<t}))) \text{ (1)}
The stopgrad operator is mathematically vital; it ensures the feedback remains the dominant driver of the signal by preventing the teacher from regressing toward the student’s current (erroneous) distribution.
2.3 Mathematical Intuition: The Negated Gradient
The SDPO gradient functions as a negated logit-level policy gradient. Unlike GRPO advantages, which are constant within a rollout, SDPO advantages are dynamic and token-specific. By minimizing the KL-divergence, the gradient effectively "penalizes" logits that conflict with the hindsight expert knowledge provided by the feedback. This allows for precise credit assignment: tokens the teacher deems more likely after seeing feedback receive positive updates, while tokens identified as errors are suppressed.
--------------------------------------------------------------------------------
3. Algorithmic Implementation and Stability
Implementing dense credit assignment in large-scale models requires meticulous attention to training stability and memory efficiency.
3.1 Regularization and Stability
To prevent the Self-Teacher from diverging too rapidly, we employ two primary regularization strategies:
- Trust-Region Teacher: Uses an explicit KL constraint to keep the teacher close to the initial reference model.
- Exponential Moving Average (EMA) Teacher: Parameterizes the teacher using an EMA of the student's weights, providing a stable, evolving target.
Furthermore, we incorporate Symmetric Jensen-Shannon divergence in the distillation loss. This formulation provides a more balanced distance measure than standard KL, significantly enhancing stability during the on-policy update phase.
3.2 Compute and Memory Efficiency
SDPO introduces a marginal computational overhead (+5.8% to +17.1% time per step) compared to GRPO. To mitigate the memory bottleneck of holding full vocabulary logits for two models, we use Top-K Distillation (e.g., K=100). This captures the most informative parts of the logit shift while drastically reducing GPU memory consumption.
3.3 Hybridization: Monte Carlo vs. Bootstrapped Advantages
For boundary conditions involving weaker models (e.g., Qwen2.5-1.5B), the Self-Teacher's retrospection may be less reliable. In these cases, we utilize a hybrid advantage:
A_{Hybrid} = \lambda A_{GRPO} + (1-\lambda) A_{SDPO} \text{ (2)}
This approach combines Monte Carlo advantages (GRPO), which are unbiased but high-variance, with Bootstrapped advantages (SDPO), which are biased but provide the low-variance, dense feedback required for rapid convergence.

--------------------------------------------------------------------------------
4. Performance Results: Implications of Reasoning Efficiency
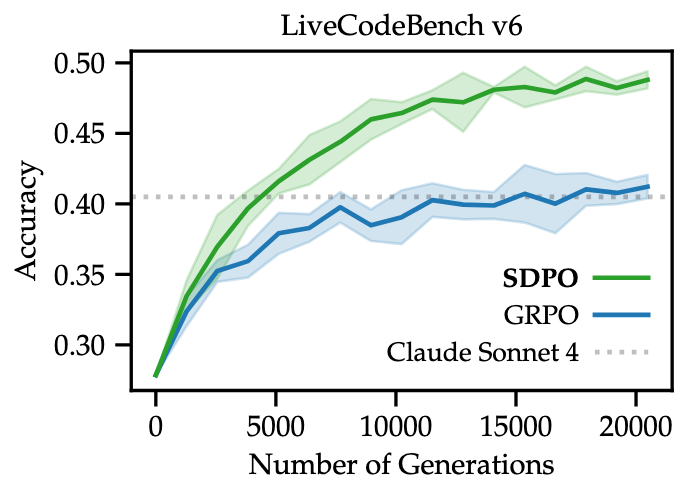
Evaluations across SciKnowEval (science), ToolAlpaca (tool use), and LiveCodeBench v6 (coding) reveal that SDPO is a significantly more sample-efficient paradigm than RLVR.
4.1 Sample Efficiency and Scaling
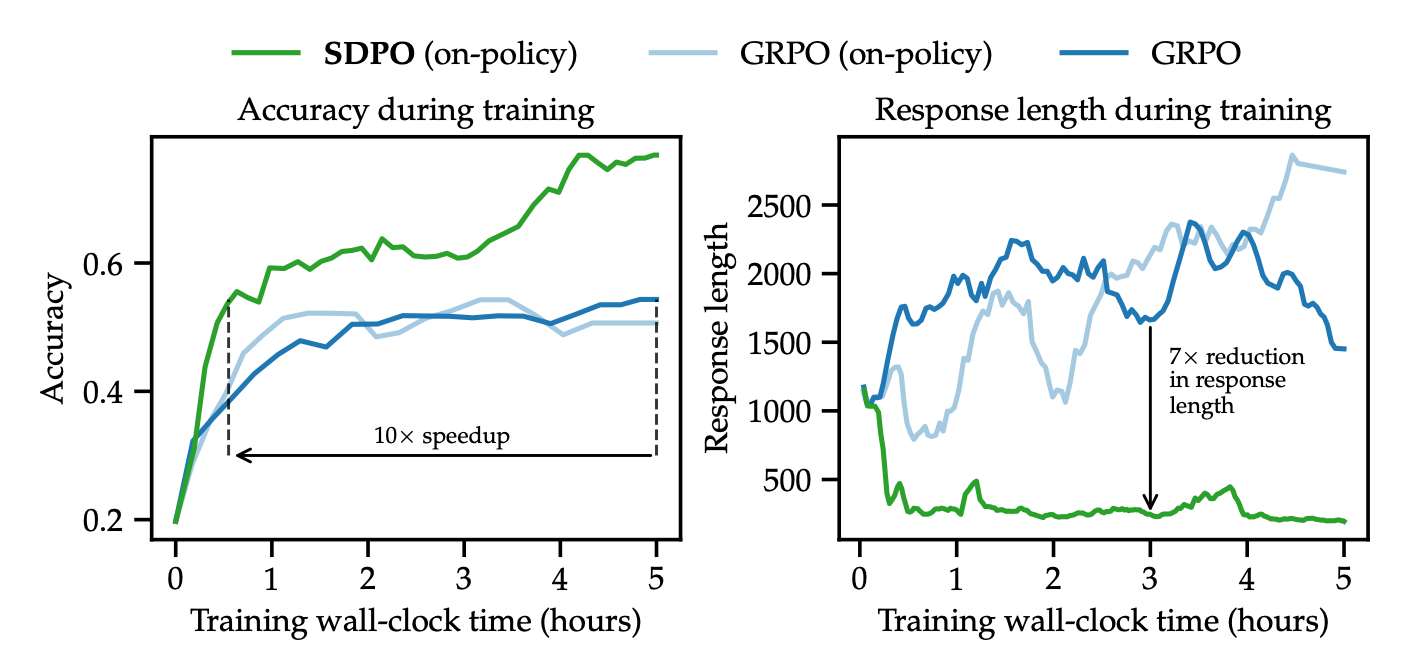
On LiveCodeBench v6, SDPO achieves GRPO’s final accuracy in 4x fewer generations. In Chemistry tasks, it delivers a 10x wall-clock speedup. Notably, SDPO's gains grow with model scale; on Qwen3-8B, it reaches 48.8% accuracy, outperforming the strongest instruct models on the public leaderboard, including Claude Sonnet 4 (40.5%).
4.2 The Conciseness Advantage: Eliminating Superficial Reasoning
A critical qualitative finding is that SDPO produces reasoning paths 3x to 7x shorter than GRPO while maintaining higher accuracy. GRPO tends toward "superficial reasoning," often generating filler phrases to artificially extend thinking time. For example, in a complex Chemistry problem:
- GRPO used filler phrases such as "Hmm" 5x and "Wait" 25x, often entering circular logical loops.
- SDPO produced direct, concise logic, refining the internal reasoning quality rather than the output length.
4.3 Emergence and Boundary Conditions
While SDPO thrives at scale, it exhibits a boundary condition: on very weak models (e.g., Qwen2.5-1.5B), it can underperform GRPO because the model's ICL capacity is insufficient for accurate retrospection. However, as the base model scales, the self-teaching capability emerges as a powerful driver of performance.
--------------------------------------------------------------------------------
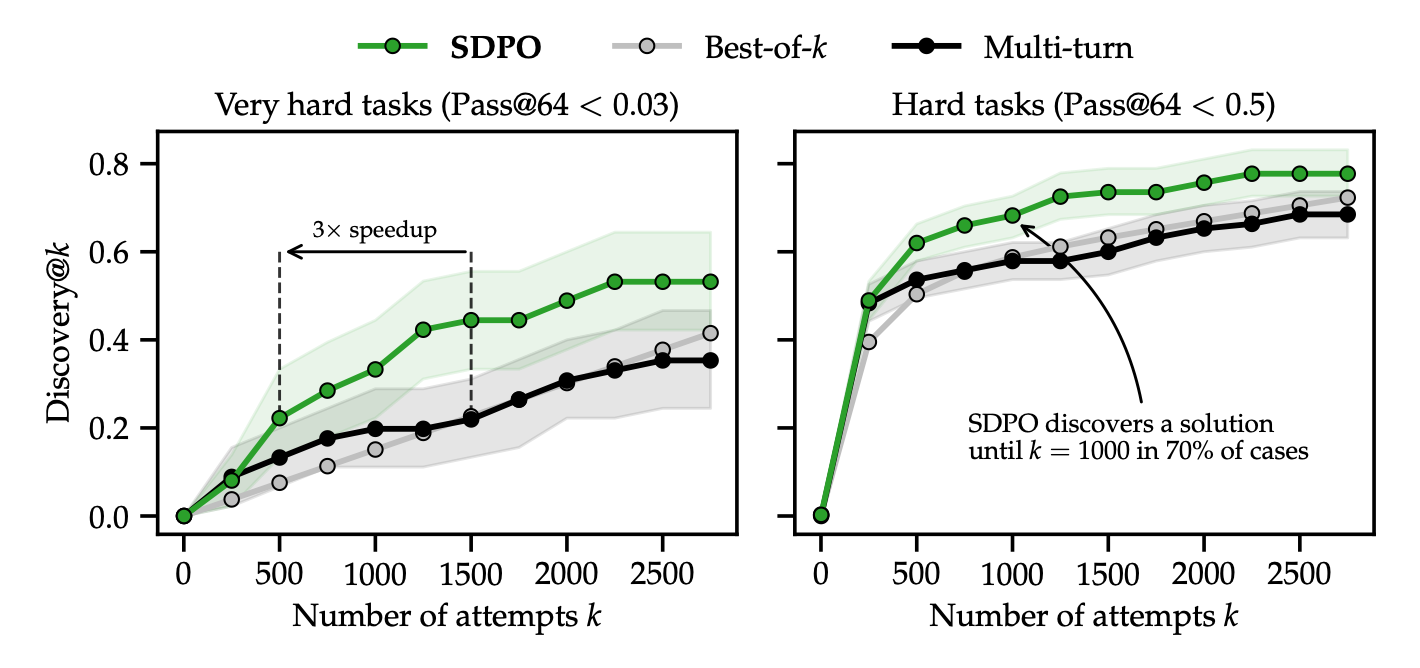
5. Accelerating Discovery at Test-Time
SDPO's dense feedback allows it to solve "Very Hard" tasks where the model's initial pass@64 is near zero.
5.1 Discovery@k vs. The Memory Bottleneck
We define discovery@k as the probability of finding a solution within k sequential attempts. Traditional RLVR fails here because it requires a success to begin learning. SDPO, conversely, learns from every failure. Crucially, SDPO addresses the Transformer Memory Bottleneck: instead of appending failed attempts to an ever-growing context window that eventually stalls, SDPO compresses interaction history into model weights. By iteratively updating parameters \theta, the model "fixes" its logic beyond the constraints of the context window.
5.2 Breakthroughs on "Very Hard" Tasks
On the LiveCodeBench v6 "Very Hard" subset, SDPO achieved a 3x speedup over best-of-k and multi-turn sampling. A landmark result was Question 3 (Q3):
- Both best-of-k and multi-turn sampling failed to find a solution after 2,750 attempts.
- SDPO discovered the solution after 321 attempts, despite the Self-Teacher's initial accuracy on the task being 0%.
--------------------------------------------------------------------------------
6. Mitigation of Catastrophic Forgetting
A major risk in RL specialization is the degradation of general capabilities. SDPO’s on-policy nature ensures that the model remains anchored to its own natural distribution.
6.1 The Performance–Forgetting Tradeoff
Evaluations on holdout tasks (IFEval, ArenaHard-v2, MMLU-Pro) confirm that SDPO maintains a superior stability profile:
- On-Policy Stability: Unlike off-policy distillation (imitation learning) which often suffers from distribution shift, SDPO preserves instruction-following performance.
- General Knowledge: SDPO showed higher retention on MMLU-Pro compared to both GRPO and SFT-on-Self-Teacher baselines.
- Instruction Following: On IFEval, SDPO outperformed GRPO, demonstrating that refining reasoning does not necessarily compromise formatting adherence.
6.2 Conclusion
SDPO serves as a high-performance, drop-in replacement for standard RLVR pipelines. By leveraging the model's own retrospection to convert environment feedback into dense self-supervision, SDPO removes the information bottleneck of scalar rewards. The result is a paradigm that is not only faster and more sample-efficient but also produces reasoning that is concise, robust, and fundamentally more accurate.

fin...