SKILLRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning

An Explainer Video:
SKILLRL: EVOLVING AGENTS VIA RECURSIVE SKILL-AUGMENTED REINFORCEMENT LEARNING
https://arxiv.org/abs/2602.08234v1
Peng Xia, UNC-Chapel Hill, pxia@cs.unc.edu
Jianwen Chen, UNC-Chapel Hill
Hanyang WangUniversity of Chicago
Jiaqi Liu, UNC-Chapel Hill
Kaide Zeng, UNC-Chapel Hill
Yu Wang, University of California San Diego
Siwei Han, UNC-Chapel Hill
Yiyang Zhou, UNC-Chapel Hill
Xujiang Zhao, NEC Labs America
Haifeng Chen, NEC Labs America
Zeyu Zheng, University of California Berkeley
Cihang Xie, University of California Santa Cruz
Huaxiu Yao, UNC-Chapel Hill, huaxiu@cs.unc.edu
A Gentle Slide Deck:
Let's Dive In...
1. The Challenge of Episodic Isolation in LLM Agents
Current Large Language Model (LLM) agents have demonstrated remarkable zero-shot capabilities in complex environments, yet they remain tethered to a significant architectural bottleneck: episodic isolation. In this paradigm, agents treat every task as a novel interaction, failing to accumulate or transfer strategic heuristics across temporal boundaries. This inability to bridge the gap between raw experience and policy improvement results in sub-optimal asymptotic performance and a failure to achieve true out-of-distribution (OOD) generalization.
Existing memory-based methods attempt to mitigate this by caching raw interaction trajectories in external vector stores. However, these approaches suffer from inherent deficiencies; raw trajectories are verbose, redundant, and laden with environmental noise. Relying on raw storage forces the agent to navigate "information bloat," where critical decision-making logic is obscured by exploratory backtracking. Effective knowledge transfer requires abstraction rather than rote memorization. Human expertise is characterized by the development of compact, reusable strategies—skills—that capture the essence of subtasks while filtering out episodic variance.
The SKILLRL framework addresses these limitations through the co-evolution of a hierarchical skill library and an agent policy. By transforming diverse environment rollouts into high-density strategic patterns, SKILLRL enables the agent to navigate sparse-reward landscapes with a learned strategic prior, ensuring that as the policy explores new state spaces, the knowledge base evolves in tandem.
2. Experience-based Skill Distillation: From Trajectories to Knowledge
The distillation phase serves as the critical interface between raw environment rollouts and actionable expertise. Its objective is to convert exploratory, high-variance trajectories into dense strategic heuristics. Utilizing a high-capability Teacher Model (M_T), specifically OpenAI o3, SKILLRL employs a Differential Processing mechanism to ensure that both successful and failed outcomes contribute to the agent’s reasoning utility.
Trajectory Type | Processing Objective | Reasoning Strategy | Key Distillation Outputs |
Successful (T^+) | Pattern Extraction | Strategic Mapping: Identifying optimal paths and critical decision points. | Distills reusable behavioral patterns and the underlying logic of correct actions (s^+ = M_T(\tau^+, d)). |
Failed (T^-) | Failure Synthesis | Counterfactual Reasoning: Analyzing what should have been done vs. what was done. | Generates concise "lessons" to prevent recurrence and identifies flawed reasoning/boundary conditions (s^- = M_T(\tau^-, d)). |
By leveraging counterfactual reasoning for failed episodes, the distillation process mitigates context noise, transforming verbose failures into high-value strategic lessons. These distilled experiences are then organized into a systematic framework for adaptive retrieval.
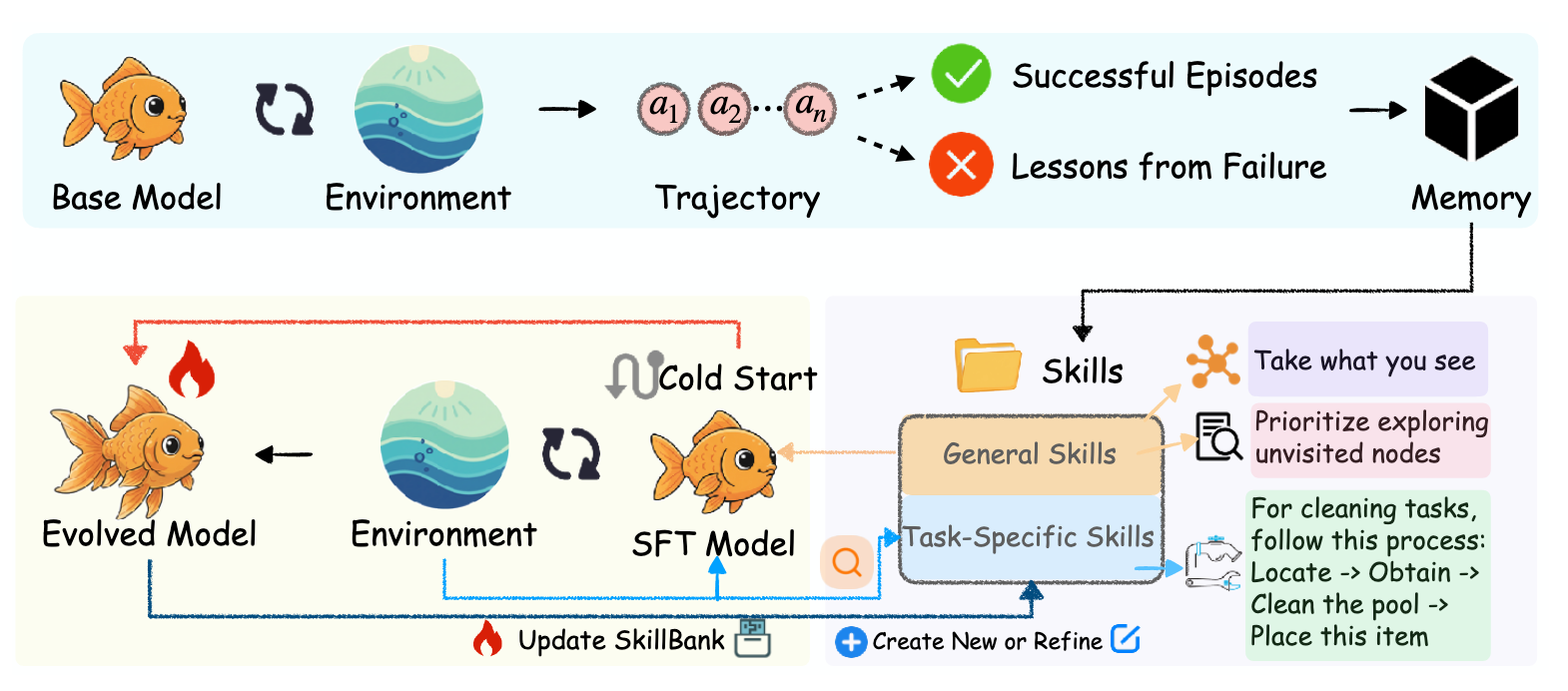
3. Hierarchical Architecture of the SKILLBANK
The SKILLBANK is a structured repository designed to separate universal principles from specialized heuristics. This hierarchical separation provides a "foundational guidance" layer that persists across tasks, supplemented by fine-grained knowledge for domain-specific challenges.
- General Skills (S_g): These capture universal strategic principles applicable across all task types, such as systematic exploration (searching surfaces exactly once), state management (verifying preconditions), and goal-tracking heuristics.
- Task-Specific Skills (S_k): These encode specialized action sequences and procedures unique to specific task categories, such as the variant-checking logic required for apparel tasks in web navigation.
To ensure efficient inference, SKILLRL utilizes an adaptive retrieval mechanism. Relevant skills are selected by calculating the semantic similarity between the task description embedding (e_d) and the skill embedding (e_s): S_{ret} = \text{Top-K}(\{s \in S_k : \text{sim}(e_d, e_s) > \delta\}, K) In experimental settings, the similarity threshold is defined as \delta = 0.4, with K=6. This ensures the agent conditions its policy only on the most relevant expertise.
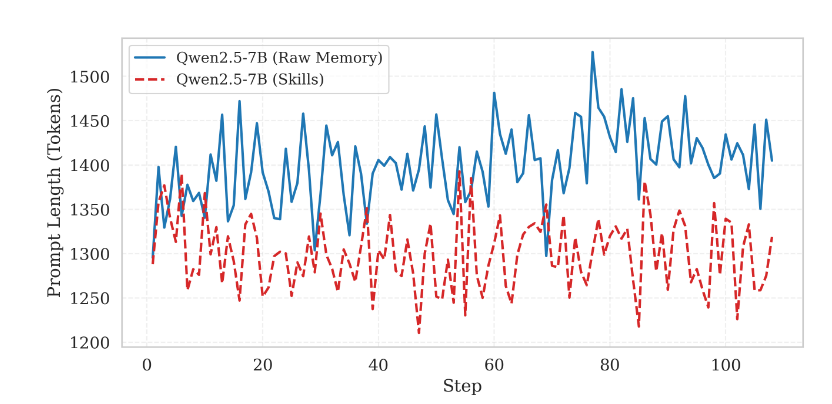
Token Footprint and Context Utility: By distilling trajectories into structured skills, the framework achieves a 10–20× compression ratio. While raw memory retrieval is characterized by high volatility (~1,450 tokens), SKILLRL maintains stability and reasoning utility within a significantly leaner context.
4. Recursive Evolution and RL-based Policy Optimization
Static skill libraries are fundamentally limited because an improving policy inevitably explores regions of the state space not covered by the initial knowledge base. SKILLRL adopts a co-evolutionary approach, refining the skill library and policy through a two-phase pipeline.
- Cold-Start Initialization: A base agent initially lacks the capability to utilize retrieved skills. To address this, SKILLRL performs Supervised Fine-Tuning (SFT) on N skill-augmented reasoning traces generated by the Teacher Model. This provides the necessary behavioral prior for skill interpretation.
- Group Relative Policy Optimization (GRPO): During the RL phase, the agent is optimized using GRPO, which eliminates the need for a separate critic model, thereby reducing memory overhead and improving gradient stability. Advantage calculation is performed using intra-group relative rewards: A_i = \frac{R_i - \text{mean}(\{R_j\}_{j=1}^G)}{\text{std}(\{R_j\}_{j=1}^G)} This allows the model to optimize against the relative performance of G sampled responses.
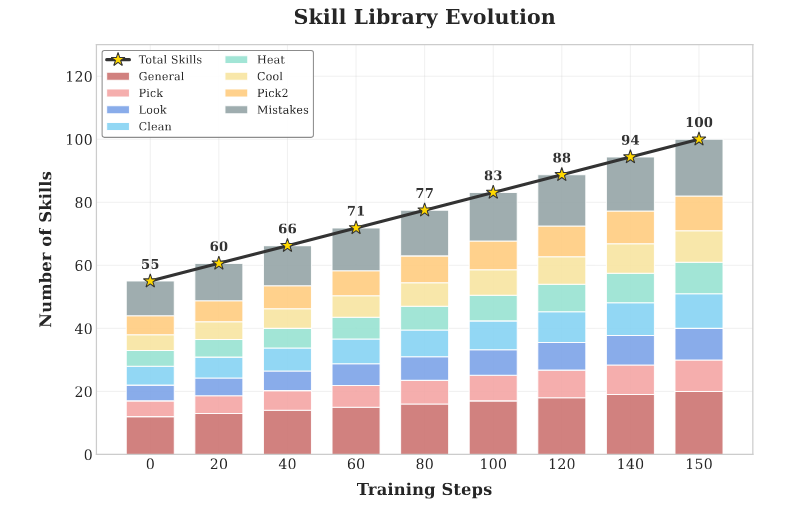
The process is governed by the Recursive Evolution Loop. After validation epochs, the system monitors success rates across task categories. If performance falls below \delta, a diversity-aware stratified sampling strategy is triggered. Failed trajectories are analyzed to identify gaps, prompting the generation of new skills or the refinement of existing ones. This recursive cycle prevents the agent from stagnating in local optima by providing a "strategic prior" that covers emergent failure modes.
5. Empirical Performance and Comparative Analysis
SKILLRL was evaluated on ALFWorld (embodied reasoning), WebShop (web navigation), and Search-augmented QA (information synthesis). The results demonstrate a state-of-the-art 15.3% average improvement over strong baselines.
Table 1: Performance Across Benchmarks | Method Category | ALFWorld (Success Rate) | WebShop (Success Rate) | Search-QA (Avg. Score) | | :--- | :---: | :---: | :---: | | GPT-4o / Gemini-2.5-Pro | 48.0% / 60.3% | 23.7% / 35.9% | - | | ReAct / Reflexion / Mem0 | 31.2% / 42.7% / 33.6% | 19.5% / 28.8% / 2.0% | - | | Vanilla GRPO | 77.6% | 66.1% | 38.5% (Search-R1) | | SKILLRL | 89.9% | 72.7% | 47.1% |
On the complex Bamboogle benchmark, SKILLRL achieved a massive 19.4% improvement over EvolveR, demonstrating the robustness of hierarchical skills in multi-step synthesis. Ablation studies (Table 3) rank the components by their impact on Success Rate:
- Skill Library (Abstraction): The most critical component; removing it leads to a 28.2% drop in performance.
- Cold-Start SFT: Essential for skill utilization (~20% drop).
- Hierarchical Structure: Universal principles provide foundational stability (~13.1% drop).
- Dynamic Evolution: Essential for pushing the performance ceiling (~5.5% drop).
6. Computational Efficiency and Context Utility
Effective context management is vital for scaling autonomous agents to long-horizon tasks. SKILLRL's distillation mechanism directly mitigates the "context-bloat" prevalent in raw-memory systems.
Technical analysis of Context Efficiency reveals:
- Raw Memory Retrieval: Averages ~1,450 tokens with high fluctuation.
- SKILLRL: Averages <1,300 tokens, a 10.3% reduction in overhead with significantly higher reasoning density.
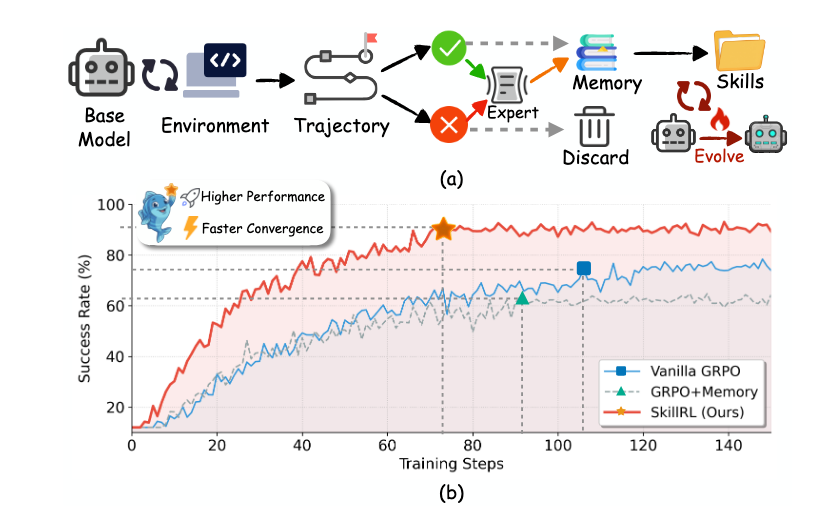
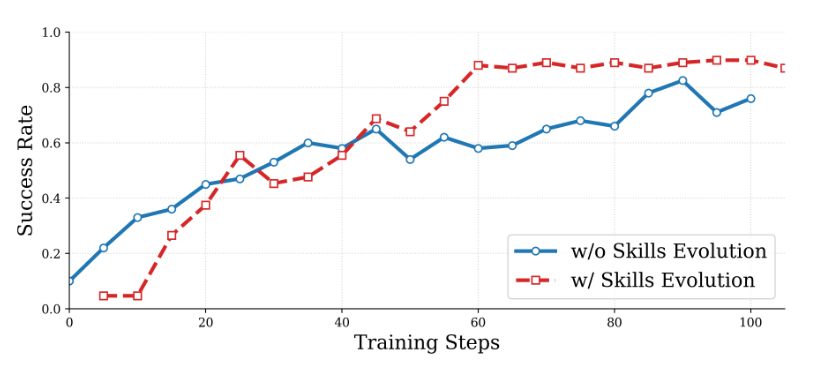
Evolutionary dynamics (Figure 5) indicate that recursive skill evolution not only accelerates convergence—reaching an 80% success rate within 60 steps compared to 90 steps for baselines—but also achieves a higher asymptotic ceiling (~0.90 vs. ~0.80). By providing a strategic prior in sparse-reward environments, SKILLRL prevents wasted exploratory cycles. The shift from "storing logs" to "evolving expertise" represents the most viable path forward for sample-efficient AI agentic systems.

fin...