STEM: Scaling Transformers with Embedding Modules
In this post, we explore the innovative approach of "STEM: Scaling Transformers with Embedding Modules." This amazing research from Carnegie Mellon University and Meta AI presents a solution to the inefficiencies of traditional Transformer architectures. Learn how STEM leverages embedding modules to enhance model performance while minimizing computational costs.
We'll delve into the architecture changes that make STEM a game-changer, including its ability to stabilize training and improve accuracy per FLOP. By the end of this post, you'll understand the intricacies of this new paradigm and its potential impact on the field of AI.
📌 What You'll Learn:
• 🧠 How STEM replaces expensive matrix multiplications with efficient lookup mechanisms
• 📉 The reasons behind the instability of Mixture of Experts (MoE) and how STEM mitigates them
• 📊 The significance of training return on investment (ROI) in model performance
• 🔍 Insights into interpretability and knowledge editing in embedding layers
• ⚖️ The advantages of long-context scaling for better retrieval and efficiency
An Explainer Video:
STEM: Scaling Transformer With Embedding Modules
https://arxiv.org/pdf/2601.10639
Ranajoy Sadhukhan, Carnegie Mellon University
Sheng Cao, Carnegie Mellon University
Harry Dong, Carnegie Mellon University
Changsheng Zhao, Carnegie Mellon University
Attiano Purpura-Pontoniere, Meta AI
Yuandong Tian, Meta AI
Zechun Liu, Meta AI
Beidi Chen, Meta AI
A Gentle Slide Deck:
Let's Dive In...
1.0 Introduction: Addressing the Scaling Dilemma in Large Language Models
The advancement of Large Language Models (LLMs) is fundamentally tied to the principles of parameter-scaling laws, which suggest that greater model capacity leads to enhanced capabilities. However, the pursuit of this scale introduces significant practical hurdles in training stability, computational cost, and model interpretability. Fine-grained sparse architectures, particularly Mixture-of-Experts (MoE) models, have emerged as a primary strategy to increase parameter counts without a proportional rise in per-token compute. While promising, this approach introduces a distinct set of optimization and system-level challenges that can impede progress.
The core difficulties associated with fine-grained sparsity in MoE models can be deconstructed into several key areas:
- Training Instability: The dynamic, non-uniform routing of tokens to experts often results in a significant portion of "micro-experts" being under-trained. This imbalance can lead to an unstable training process, characterized by "bumpy jumps" and sudden loss spikes that disrupt convergence.
- Load Balancing Complexity: To mitigate non-uniform routing, MoE models rely on auxiliary load-balancing objectives. However, these secondary loss functions can interfere with the primary training objective if not meticulously tuned, creating a delicate and often complex optimization problem.
- Communication Overhead: As the number of experts increases to achieve finer granularity, the required inter-device communication becomes fragmented. This results in a higher volume of smaller all-to-all messages, which degrades bandwidth utilization and amplifies communication latency, creating a significant system bottleneck.
- Lack of Interpretability: The functional roles of individual micro-experts within a large MoE model are notoriously opaque. This lack of transparency makes it difficult to understand, debug, or control the model's internal knowledge representations and decision-making processes.
To overcome these specific challenges, we introduce STEM (Scaling Transformers with Embedding Modules), a novel architecture designed for stable, efficient, and interpretable scaling. STEM’s core mechanism is a static, token-indexed approach that replaces a key component of the Transformer's Feed-Forward Network (FFN) with a direct, layer-local embedding lookup. This design eliminates the dynamic runtime routing responsible for the instability and load-balancing complexities inherent in MoE, paving the way for superior training stability, enhanced computational efficiency, strong downstream performance, and an unprecedented degree of granular controllability. Crucially, STEM's architectural principles are not merely an alternative to MoE but are orthogonal to them, suggesting a future where its benefits could be compounded within hybrid "Mixture of STEM expert" designs.
This whitepaper will now delve into the specific architectural modifications that define STEM, exploring its theoretical foundations before presenting the empirical evidence of its success.
2.0 The STEM Architecture: A Paradigm Shift in FFN Design
The Feed-Forward Network (FFN) block is a critical component of the Transformer architecture, responsible for a significant portion of the model's parametric memory and computational workload. It is within this block that STEM introduces its primary architectural innovation, shifting from a dense, dynamic computation to a static, token-indexed sparse structure.
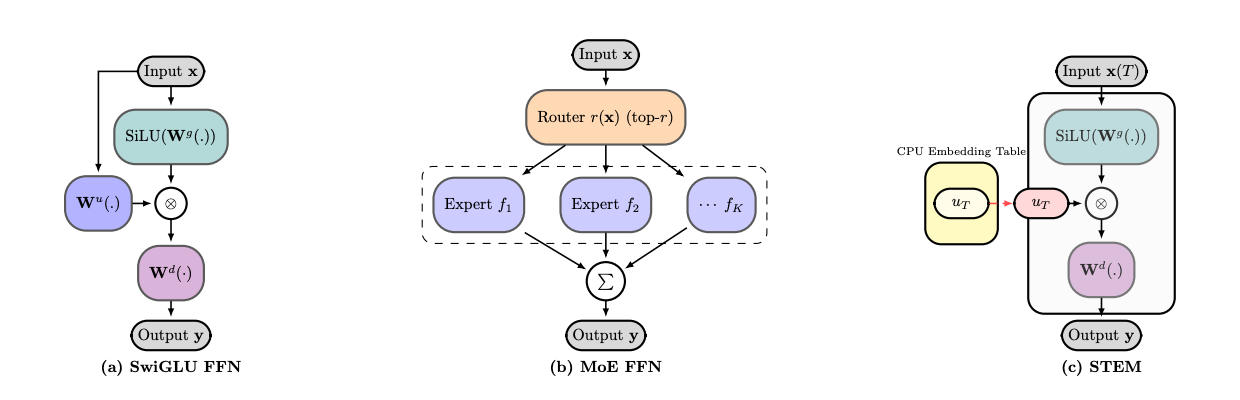
To understand STEM's design, we first consider the standard SwiGLU FFN formulation. For a given input hidden state x_\ell, the FFN layer computes its output y_\ell as follows:
y_\ell = W_d^\ell ( \text{SiLU} ( W_g^\ell x_\ell ) \odot ( W_u^\ell x_\ell ) )
Here, W_u^\ell is the up-projection matrix, W_g^\ell is the gate projection matrix, and W_d^\ell is the down-projection matrix. These three matrices traditionally constitute the dense, learned parameters of the FFN layer.
STEM fundamentally modifies this structure by replacing the dense up-projection matrix (W_u^\ell) with a direct, token-indexed lookup from a layer-local embedding table (U_\ell). The gate and down-projection matrices remain dense and are shared across all tokens, preserving context-aware modulation. The STEM FFN computation is therefore:
y_\ell = W_d^\ell ( \text{SiLU} ( W_g^\ell x_\ell ) \odot U_\ell[t] )
In this formulation, U_\ell[t] is the specific row from the embedding table U_\ell that corresponds to the input token ID t. This change is subtle yet profound, as it replaces a costly matrix-vector multiplication with a simple, efficient table lookup. This design philosophy contrasts sharply with related approaches like Per Layer Embeddings (PLE), as detailed below.
STEM | Per Layer Embeddings (PLE) |
Role of Up-Projection | Completely replaces the standard up-projection matrix. |
Embedding Dimensionality | The embedding dimension matches the FFN's intermediate dimension ( |
The architectural elegance of STEM lies in its ability to achieve extreme, fine-grained sparsity without the need for runtime routing logic, auxiliary losses, or expensive inter-node communication. This static design is not only efficient but also grounded in a strong theoretical motivation, which we explore in the next section.
3.0 Theoretical Foundations and System-Level Optimizations
A robust architectural design must be grounded in strong theoretical principles. STEM's design is not an arbitrary choice but is motivated by the key-value memory perspective of FFNs, which provides a clear rationale for targeting the up-projection matrix for sparsification. This theoretical foundation is complemented by a suite of system-level optimizations that make STEM a practical and scalable solution.
The "key-value memory view" posits that a standard FFN functions as a content-addressable memory. In a SwiGLU FFN, the up-projection (W_u) and gate projection (W_g) matrices can be seen as forming two sets of "keys." The input x is compared against these keys to generate addressing weights. The down-projection matrix (W_d) acts as the "values," which are retrieved and combined based on these weights. Within this framework, the up-projection generates the primary address for feature lookup, while the gate projection provides crucial context-dependent modulation, effectively sharpening the memory retrieval.
STEM's design is optimized for this model. By replacing the up-projection with a context-agnostic, token-indexed embedding, STEM provides a direct, token-specific address vector. The dense gate projection is preserved, ensuring that this address is still modulated by the input context, allowing for sharp, context-adaptive retrieval. Ablation studies confirm this design choice: replacing the gate projection with an embedding hurts performance, as it removes the model's ability to apply context-aware gating.
To make this architecture practical at scale, STEM incorporates several critical system-level optimizations:
- CPU Offloading and VRAM Savings The large, layer-local embedding tables are offloaded to CPU memory. This strategy frees up significant GPU VRAM—roughly one-third of the FFN parameter memory—allowing for larger batch sizes or models. Since the tables can be replicated on each node, this also eliminates the need for cross-node communication for expert parallelism.
- Asynchronous Prefetching Because the required embeddings are determined statically by the input token IDs, they can be prefetched from CPU to GPU asynchronously. This allows the data transfer to be overlapped with the GPU's ongoing computations, effectively hiding the communication latency.
- Token Deduplication and LFU Caching for Communication Reduction In any given batch of sequences, many tokens are repeated. By identifying the set of unique tokens, the system can significantly reduce the amount of data that needs to be prefetched. This is further optimized with a memory-efficient Least Frequently Used (LFU) cache on the GPU, which exploits the Zipfian distribution of token frequencies to keep the most common embeddings readily available, achieving hit rates of over 80%.
- Decoupled Parallelism Strategies The STEM embedding tables can be sharded across available devices using a parallelism strategy that is independent of the one used for the main model backbone (e.g., DDP, FSDP). This flexibility allows for fine-tuning the trade-off between communication overhead and memory requirements.
Together, these optimizations form a cohesive system that makes the theoretically large memory footprint of STEM practical, by intelligently managing the CPU-GPU data transfer bottleneck to hide latency and minimize communication volume. These theoretical and system-level designs are validated by extensive empirical results, demonstrating STEM's superior performance, stability, and efficiency in practice.
4.0 Empirical Validation: Performance, Stability, and Efficiency
The primary goal of our empirical evaluation was to rigorously benchmark STEM against both standard dense and fine-grained MoE baselines. The experiments were conducted across 350M and 1B model scales, with careful controls for training compute (activated FLOPs) and the total number of training tokens to ensure a fair comparison.
Training Stability and Convergence
A standout characteristic of STEM is its exceptional training stability. Unlike fine-grained MoE models that often exhibit volatile training dynamics, STEM converges smoothly and reliably.
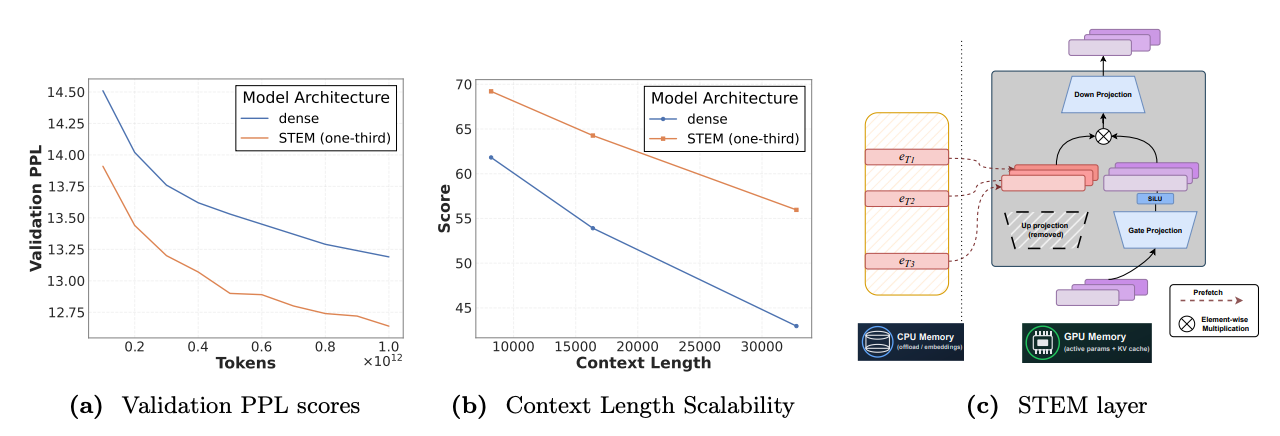
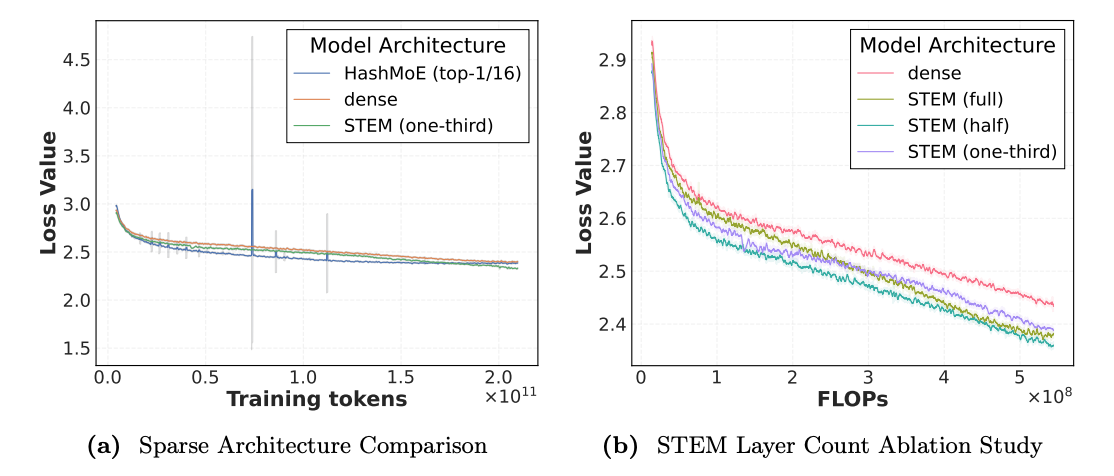
As shown in Figure 5a, the HashMoE baseline experiences "bumpy jumps" and significant loss spikes during training. In stark contrast, the STEM model's training loss curve is stable and monotonic. Furthermore, STEM demonstrates superior convergence efficiency. Figures 1a and 5b show that STEM achieves a lower training and validation loss while consuming fewer training FLOPs than the dense baseline, indicating a more efficient learning process.
Downstream Task Performance
Across a suite of standard downstream benchmarks, STEM consistently outperforms its dense and MoE counterparts, with particularly strong results on tasks that require deep knowledge and reasoning.
Key performance findings from evaluations at the 350M and 1B scales include:
- Substantial accuracy improvements of 9–10% were observed on knowledge-intensive benchmarks, including ARC-Challenge and OpenBookQA. This suggests that STEM's architecture enhances the model's capacity for storing and retrieving factual information.
- In evaluations of the mid-trained checkpoints (Table 4), the 1B STEM model demonstrated consistent outperformance over the dense baseline in reasoning and knowledge retrieval, evidenced by higher scores on GSM8K (mathematical reasoning) and MMLU (multitask understanding).
Efficiency Gains and Return on Investment (ROI)
STEM's architectural design translates directly into tangible efficiency gains. By replacing the up-projection matrix, STEM eliminates roughly one-third of the parameters in each modified FFN layer. To quantify the overall benefit, we use a "Training ROI" metric, defined as the ratio of model accuracy (Avg) to total training FLOPs.
The ablation study results are clear: the STEM-full model, where all possible FFN layers are replaced, achieves a 1.33x training ROI compared to the dense baseline. This demonstrates that STEM not only produces more accurate models but does so with significantly greater computational efficiency.
Beyond these quantitative metrics, STEM's unique architecture unlocks novel qualitative capabilities in interpretability and knowledge editing, further distinguishing it from existing models.
5.0 Unlocking Novel Capabilities: Interpretability and Knowledge Editing
Interpretability has long been a formidable challenge in machine learning, creating a trade-off between model performance and our ability to understand a model's inner workings. STEM's architecture offers an inherent solution, bridging this gap by design and enabling a remarkable level of granular controllability.
Geometric Properties of STEM Embeddings
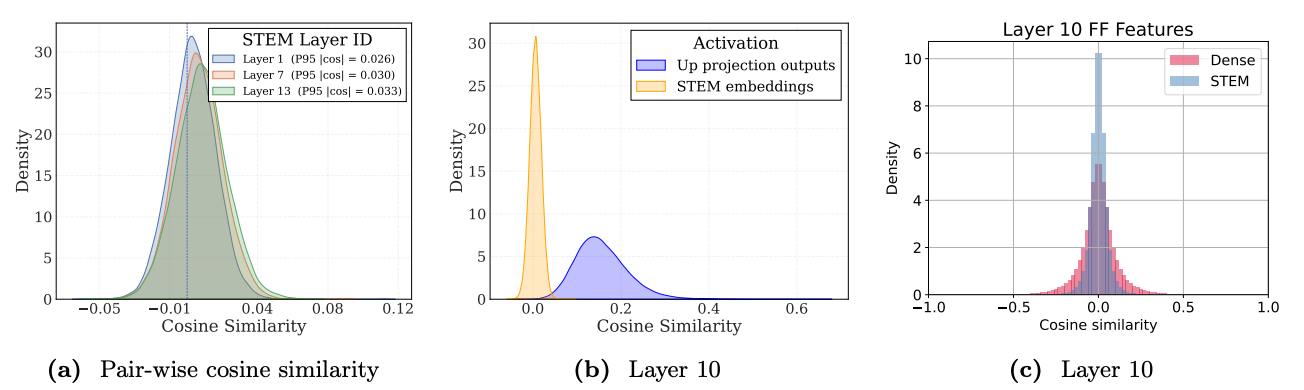
Analysis of the learned STEM embeddings reveals a key geometric property: they exhibit a large angular spread, meaning they have very low pairwise cosine similarity. The distribution plots in Figure 6 show that most embedding vectors are nearly orthogonal to one another.
From the key-value memory perspective, these embeddings act as token-specific "address vectors." Their near-orthogonality minimizes representational interference, allowing each token to map to a more distinct and disentangled location in the model's conceptual space. This reduced redundancy in the address space enables more precise and disentangled knowledge attribution, thereby improving the model’s effective information storage capacity.
Causal Knowledge Editing
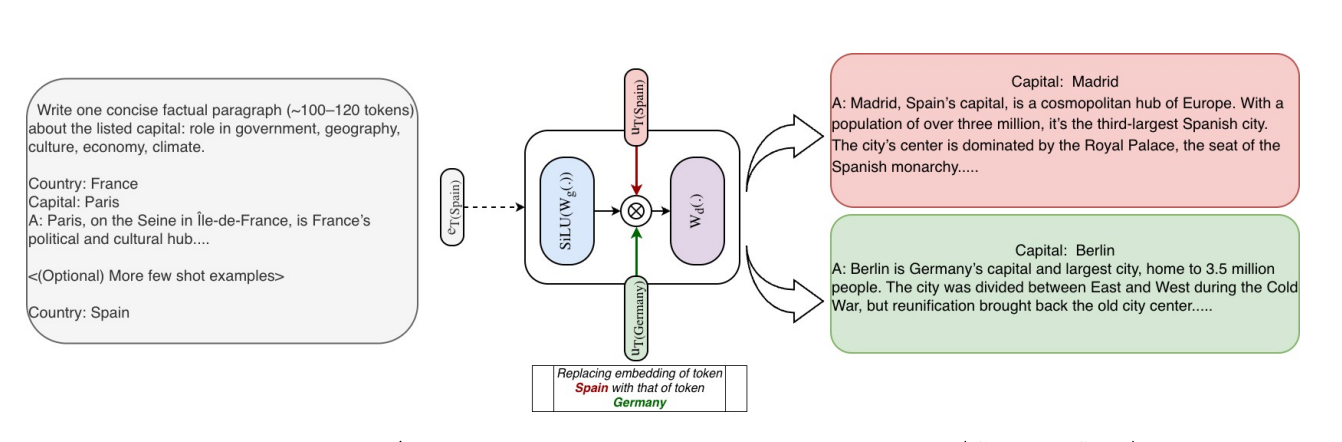
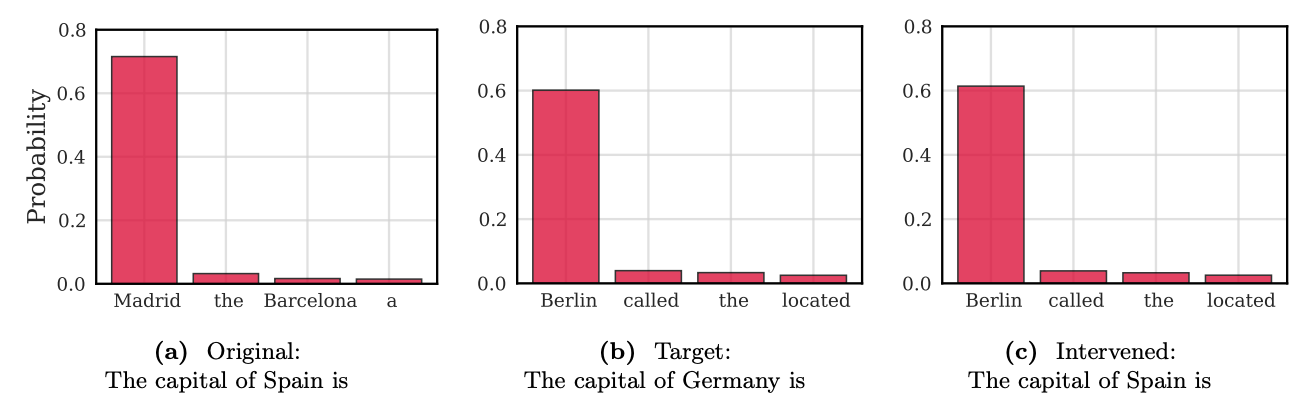
The direct, token-indexed nature of STEM embeddings allows for causal knowledge editing with surgical precision. Because each embedding is tied to a specific token ID, we can directly manipulate the model's factual knowledge by simply swapping embeddings, without altering the input text.
This capability is powerfully illustrated with an example: when prompted with "The capital of Spain is," the model correctly generates "Madrid." However, by internally swapping the embedding for the token Spain with the embedding for Germany at each STEM layer (e_{\text{Spain},\ell} \leftarrow e_{\text{Germany},\ell}), the model's output distribution causally shifts. With the exact same input prompt, the intervened model now generates "Berlin" (Figure 7). This demonstrates that factual knowledge is highly localized within these embeddings and can be edited in a modular and attributable manner.
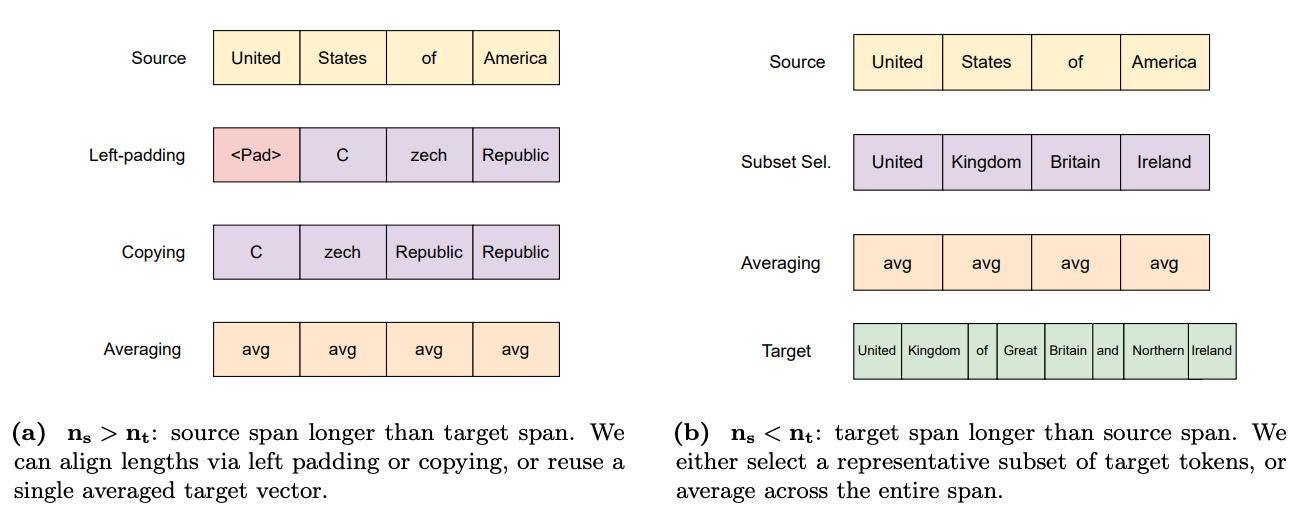
When the source and target entities for an edit have different tokenization lengths (denoted n_s and n_t), several strategies can be employed to align them:
- Padding: Used when the source entity has more tokens than the target (n_s > n_t); the shorter target sequence is padded to match the source length.
- Copying: An alternative for n_s > n_t; tokens from the shorter target sequence are repeated to fill the longer source span.
- Subset Selection: Used when the target entity has more tokens than the source (n_s < n_t); a representative subset of target embeddings is chosen to map onto the shorter source span.
- Averaging: A robust, length-agnostic strategy; a single averaged embedding is computed from all target tokens and used to replace all source token embeddings.
These interpretability and editing features represent a significant step toward building more controllable, reliable, and attributable AI systems, paving the way for advanced capabilities like long-context reasoning.
6.0 Advanced Capabilities: Long-Context Reasoning and Test-Time Scaling
The ability to process and reason over long sequences of information is increasingly critical for modern AI applications, from multi-document analysis to complex instruction following. STEM's unique architecture provides a powerful and efficient mechanism for excelling in this domain.
Test-Time Capacity Scaling
STEM's performance in long-context scenarios is driven by a phenomenon we call "test-time capacity scaling." Because STEM uses a unique embedding vector for each distinct token ID in a sequence, the number of activated parameters grows as the context length and number of unique tokens increase. This relationship can be expressed as \text{Params}_{\text{STEM act}}(L) = |S| \cdot d_{ff} \cdot L_{\text{uniq}}, where L_{\text{uniq}} is the count of unique tokens in a sequence of length L.
This means that as the model processes longer and more complex inputs, it automatically engages a larger portion of its parametric memory. Crucially, this capacity scaling occurs without any increase in the per-token computational cost (FLOPs), providing a highly efficient way to bring more knowledge to bear on long-context tasks.
Empirical Evidence of Long-Context Superiority
Empirical results strongly validate STEM's advantage in long-context settings.
- On the synthetic Needle-in-a-Haystack (NIAH) benchmark, which tests information retrieval over long documents, STEM's performance advantage over the dense baseline grows with the context length. As shown in Figure 1b, the accuracy gap widens from 8.4% to 13% as the context expands.
- This benefit extends beyond synthetic tasks to complex reasoning benchmarks. As detailed in Tables 5 and 6, the STEM model consistently outperforms the dense baseline on LongBench, BIG-Bench Hard (BBH), and MuSR (multistep soft reasoning). This demonstrates that STEM's long-context capabilities translate into improved performance on tasks requiring multi-hop reasoning and comprehension of complex code.
By adaptively scaling its active parameters with context length, STEM provides a robust, efficient, and scalable solution to the growing challenge of long-context reasoning.
7.0 Conclusion and Future Directions
This work introduced STEM, a novel Transformer architecture that provides a stable, efficient, and interpretable path to scaling parametric memory. By replacing the FFN up-projection with a static, token-indexed, layer-local embedding lookup, STEM effectively decouples parametric capacity from per-token compute and cross-device communication. This design yields a cascade of benefits, including superior training stability compared to fine-grained MoE models, improved downstream accuracy on knowledge-heavy and reasoning tasks, greater computational efficiency with a 1.33x training ROI, enhanced long-context performance through test-time capacity scaling, and unprecedented model interpretability via direct, causal knowledge editing.
The key takeaway is that STEM presents an effective and practical method for scaling Transformers that directly addresses many of the fundamental limitations of traditional dynamic sparse models. It achieves the goals of fine-grained sparsity—higher parameter counts at constant per-token FLOPs—without the associated costs of training instability, complex load-balancing, and high communication overhead.
Looking ahead, the principles underpinning STEM open up promising new research avenues. The architecture's orthogonality to existing paradigms suggests the potential for developing a hybrid "Mixture of STEM experts," where each expert within an MoE framework is itself a STEM-based FFN. This could combine the benefits of both architectures, further pushing the boundaries of scalable, efficient, and controllable artificial intelligence.
fin...