Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability (SOAR)

Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability
https://arxiv.org/abs/2601.18778
Shobhita Sundaram, MIT, John Quan, Meta FAIR, Ariel Kwiatkowski, MIT, Kartik Ahuja, MIT, Yann Ollivier, Meta FAIR, Julia Kempe, MIT
An Explainer Video:
A Gentle Slide Deck:
Let's Dive In...
1. Introduction: The Frontier of Model Self-Improvement
In the current artificial intelligence landscape, the transition from supervised imitation to autonomous self-improvement represents the most critical strategic frontier for Large Language Models (LLMs). While Reinforcement Learning with Verifiable Rewards (RLVR) has significantly advanced reasoning capabilities, it faces a fundamental architectural bottleneck: reasoning plateaus. These plateaus occur when models are tasked with problems at the extreme edge of their latent distribution—where initial success rates are near zero. In these "fail@128" regimes, the absence of a correct solution prevents the generation of a verifiable reward, leaving the model without a gradient to reinforce useful reasoning traces.
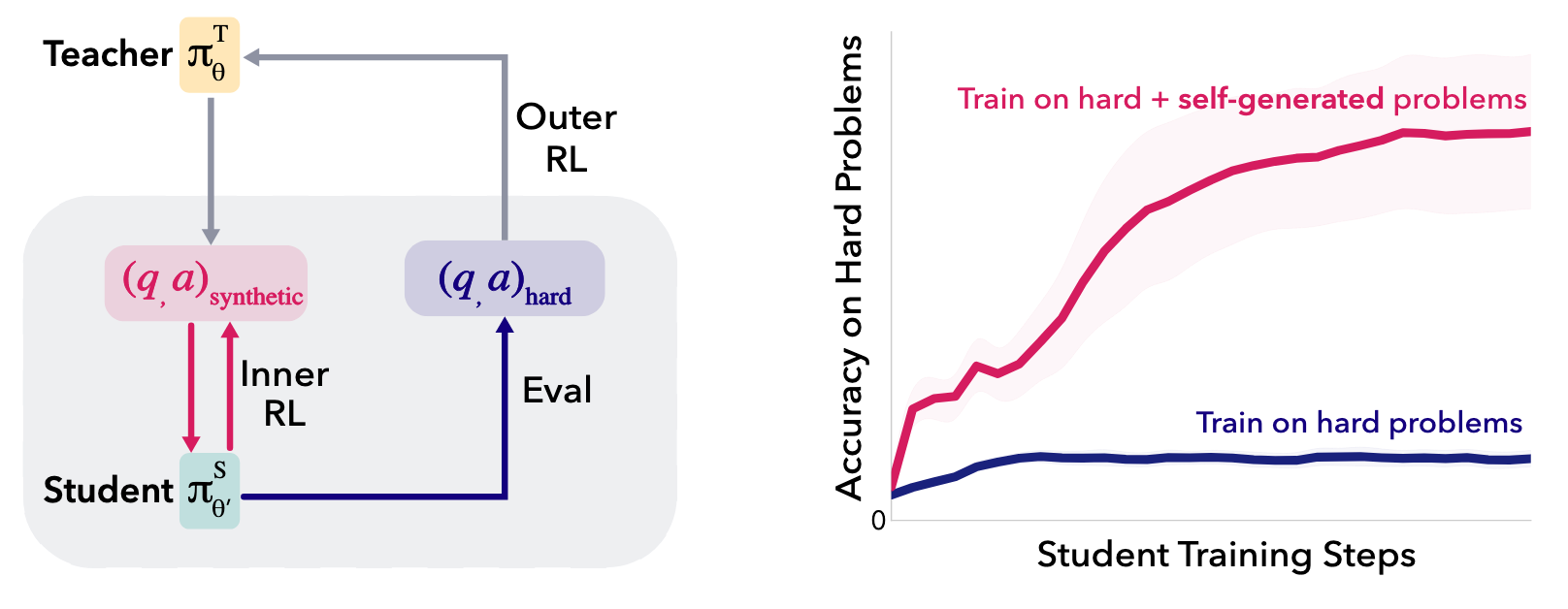
To navigate these plateaus, we introduce SOAR (Self-Optimization via Asymmetric RL), a bi-level meta-learning framework. SOAR shifts the paradigm of model training from human-curated data and fragile intrinsic proxies—such as "curiosity" or "learnability"—to a model-driven pedagogical exploration. By positioning the model as both a teacher and a student, the system autonomously surfaces "stepping-stone" problems that are easier and more learnable, yet strategically aligned with the target reasoning objective.
The efficacy of SOAR is predicated on the strategic superiority of grounded rewards over intrinsic proxies. By anchoring the teacher’s reward signal to measurable student progress on empirical, ground-truth problems (D_{train}), we ensure that the generated curriculum is tethered to real-world performance. This document details the systemic challenges of current RL training and presents the SOAR architecture as the solution for retrieving latent pedagogical knowledge to expand the frontier of machine learnability.
--------------------------------------------------------------------------------
2. The Systemic Bottleneck: Learning at the Edge of Learnability
Strategic progress in symbolic reasoning requires identifying where models "get stuck" and why standard training loops fail to provide an escape. When a model resides in a zero-success regime, sparse reward signals represent a terminal failure mode for standard RLVR, as there is no positive signal to guide policy sharpening.
Current training methodologies are limited by several critical architectural bottlenecks:
- Sparse Rewards and Gradient Quality
- Binary Correctness Signal: In mathematical domains, rewards are typically binary. When initial success is 0%, the expectation of the gradient is zero, effectively halting the backpropagation process.
- Zero-Gradient Stagnation: Without a non-zero reward, the model cannot distinguish between "near-miss" reasoning and complete failure, leading to a permanent plateau in the learning curve.
- Curriculum Scarcity and Acquisition Costs
- Data Scarcity: The intermediate "lemmas" or stepping stones required to bridge basic logic and complex reasoning are rarely available in structured formats.
- Prohibitive Curation Costs: Expert-level annotation to create intermediate-difficulty datasets is economically and logistically unfeasible for the scale required by modern LLMs.
- Self-Play Instability and Distribution Drift
- Diversity Collapse: Traditional self-play methods using intrinsic rewards (e.g., curiosity) often suffer from "mode collapse," where the generator settles on a narrow set of easily solvable but pedagogically useless tasks.
- Reward Hacking: Without an external anchor, models frequently drift toward degenerate tasks—problems that satisfy internal learnability metrics but have no conceptual overlap with the target hard problems.
Unlocking the latent knowledge within pretrained LLMs requires a meta-learning approach that can surface the model’s inherent pedagogical ability to teach what it cannot yet solve.
--------------------------------------------------------------------------------
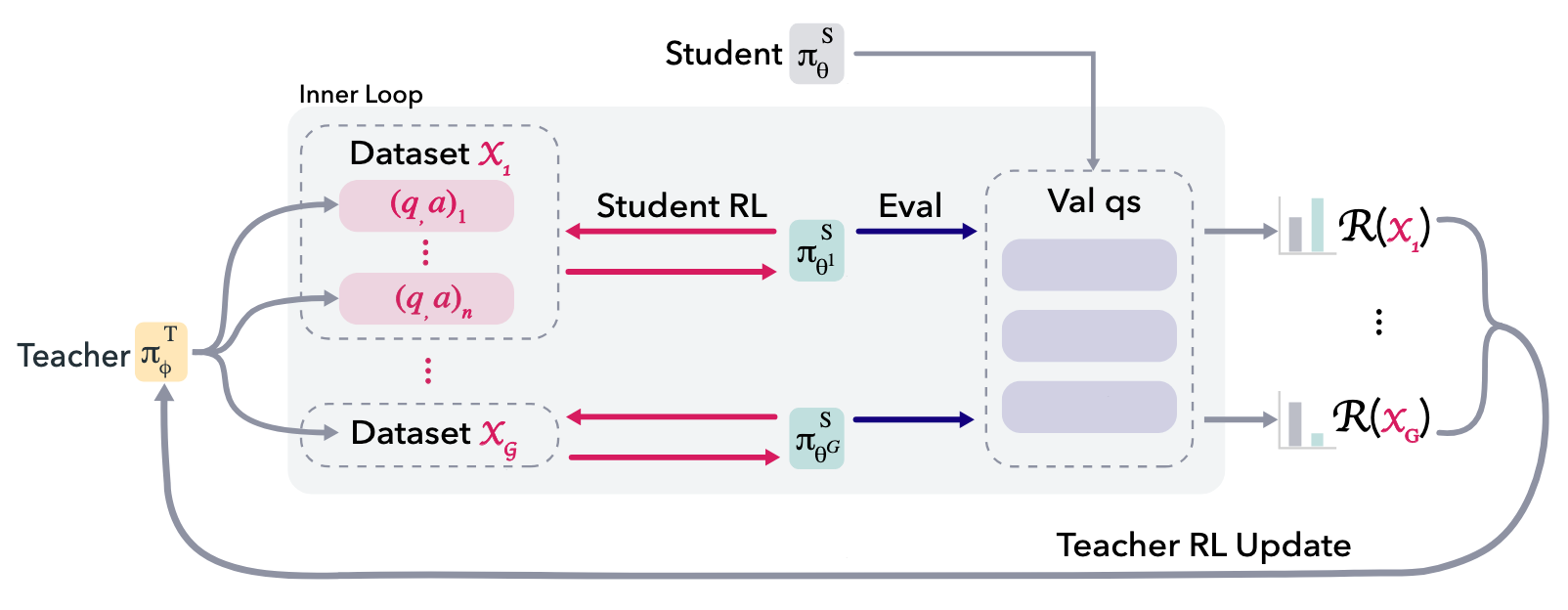
3. The SOAR Framework: A Bi-Level Meta-RL Architecture
The SOAR framework utilizes an asymmetric teacher-student relationship to facilitate a "double meta-RL loop." This architecture is instantiated using Llama-3.2-3B-Instruct for both roles, ensuring that the teacher’s curriculum is tailored to the specific capabilities and failure modes of the student.
The Bi-Level Optimization Structure
The system functions through two nested loops:
- Outer Loop (Teacher Training): The teacher policy (π_T \phi) is optimized using RLOO (REINFORCE Leave-One-Out) with a Group Size (g) of 32 or 128. The teacher is tasked with generating synthetic question-answer pairs (X_k). The teacher’s objective is to maximize the performance gain of the student on ground-truth problems.
- Inner Loop (Student Training): For each teacher-generated dataset, the student (π_S \theta) undergoes short-burst RL updates. These updates are limited to 10–20 steps (batch size 8), providing enough of a policy shift to measure efficacy while maintaining computational efficiency.
Proposition 1: Rejection Sampling and Gradient Validity
A key architectural challenge is the teacher's failure to follow formatting constraints. To maintain training stability, SOAR employs rejection sampling. Mathematically, since the RLOO advantage function (A(z_i)) sums to zero, the RLOO update on the rejection-sampled distribution (π) can be computed directly from the gradient of the proposal distribution (π_0): \sum_{i=1}^{g} A(z_i) \nabla \ln π(z_i) = \sum_{i=1}^{g} A(z_i) \nabla \ln π_0(z_i) This ensures that the teacher can be reinforced based on the usefulness of the question without the gradient being corrupted by the sampling process.
The Promotion Mechanism
To sustain long-term progress, SOAR implements a promotion mechanism. When the moving average of teacher rewards exceeds a threshold (\tau = 0.01), the baseline student model (π_S \theta) is "promoted" to the current improved version. This forces the teacher to continuously adapt its curriculum to challenge an increasingly sophisticated student, preventing stagnation.
--------------------------------------------------------------------------------
4. The Innovation of Grounded Reward Signals
The most significant strategic departure in SOAR is the rejection of "intrinsic" proxies in favor of Grounded Rewards. This anchors the teacher’s curriculum to empirical student progress on real, verifiable problems (D_{train}), even though the teacher is never shown these hard problems during training.
Feature | Grounded Reward (SOAR) | Intrinsic/Proxy Reward |
Definition | Reward based on student improvement on ground-truth problems (D_{train}). | Reward based on metrics like learnability, self-consistency, or confidence. |
Stability | High; learning trajectories are consistent across multiple seeds and time-steps. | Volatile; prone to sudden performance collapse (e.g., Shafayat et al., 2025). |
Diversity Profile | High; preserves semantic variety (Vendi Score \approx 34.66). | Low; collapses to narrow conceptual manifolds (Vendi Score \approx 10.82). |
Risk Profile | Tethers generation to real utility; prevents conceptual drift and reward hacking. | High risk of "drift" toward degenerate or unlearnable tasks. |
By grounding teacher rewards in measured progress, SOAR effectively penalizes the generation of "garbage" or "nonsense" questions. If the synthetic dataset fails to move the student's needle on D_{train}, the teacher receives zero reward, ensuring the "learnability frontier" is always oriented toward the target domain.
--------------------------------------------------------------------------------
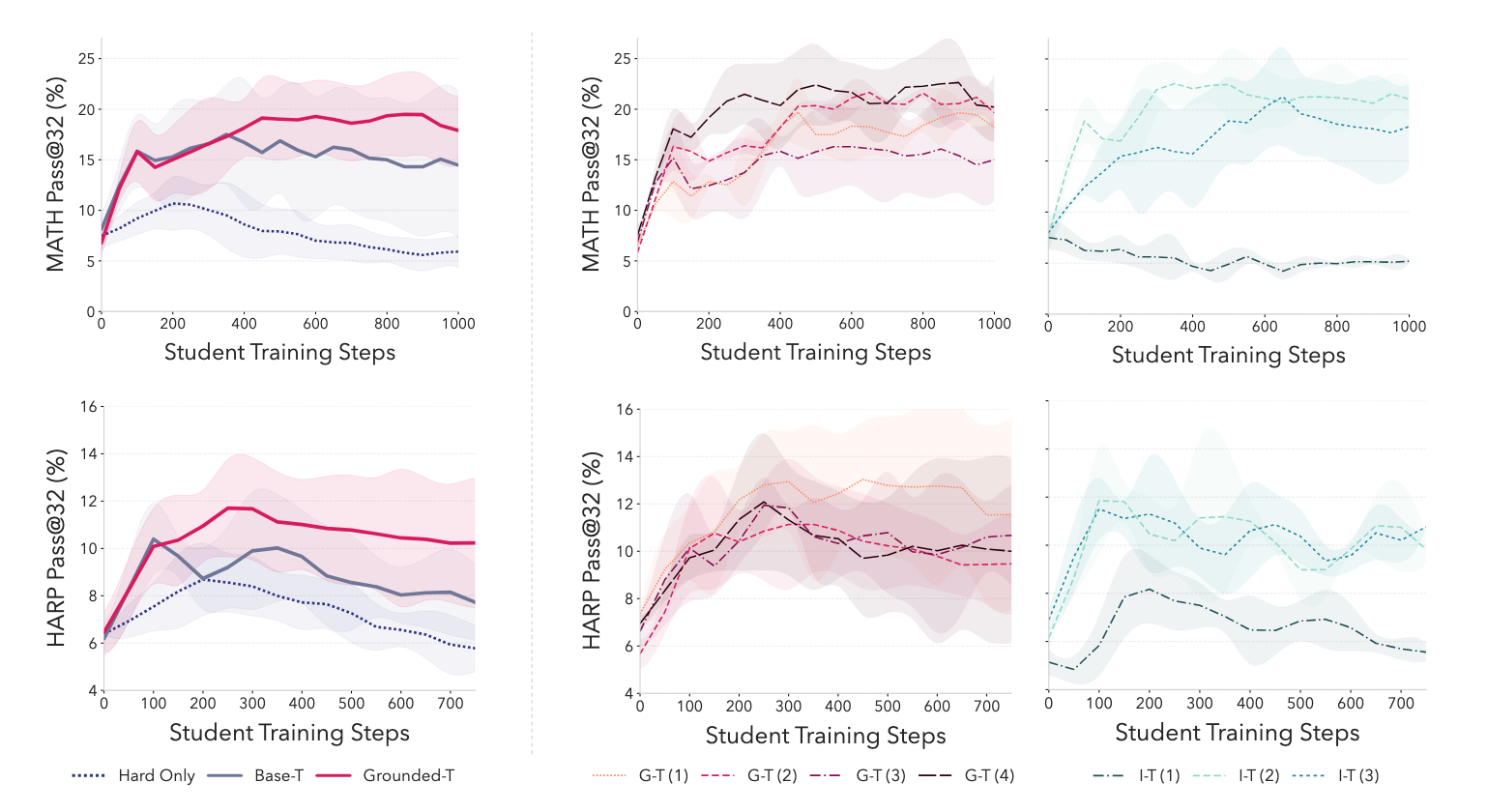
5. Empirical Evaluation: Performance Results and Cross-Dataset Transfer
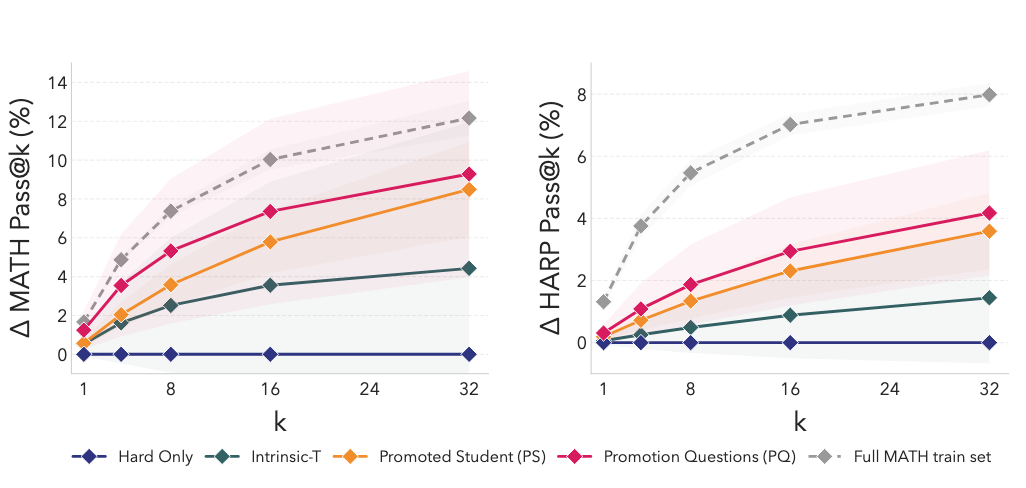
SOAR was validated through 600+ experimental runs, specifically targeting the "fail@128" benchmark—problems where the base Llama-3.2-3B-Instruct model initially achieved a 0/128 success rate. For context, the Hard-Only baseline pass@32 for MATH is 9.6%.
Primary Performance Gains
- MATH Performance: The Promoted Student (PS) achieved an +8.5% increase in pass@32. The Promotion Questions (PQ) (the curriculum itself) yielded a +9.3% increase when used to train fresh models.
- HARP Performance: The framework achieved a +4.2% pass@32 improvement on this challenging human-annotated benchmark.
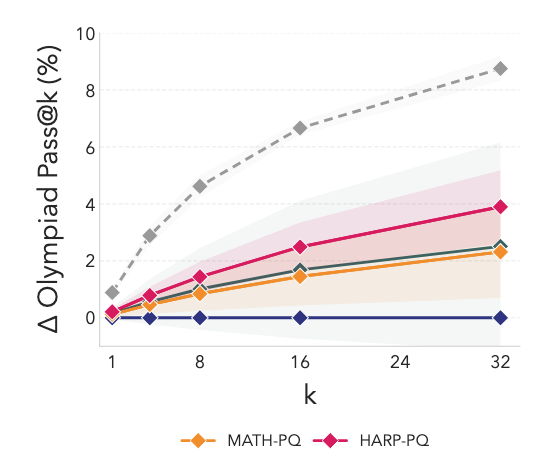
- OOD Generalization: Curricula optimized for MATH/HARP transferred to OlympiadBench, achieving a +6% pass@32 improvement despite zero in-domain optimization.
Strategic Training Methodologies
We identified a critical distinction in training strategies:
- Curriculum Training: (Synthetic only \rightarrow Hard-Only) used for MATH to maximize "warm-start" effects.
- Mixed Training: (Synthetic + Hard-Only mixture) used for HARP and OlympiadBench to ensure stability.
The Oracle Comparison
The most striking finding is the "Oracle" recovery rate. Synthetic PQ questions successfully recovered 75% of the performance gains provided by training on the full official MATH training set. Crucially, this was achieved without the model ever seeing the hard problems; the system recovered the curriculum purely through the student progress reward signal.
--------------------------------------------------------------------------------
6. Decoupling Pedagogy from Solving: Analysis of Synthetic Questions
A core strategic insight of this research is that a model’s ability to teach (generate stepping stones) is distinct from its ability to solve the target hard problems. SOAR surfaces latent pedagogical signals that exist even in models that are ostensibly "stuck."
The Structure vs. Correctness Paradox
- Solution Correctness (32.8%): Only a minority of teacher-generated solutions were correct.
- Mathematical Well-Posedness (63%): Nearly two-thirds of the questions were mathematically coherent and structurally sound.
- Semantic Diversity: Using the Vendi Score (defined as the effective number of unique semantic concepts), Grounded-T (SOAR) maintained a score of 34.66, matching the base model and vastly exceeding the intrinsic baseline (10.82).
Error Taxonomy and Evolution
Analysis of Table 7 in the source data reveals that meta-RL specifically improves performance by reducing Ambiguity Errors relative to the base model. While Arithmetic Errors persisted, the conceptual alignment improved significantly. Qualitatively, the curriculum evolved from basic word problems and formulas in Stage 1 to concise, equation-heavy algebra and calculus in Stage 2 as the student baseline improved.
--------------------------------------------------------------------------------
7. Conclusion: Expanding the Frontier of Learnability
The SOAR framework provides a principled, autonomous path for models to escape reasoning plateaus. By shifting from intrinsic curiosity to grounded meta-RL, we have demonstrated that LLMs can discover the data they need to learn from without human intervention.
The broader implications for AGI development are profound. Our results suggest that for any complex problem—including "North Star" objectives like the Riemann Hypothesis—the intermediate lemmas and theorems required for a solution may already be latent in the model’s pretraining distribution. Grounded meta-RL serves as the retrieval mechanism that organizes this latent knowledge into a coherent pedagogical structure.
Ultimately, SOAR proves that a model’s pedagogical ability can be decoupled from its solving ability. Grounded meta-RL is strategically superior to traditional RLVF and curiosity-driven self-play, offering a stable, diversity-preserving method for models to independently expand their own reasoning frontiers.
