TiDAR: Think in Diffusion, Talk in Autoregression

🖥️ NVIDIA Research: How TiDAR Achieves 5.9x Speedup in LLMs
This post explores TiDAR, a new architecture from researchers at NVIDIA that solves one of the biggest bottlenecks in modern AI: speed.
By combining the "thinking" power of diffusion models with the "talking" precision of autoregressive generation, TiDAR allows AI to generate text nearly 6x faster without sacrificing quality. We dive into the "Single-Step Trick," how it maximizes GPU power, and why this marks a massive shift in how we interact with Artificial Intelligence. 🚀🤖
💡 What you’ll learn:
The Problem: Why current LLMs are like driving a Ferrari in first gear.
The Tech: How TiDAR "proofreads the present" while "drafting the future."
The Results: Real-world benchmarks showing massive efficiency gains on 1.5B and 8B parameter models.
An Explainer Video:
TiDAR: Think in Diffusion, Talk in Autoregression
https://arxiv.org/pdf/2511.08923
Jingyu Liu 1, Xin Dong 1, Zhifan Ye 2, Rishabh Mehta, Yonggan Fu, Vartika Singh, Jan Kautz, Ce Zhang1, Pavlo Molchanov
NVIDIA
A Gentle Slide Deck:
Let's Dive In...
1.0 Introduction: The Dilemma of LLM Inference
The deployment of modern Large Language Models (LLMs) is governed by a fundamental trade-off between generation quality and computational efficiency. This document introduces TiDAR, a novel architecture engineered to resolve this conflict by synergizing the strengths of the two dominant generation paradigms.
Currently, the field is defined by two primary approaches: Autoregressive (AR) models and Diffusion Language Models (dLMs). AR models, the prevailing standard for high-quality text generation, produce outputs one token at a time. This sequential process, while effective, results in severe inefficiency, as it fails to leverage the massive parallel processing capabilities of modern GPU hardware. Consequently, powerful accelerators are often left underutilized. In contrast, dLMs were developed to address this inefficiency by generating multiple tokens in parallel. However, the decision to implement this parallelization created its own trade-off, as the underlying assumption of token independence within a generation step often degrades sequence-level coherence and overall quality.
Other methods, such as speculative decoding, have been proposed to accelerate AR models. However, their effectiveness is often limited by the reliance on separate, weaker draft models and a sequential drafting process that fails to fully exploit hardware parallelism. The decision to implement these methods introduces architectural complexity without solving the core issue of underutilization.
The critical need to overcome these limitations motivates a new approach. TiDAR introduces a sequence-level hybrid architecture that integrates the core strengths of both autoregression and diffusion. It achieves AR-level quality with the efficiency of parallel generation by executing both processes—parallel drafting and autoregressive verification—within a single model and a single forward pass.
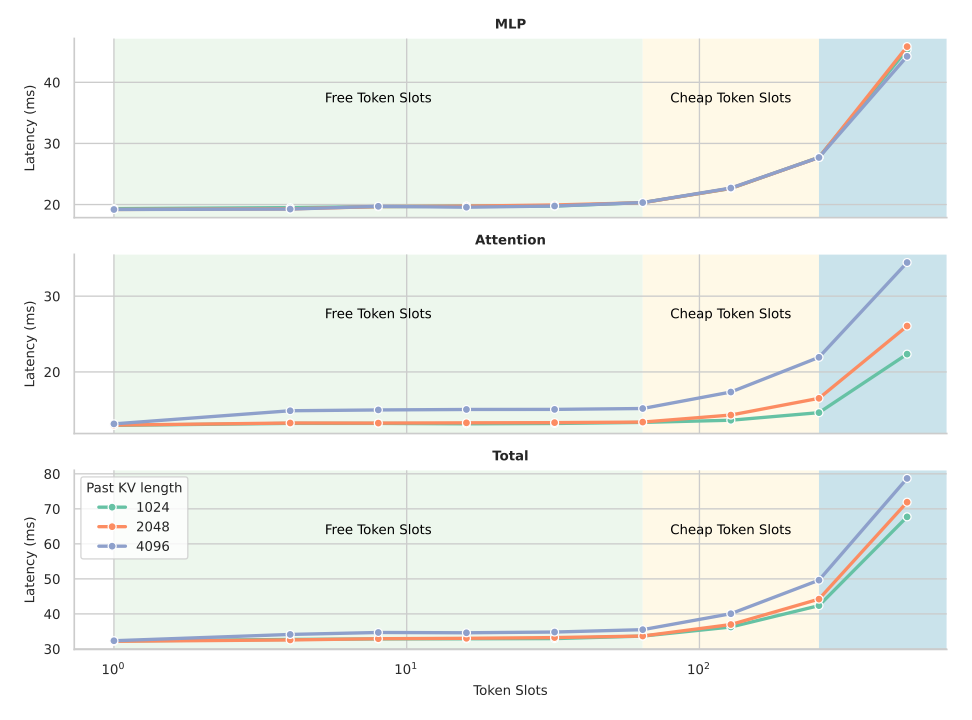
2.0 Unpacking the GPU Efficiency Challenge
Maximizing GPU utilization is a strategic imperative for cost-effective and low-latency LLM inference. The performance of any generation method is directly tied to its ability to harness the full computational power of the underlying hardware. This section deconstructs the specific bottlenecks in existing approaches that prevent the full exploitation of modern accelerators, arguing for the architectural inevitability of a new design paradigm.
2.1 The Autoregressive Bottleneck and Untapped Potential
Autoregressive decoding is fundamentally constrained not by a lack of computational power, but by memory bandwidth. The process is considered memory-bound because end-to-end latency is dominated by the time required to load the model's weights and the Key-Value (KV) cache from memory, rather than the time spent on mathematical computations. Since only a single token is generated per forward pass, the vast computational resources of the GPU remain largely idle.
Analysis of GPU performance profiles reveals the existence of "free token slots"—a significant amount of untapped computational capacity (see Figure 1). These slots represent the ability to process a batch of additional tokens in a single forward pass with a minimal, often negligible, increase in overall latency. By failing to utilize these slots, traditional AR models leave substantial performance gains on the table.
2.2 Limitations of Parallel Generation Approaches
Parallel generation methods were developed to address the AR bottleneck, but they introduce their own set of limitations that have, until now, been considered unavoidable.
- Diffusion Language Models (dLMs): The core challenge for dLMs is the token independence assumption made during parallel decoding. By generating multiple tokens simultaneously without full context of each other, dLMs struggle to maintain the sequence-level coherence that AR models naturally preserve. This results in a direct trade-off where increased parallelism leads to degraded output quality.
- Speculative Decoding: While an improvement over standard AR decoding, speculative decoding methods are constrained by their architecture. The process is typically sequential, involving separate forward passes for drafting and verification. Furthermore, the use of lower-capacity draft models can limit the quality of proposed sequences, thereby reducing the acceptance rate and capping the maximum potential speedup.
These persistent challenges highlight a clear architectural need for a new approach that can process multiple tokens in parallel without sacrificing quality or introducing multi-step inefficiencies, setting the stage for TiDAR's design.
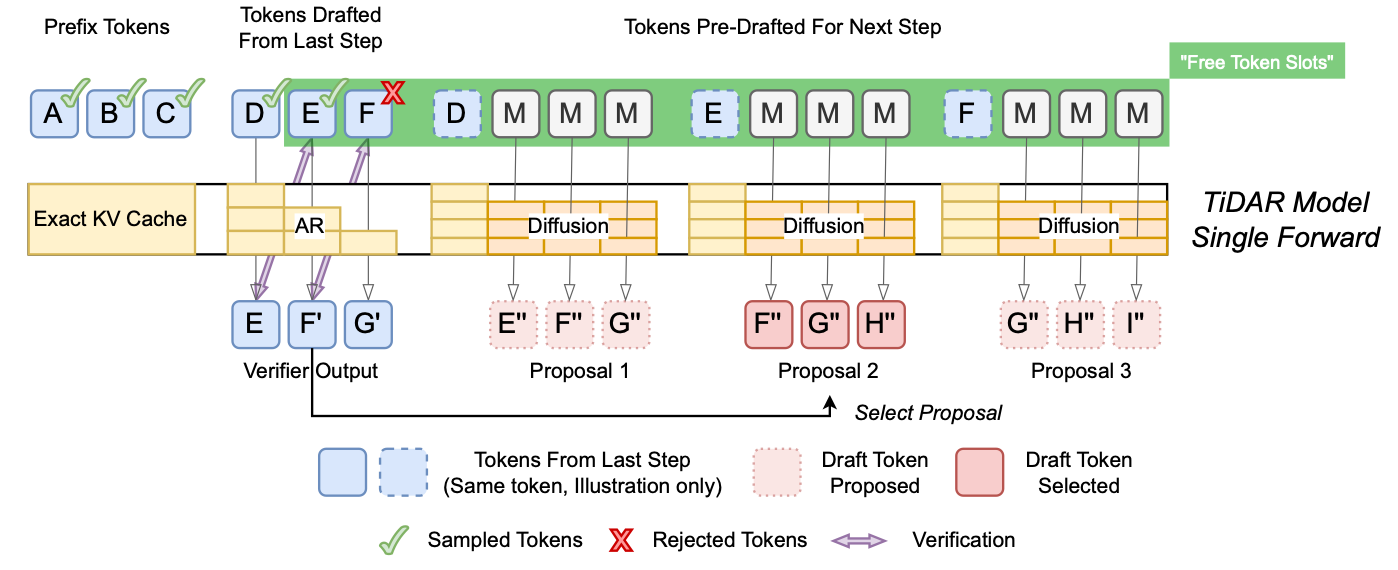
3.0 The TiDAR Architecture: Bridging Diffusion and Autoregression
The TiDAR architecture represents a fundamental shift in model design, moving beyond the trade-offs of existing paradigms. This section details its core principles, from its hybrid attention mechanism to its unique training strategy, which enable it to perform parallel drafting and high-quality verification simultaneously.
3.1 Core Principle: Think in Diffusion, Talk in Autoregression
The central concept behind TiDAR is to enable the model to "Think" in parallel using a diffusion-based mechanism and "Talk" with high fidelity using an autoregressive sampling process. The decision to implement this entire workflow—drafting a new set of candidate tokens and verifying the previously drafted set—within a single forward pass is critical for overcoming the limitations of conventional approaches.
As depicted in the inference process, each generation step simultaneously performs two critical functions. First, it verifies previously drafted tokens using autoregressive rejection sampling to ensure high quality. Second, it generates new draft proposals for the next step in parallel. This concurrent operation allows TiDAR to fully utilize the GPU's "free token slots," converting idle compute capacity into a direct performance gain.
3.2 The Structured Attention Mask: Enabling Dual-Mode Operation
The key to TiDAR's dual functionality is a specially designed structured attention mask that dynamically changes the model's behavior across different parts of the input sequence. This mask effectively partitions the input into three distinct components, each processed with a specific attention mechanism:
- Prefix tokens: These are the already accepted tokens forming the context. They are processed with standard causal attention, operating in a conventional autoregressive mode.
- Previously drafted tokens: These are the candidate tokens from the previous step that are currently being verified. The model calculates their probabilities using causal attention to enable high-fidelity rejection sampling.
- Pre-drafted tokens for the next step: These are special mask tokens where new candidates are generated. They are processed with bidirectional attention, allowing the model to operate in a parallel, diffusion-like mode.
This partitioned mask is the central mechanism that enables a single model, within a single computational graph, to simultaneously compute the chain-factorized joint distribution essential for high-fidelity autoregressive verification and the marginal distributions required for efficient parallel drafting.
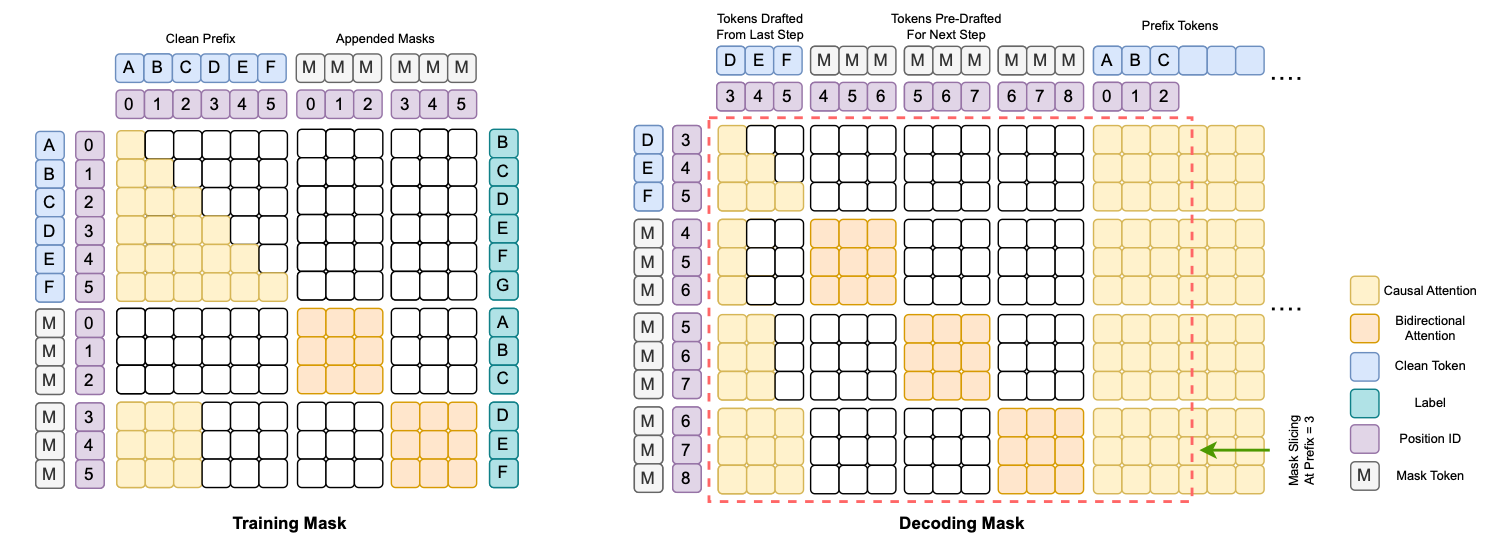
3.3 A Simplified and Effective Training Strategy
TiDAR rejects the complexity of traditional dLM noise schedules in favor of an elegant and highly effective "full masking strategy." During training, all tokens in the diffusion section of the input are replaced with mask tokens. This approach creates a clean, consistent training objective that combines autoregressive and diffusion cross-entropy losses:
L_{total} = \alpha \cdot L_{AR} + (1-\alpha) \cdot L_{diffusion}
where α = 1 is typically used. Critically, this full masking approach directly enables the efficient, one-step diffusion process used during inference for drafting, streamlining the train-to-inference pipeline.
This strategy delivers three significant benefits:
- Eliminates Complexity: It removes the need for engineers to design and tune optimal masking strategies or noise schedules.
- Denser Loss Signals: By masking all tokens in the diffusion segment, it creates a stronger and more consistent diffusion loss signal, leading to more effective training.
- Simplified Loss Balancing: The consistent structure of the losses makes the balancing factor α straightforward to manage.
This combination of a hybrid attention mask and a simplified training objective produces a powerful model capable of high-performance, dual-mode inference.
4.0 Key Technical Innovations
TiDAR's performance is not just the result of a conceptual breakthrough but a series of deliberate technical innovations. These design choices are engineered to convert the theoretical advantages of its hybrid architecture into tangible, wall-clock speed improvements during inference. They represent the necessary prerequisites for the performance breakthroughs detailed in the next section.
4.1 Exploiting Free Token Slots for Near-Zero Cost Drafting
The cornerstone of TiDAR's efficiency is its ability to strategically utilize the "free token slots" inherent in modern GPU operations. The decision to implement a single-pass design for drafting and verification is critical for fitting the processing of multiple tokens within the latency envelope of a single token in a memory-bound AR model. This innovation leads to "almost free parallelized drafting and sampling," as the additional computational work incurs a minimal latency penalty. TiDAR maximizes compute density, ensuring the GPU's resources are actively engaged.
4.2 Single Forward Pass Design
TiDAR's ability to perform drafting and verification simultaneously in one forward pass is a critical differentiator. This stands in stark contrast to speculative decoding methods, which operate sequentially, requiring separate forward passes for the draft and base models. By collapsing these operations into a single step, TiDAR eliminates the overhead of multi-pass communication and directly translates its computational efficiency into a measurable reduction in end-to-end latency.
4.3 Exact KV Cache Support for Maximum Efficiency
Unlike many dLMs that struggle with efficient caching due to their bidirectional nature, TiDAR is designed with exact KV cache support, mirroring the efficiency of standard AR models. During inference, the KV cache for all potentially valid tokens is computed. If a drafted token is rejected, its corresponding KV cache entry is simply and efficiently evicted. This mechanism prevents computational waste and distinguishes TiDAR from other parallel decoding methods that employ less efficient or approximate caching strategies.
These technical innovations work in concert to create a highly optimized architecture that is demonstrably efficient in practice.
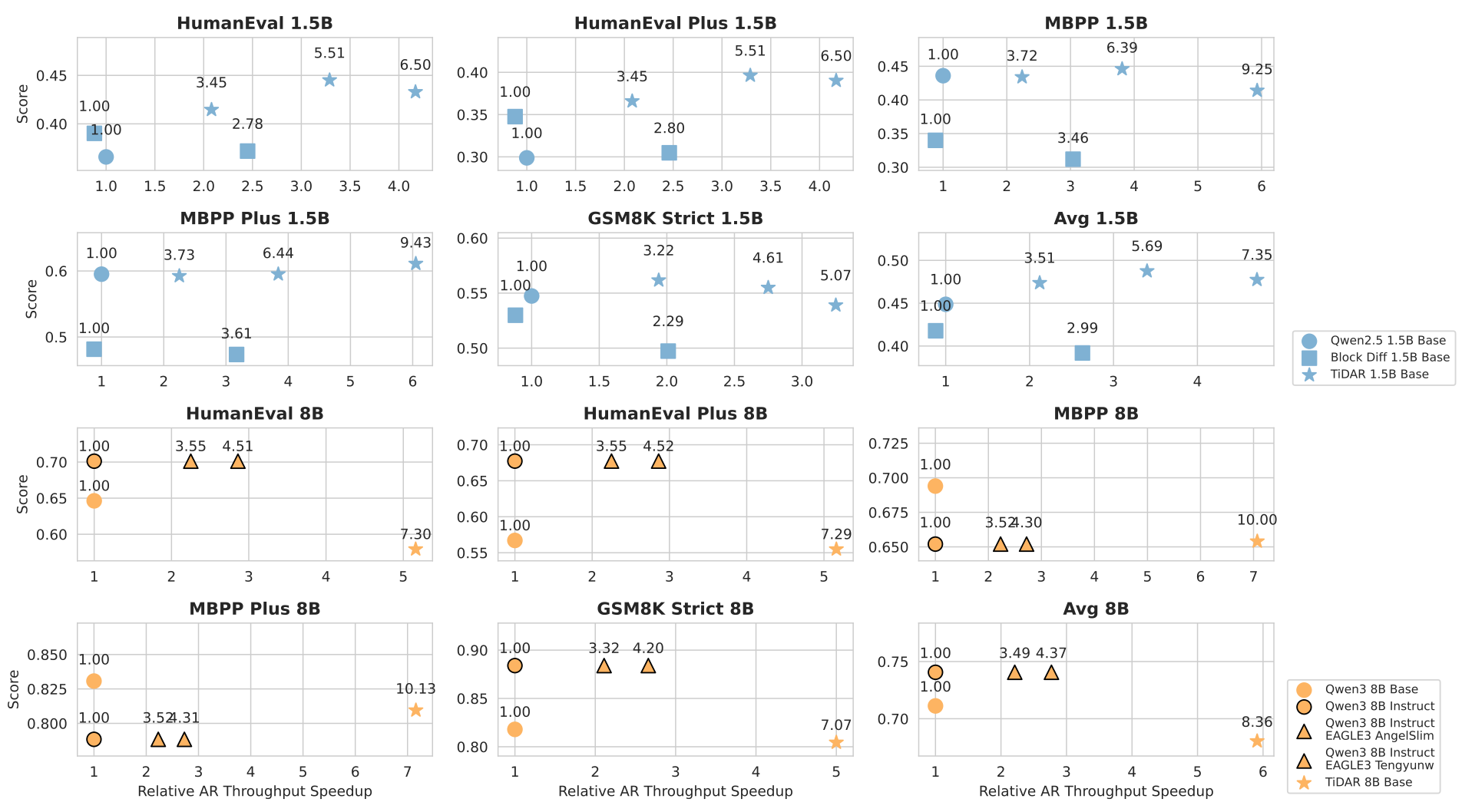
5.0 Performance Benchmarking: A New Pareto Frontier
Empirical evidence confirms that TiDAR establishes a new state-of-the-art in the trade-off between inference speed and generation quality. The following benchmarks demonstrate TiDAR's superior performance in throughput, its ability to maintain high-quality outputs, and its clear advantages when compared against leading alternative methods.
5.1 Efficiency and Throughput Gains
TiDAR delivers substantial throughput improvements over baseline AR models by generating multiple tokens for each network function evaluation (NFE). The efficiency scales with model size, highlighting the architecture's effectiveness.
Model Size | Performance Metrics |
1.5B Model | - 7.45 tokens per NFE<br>- 4.71x relative throughput speedup |
8B Model | - 8.25 tokens per NFE<br>- 5.91x relative throughput speedup |
5.2 Generation and Likelihood Quality
TiDAR achieves its speed improvements without a significant compromise in quality.
- Generative Tasks: On complex generative benchmarks for coding and math, the TiDAR 1.5B model achieves lossless quality compared to its AR counterpart (Qwen2.5 1.5B). The 8B model demonstrates only minimal quality degradation while delivering a nearly 6x speedup.
- Likelihood Tasks: TiDAR possesses a unique advantage in likelihood evaluation. Because its architecture includes a true autoregressive mode, it can compute likelihoods identically to standard AR models. This contrasts sharply with traditional dLMs, which require complex and less comparable Monte Carlo sampling methods. As a result, TiDAR 8B achieves a competitive average score of 75.40% across factual knowledge and commonsense reasoning benchmarks, directly comparable to base AR models.
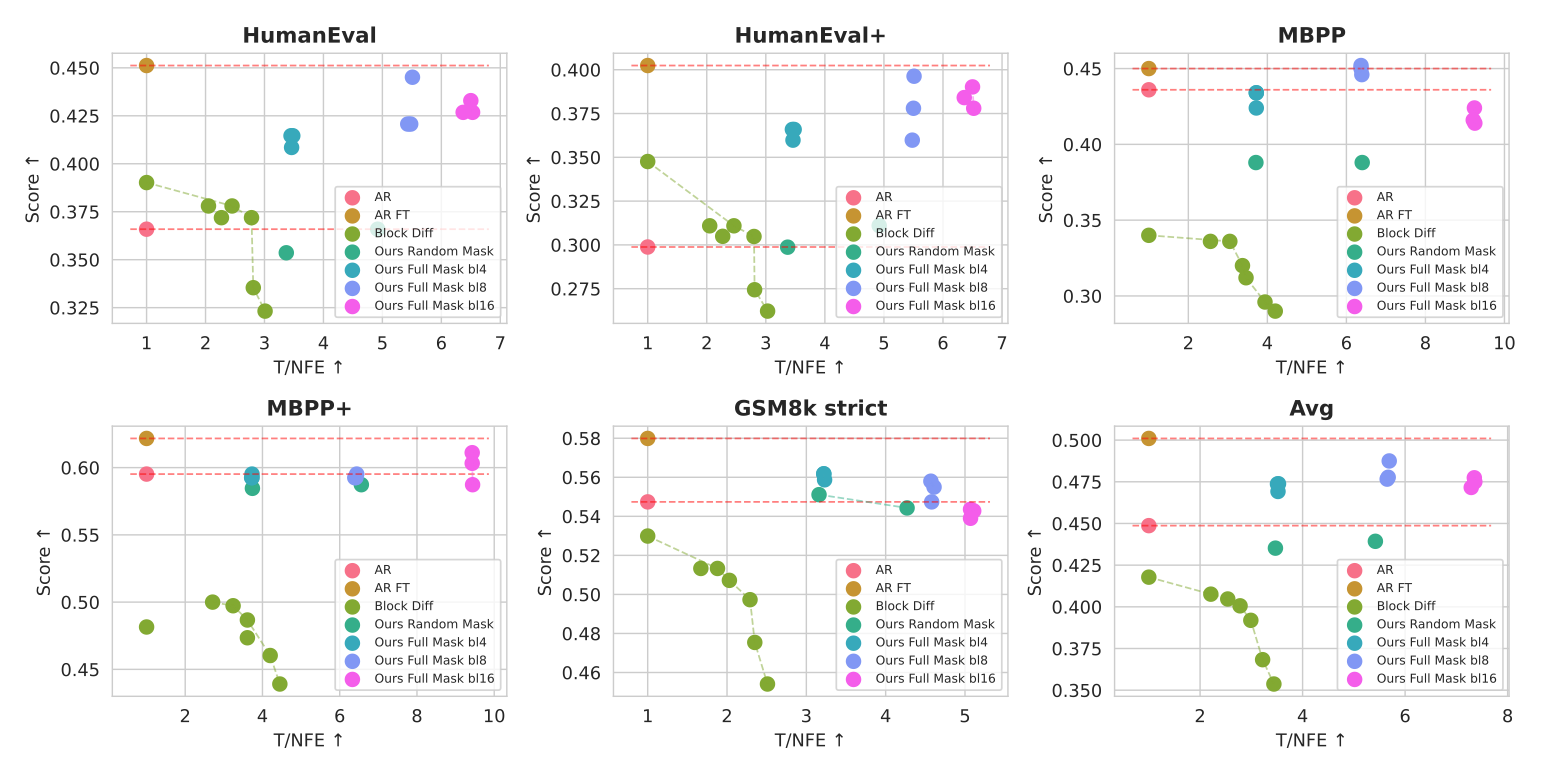
5.3 Comparative Analysis Against Competing Methods
When benchmarked against a range of alternative methods, TiDAR consistently establishes a superior efficiency-quality trade-off. Evaluations show that TiDAR outperforms leading diffusion models like Dream and Llada, internal Block Diffusion baselines, and state-of-the-art speculative decoding methods such as EAGLE-3. On Pareto frontier analyses, which plot quality against efficiency, TiDAR consistently occupies a more favorable position.
To validate the architectural decisions responsible for these results, a series of comprehensive ablation studies were conducted.
6.0 Validation and Analysis
The robustness of an architecture is best understood by validating its core design principles. The ablation studies conducted on TiDAR confirm the efficacy of its key components and demonstrate that its performance is a direct result of its intentional design.
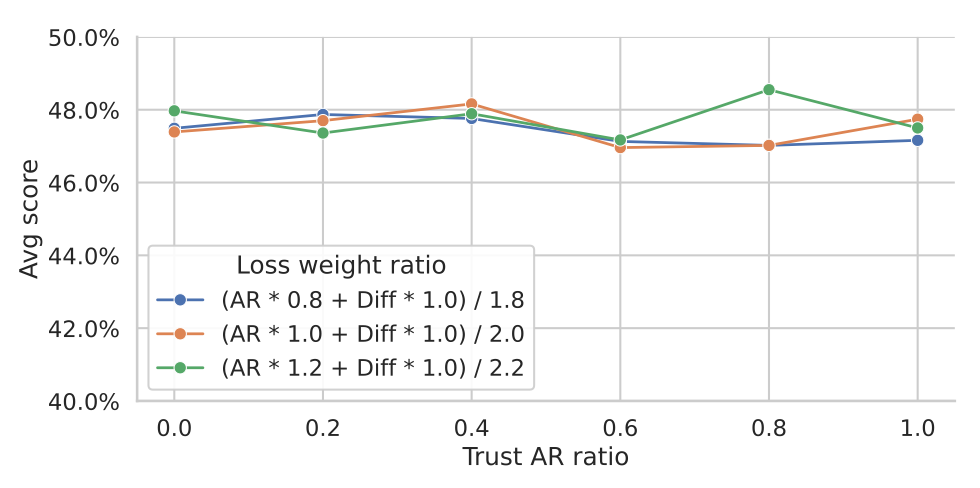
6.1 Robustness Across Verification Strategies
A "Trust Ratio" study was performed to analyze the model's stability when verifying tokens. This involved mixing the logits from the autoregressive (AR) and diffusion components in different proportions during the verification step. The results show that TiDAR demonstrates remarkable performance stability regardless of this ratio.
This remarkable stability is a direct validation of the 'full masking' training strategy. By providing denser loss signals, the training produces a diffusion component so proficient at drafting that the final verification method is inconsequential to the outcome, proving the quality of the proposals before they are even verified. The autoregressive rejection sampling framework acts as a reliable safeguard, but the high quality of the initial drafts is what makes the high acceptance rates and speedups possible.
6.2 Efficacy of the Full Masking Strategy
Ablation studies also confirmed the benefits of the simplified "full masking" training strategy. Compared to approaches using more complex random masking, the full masking method was shown to be superior. Its key advantages include:
- It consistently improves both efficiency (higher Tokens per NFE) and generation quality, particularly on coding benchmarks.
- It reduces the train-test discrepancy by aligning the training objective more closely with the one-step diffusion process used during inference.
- It provides denser diffusion loss signals, contributing to a more robust and effective training cycle.
These validated design choices culminate in an architecture that is not only powerful in its final form but also built on a foundation of sound, empirically-tested principles.
7.0 Conclusion and Future Implications
TiDAR successfully resolves the long-standing conflict between speed and quality in LLM inference. By creating a unified architecture that harmonizes the parallel efficiency of diffusion models with the generative fidelity of autoregressive models, TiDAR establishes a new benchmark for high-performance language generation.
7.1 Summary of Contributions
TiDAR's primary contributions represent a significant advancement for the field:
- A Unified Hybrid Architecture: Successfully bridges autoregressive quality and diffusion efficiency within a single, standalone model, eliminating architectural complexity.
- State-of-the-Art Performance: Achieves significant throughput speedups of 4.71x to 5.91x over comparable AR baselines while maintaining competitive, near-lossless generation quality.
- Superior GPU Utilization: Maximizes compute density by strategically exploiting the "free token slots" available on modern accelerators, turning idle capacity into performance.
- Serving-Friendly Design: Designed for practical deployment, eliminating the need for separate draft models, complex inference hyperparameters, and inefficient caching schemes.
7.2 Future Directions
The success of the TiDAR architecture opens several promising avenues for future research and development. Key areas for exploration include:
- Exploration of new hybrid architectures that further integrate or expand upon the dual-mode paradigm.
- Development of specialized, hardware-aware inference kernels designed to maximize the utilization of "free token slots" on specific hardware platforms.
- Extension of the architecture to handle longer context scenarios efficiently.
Ultimately, TiDAR's approach suggests that the thoughtful integration of different generation paradigms within unified architectures is a key pathway toward building the next generation of powerful, efficient, and accessible language models.
fin...